3.2 解析XML文档
要处理XML文档,就要先解析(parse)它。解析器是这样一个程序:它读入一个文件,确认这个文件具有正确的格式,然后将其分解成各种元素,使得程序员能够访问这些元素。Java库提供了两种XML解析器:
- 像文档对象模型(Document Object Model, DOM)解析器这样的树型解析器(tree parser),它们将读入的XML文档转换成树结构。
- 像XML简单API(Simple API for XML, SAX)解析器这样的流机制解析器(streaming parser),它们在读入XML文档时生成相应的事件。
DOM解析器对于实现我们的大多数目的来说都更容易一些,所以我们首先介绍它。如果你要处理很长的文档,用它生成树结构将会消耗大量内存,或者如果你只是对于某些元素感兴趣,而不关心它们的上下文,那么在这些情况下你应该考虑使用流机制解析器。更多的信息可以查看3.6节。
DOM解析器的接口已经被W3C标准化了。org.w3c.dom包中包含了这些接口类型的定义,比如:Document和Element等。不同的提供者,比如Apache组织和IBM,都编写了实现这些接口的DOM解析器。Java XML处理API (Java API for XML Processing, JAXP)库使得我们实际上可以以插件形式使用这些解析器中的任意一个。但是JDK中也包含了从Apache解析器导出的DOM解析器。
要读入一个XML文档,首先需要一个DocumentBuilder对象,可以从DocumentBuilder Factory中得到这个对象,例如:
注意:如果使用输入流作为输入源,那么对于那些以该文档的位置为相对路径而被引用的文档,解析器将无法定位,比如在同一个目录中的DTD。但是,可以通过安装一个“实体解析器”(entity resolver)来解决这个问题。请查看www.xml.com/pub/a/2004/03/03/catalogs.html或www.ibm.com/developerworks/xml/library/x-mxd3.html,以了解更多信息。
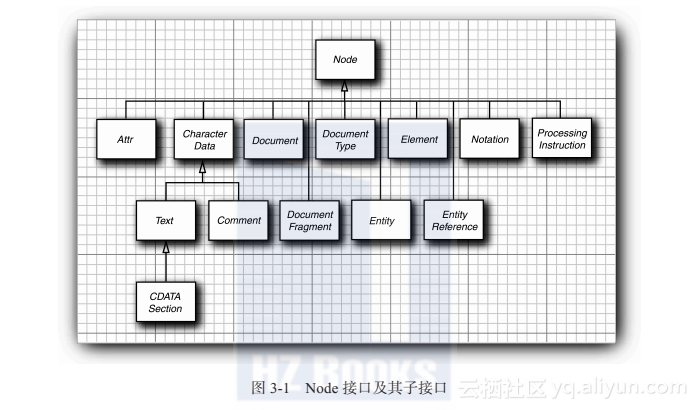
Document对象是XML文档的树型结构在内存中的表示方式,它由实现了Node接口及其各种子接口的类的对象构成。图3-1显示了各个子接口的层次结构。
可以通过调用getDocumentElement方法来启动对文档内容的分析,它将返回根元素。
那么,调用getDocumentElement方法可以返回font元素。getTagName方法可以返回元素的标签名。在前面这个例子中,root.getTagName()返回字符串"font"。
如果要得到该元素的子元素(可能是子元素、文本、注释或其他节点),请使用getChildNodes方法,这个方法会返回一个类型为NodeList的集合。这个类型在标准的Java集合类创建之前就已经被标准化了,因此它具有一种不同的访问协议;item方法将得到指定索引值的项;getLength方法则提供了项的总数。因此,我们可以像下面这样枚举所有子元素: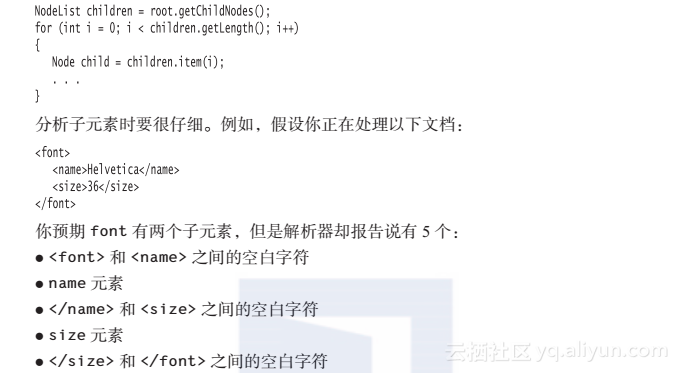
图3-2显示了其DOM树。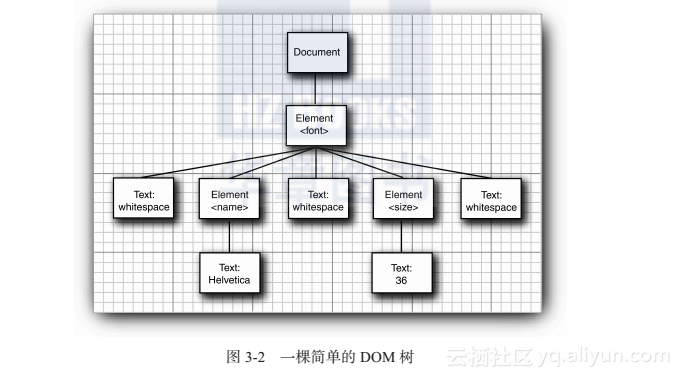
如果只希望得到子元素,那么可以忽略空白字符:

现在,只会看到两个元素,它们的标签名是name和size。
正如将在下一节中所看到的那样,如果你的文档有DTD,那么你就可以做得更好。这时,解析器知道哪些元素没有文本节点的子元素,而且它会帮你剔除空白字符。
在分析name和size元素时,你肯定想获取它们包含的文本字符串。这些文本字符串本身都包含在Text类型的子节点中。既然知道了这些Text节点是唯一的子元素,就可以用getFirstChild方法而不用再遍历另一个NodeList。然后可以用getData方法获取存储在Text节点中的字符串。
提示:对getData的返回值调用trim方法是个好主意。如果XML文件的作者将起始和结束的标签放在不同的行上,例如:
那么,解析器将会把所有的换行符和空格都包含到文本节点中去。调用trim方法可以把位于实际数据前后的空白字符删掉。
也可以用getLastChild方法得到最后一项子元素,用getNextSibling得到下一个兄弟节点。这样,另一种遍历子节点集的方法就是:
如果要枚举节点的属性,可以调用getAttributes方法。它返回一个NamedNodeMap对象,其中包含了描述属性的Node对象。可以用和遍历NodeList一样的方式在NamedNodeMap中遍历各子节点。然后,调用getNodeName和getNodeValue方法可以得到属性名和属性值。
或者,如果知道属性名,则可以直接获取相应的属性值:
现在你已经知道怎么分析DOM树了。程序清单3-1中的程序将这些技术都运用了一遍。你可以使用File -> Open菜单选项来读入一个XML文件。DocumentBuilder对象会解析这个XML文件,并产生一个Document对象。该程序会将Document对象显示为一个JTree(参见图3-3)。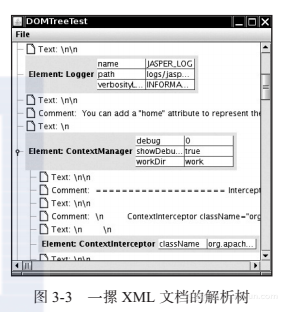
该树形结构清楚地显示了子元素是怎样被包含空白字符和注释的文本包围起来的。为了更清楚起见,这个程序将换行和回车字符显示为\n和\r。(否则,它们将显示为空框,这是Swing对字符串中不能绘制的字符显示的默认符号)。
在第10章你将会学习到该程序中用来显示树形结构和属性表的技术。DOMTreeModel类实现了TreeModel接口。getRoot方法会返回文档的根元素,getChild方法可以得到子元素的节点列表,返回被请求的索引值对应的项。表的单元格渲染器显示了以下内容:
- 对元素,显示的是元素标签名和由所有的属性构成的一张表。
- 对字符数据,显示的是接口(Text、Comment、CDATASection),后面跟着数据,其中换行和回车字符被\n和\r取代。
- 对其他所有的节点类型,显示的是类名,后面跟着toString的结果。
程序清单3-1 dom/Treeviewer.java











