2.3 Hadoop MapReduce原理
为了更好地理解MapReduce的工作原理,我们将会:
学习MapReduce对象。
MapReduce中实现Map阶段的执行单元数目。
MapReduce中实现Reduce阶段的执行单元数目。
理解MapReduce的数据流。
深入理解Hadoop MapReduce。
2.3.1 MapReduce对象
由Hadoop的MapReduce技术可以引申出如下3个主要对象:
Mapper:它主要用于实现MapReduce的Map阶段的操作。该对象在MapReduce读取完输入数据并完成数据分割后开始运行。每个分割后的切片数据都会以键值对数据的形式输出。
Reducer:它主要用于实现MapReduce的Reduce阶段的操作。它接收Map阶段的输出数据,该数据以键为基础进行分组。Reduce的聚集逻辑接收到Map输出数据后产生(key, value)格式的键值对数据,以作为每个分组的数值。
Driver:这是驱动MapReduce进程的主要文件。当Driver接收到client应用程序传递的参数后,Driver会启动MapReduce进程开始执行。Driver文件负责建立job的配置工作,并把配置信息提交给Hadoop集群。Driver的代码中会包含main()方法,该方法用于接收命令行的参数。在该指令中,会读取Hadoop MapReduce job的输入输出目录。Driver是定义job配置细节信息的主要文件。例如job名称、job的输入格式、job的输出格式以及Mapper、Combiner、Partitioner和Reducer类。通过调用Driver类的main()函数初始化MapReduce操作。
不是所有问题都能通过只包含单一Map和Reduce的程序来解决,甚至不能通过只包含单一Map和Reduce的任务来解决。有时候需要设计带有多个Map和Reduce执行单元任务的 MapReduce job。当需要完成诸如数据提取、数据清洗、数据合并这类的数据操作时,可以设计这样类型job,以便于这类操作可以在一个的job中完成。很多问题都可以通过在一个job中编写多个Map和Reduce任务得以解决。MapReduce以如下顺序执行多个Map和Reduce任务:Map1->Reduce1->Map2->Reduce2->以此类推。
当需要为一个MapReduce job写入多个Map和Reduce任务时,必须编写多个MapReduce应用程序的Driver,并顺序的运行它们。
当提交MapReduce job时,我们可以提供Map任务的数目,然后依据Map阶段的输出和Hadoop的聚集性能来创建Reduce执行单元的数目。注意设置Map和Reduce执行单元数目并非是强制要求的。
2.3.2 MapReduce中实现Map阶段的执行单元数目
Map执行单元的数目通常是由输入数据大小以及HDFS文件系统中的数据块单元大小决定的。因此,如果在HDFS中某个数据文件大小为5TB( 5TB=5×220MB ),并且配置的HDFS数据块单元的大小为128MB,则该文件中将会存在40960(=5×220/128)个Map执行单元。不过有时候会比该计算结果的数目更多,这是因为一些需要额外的预测执行(speculative execution)程序。当输入数据是一个文件时,依据InputFormat类也是这样的。
在Hadoop MapReduce进程中,如果分配Map和Reduce执行单元需要耗时很久时,那么在执行job获取输出结果时会产生延迟。如果想避免这种现象,Hadoop的预测执行(speculative execution)程序就会把相同的Map和Reduce任务复制到多个不同节点中处理,并且选取最先完成运算节点的输出作为结果使用。使用Hadoop接口中的setNumMapTasks(int) 方法,我们可以获取Map执行单元数目。
2.3.3 MapReduce中实现Reduce阶段的执行单元数目
Reduce执行单元数目依据Map执行单元的输入数据。然而,如果在MapReduce中强制配置了Reduce执行单元的个数,那么将不再考虑集群中的节点数目,系统会依据配置信息来执行。
此外,我们也可以通过MapReduce命令行中键入 -D mapred.reduce.tasks命令来配置需要的数目。在程序中,可以通过设置conf.setNumReduceTasks(int)来完成。
2.3.4 MapReduce的数据流
目前为止,已经学习了运行MapReduce job的基础概念,现在要研究它们是如何高效的组合在一起完成系统运行的。根据下图,我们可以理解在Hadoop集群内包含多个节点时MapReduce的数据流动情况。
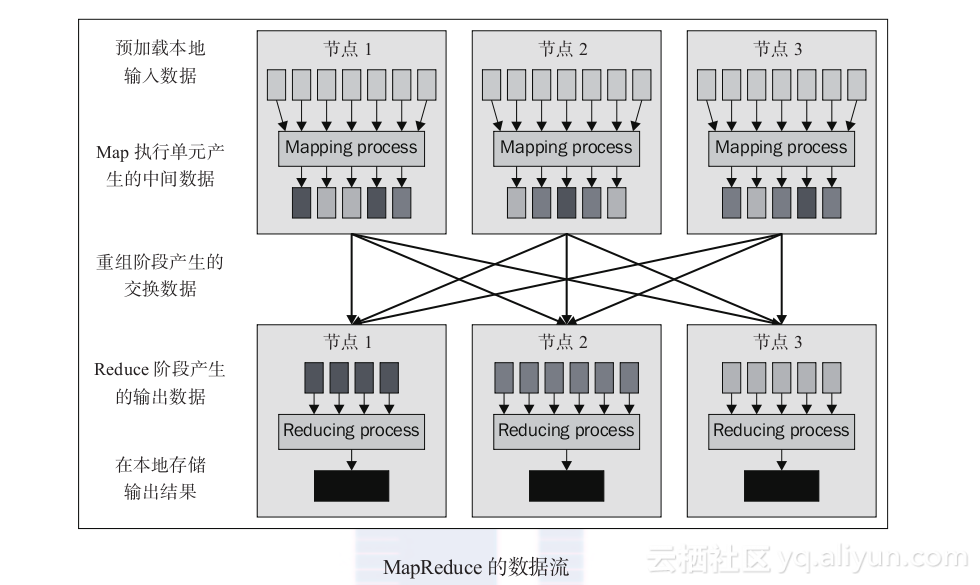
Hadoop MapReduce内有两套可用的API接口:新版本接口(Hadoop 1.x和2.x版本)以及旧版本接口(Hadoop 0.20版本)。YARN是Hadoop MapReduce的新一代框架,使用新的Apache Hadoop项目来进行Hadoop资源管理。
Hadoop的数据处理进程包括多个任务,这些任务可以帮助在输入数据集中得到最终的输出数据。主要包括:
1. 预载入数据到HDFS中。
2. 通过调用Driver来运行MapReduce。
3. Map输入数据的读取。该任务会把数据进行分割并执行Map内部的逻辑,最后生成中间阶段的键值对数据。
4. 执行合并(Combiner)和重组(Shuffle)阶段主要用于优化Hadoop MapReduce进程。
5. 排序(Sorting)并提供中间数据(键值对数据)给Reduce阶段作为输入。然后执行Reduce阶段的程序。Reduce执行单元处理这些分割的键值对数据,并依据Reduce内的函数逻辑对该数据进行聚集(aggregate)。
6. 最后把排序后的最终数据存储于HDFS文件系统中。
这里,Map和reduce任务可以被定义为如下数据操作:
数据提取(Data extraction)
数据载入(Data loading)
数据分割(Data segmentation)
数据清洗(Data cleaning)
数据转换(Data transformation)
数据整合(Data integration)
在本章接下来的部分,我们会更深入的探究MapReduce任务。
2.3.5 深入理解HadoopMapReduce
本节,我们会更深入了解Hadoop MapReduce数据流中提及的几个术语,以及他们的Java类细节。上一章提及的MapReduce数据流示例图中,多个节点通过网络汇集在一块,以便分布式运行Hadoop的启动程序。接着Map和Reduce的属性为最终的数据输出起了重要的作用。
Map阶段中涉及的属性包括如下:
InputFiles用于指定输入数据,该数据主要是从分析数据中创建或提取的行格式数据集,并最终存储于HDFS文件系统中。这些输入文件非常大,并包括多种数据类型。
InputFormat类用于提取输入文件中每行的内容。它定义了如何分割并读取输入数据文件。我们可以设置这些输入数据的类型,例如TextInputFormat、KeyValueInputFormat以及SequenceFileInputFormat,它同Map和reduce阶段的处理有直接关系。
InputSplits类用于设置每个数据片的大小。
RecordReader类提供了多个方法用于在数据片中进行声明,以便于恢复key键值和value值的匹配关系。同时它也包括了用于获取当前进程状态的其他方法。
Mapper实例在Map阶段中建立。Mapper类的输入为(key,value)键值对数据(由RecordReader产生)。输出数据的格式为(key, value),该数据的产生由内部的Map方法来用户自定义实现。Map方法主要包括2个输入参数:key和value;余下的参数是OutputCollector和Reporter。
其中OutputCollector参数用于为reduce阶段提供输入的key-value中间键值对数据。Reporter用于提供当前job所处的状态,该状态会被周期性的发送给JobTracker。JobTracker将会聚集它们以便后续恢复已经结束的job。
Reduce阶段中涉及的属性包括如下:
当完成Map阶段的计算后,生成的(key, value)键值对数据会依据hash函数的key参数的相关度被分割。所以每个Map任务均会生成(key, value)键值对数据,并交给partition分割模块处理。所有具有相同key键值的数据均会合并在一块(此时不再考虑该数据原来属于哪个Map执行单元)。当完成Map阶段的计算后,分割和重组模块将会被MapReduce job自动完成。没有必要再去调用它们。同时,我们也可以根据每个MapReduce job的需要,重载编写重组时的逻辑代码。
当完成分割和重组工作后,初始化Reduce任务之前,(key, value)键值对数据会依据key值被重排序。
Reduce实例在Reduce阶段建立,处理Reduce任务的内部逻辑由用户自定义代码实现。Reduce类中的Reduce方法主要包括OutputCollector 和Reporter两个参数,它与Map函数中的OutputCollector 和Reporter参数类似。其中OutputCollector参数在Map和Reduce阶段有相同的功能性,只是在Reduce阶段OutputCollector既可以提供给下一个Map阶段处理(当有多个Map和Reduce job组合时)也可以作为job的最终输出。此外Reporter会周期性的向JobTracker汇报运行中任务的状态。
最后在OutputFormat中,产生的(key, value)输出键值对数据提供给OutputCollector
参数,并写入到OutputFiles中。根据MapReduce Driver的定义,OutputFormat设定OutputFiles的格式。可设定的格式包括:TextOutputFormat、SequenceFileOutputFileFormat或NullOutputFormat。
OutputFormat使用工厂设计模式RecordWriter把输出数据写成适当的格式。
当完成所有MapReduce job的计算工作后,输出数据以文件的形式通过RecordWriter写入HDFS中。
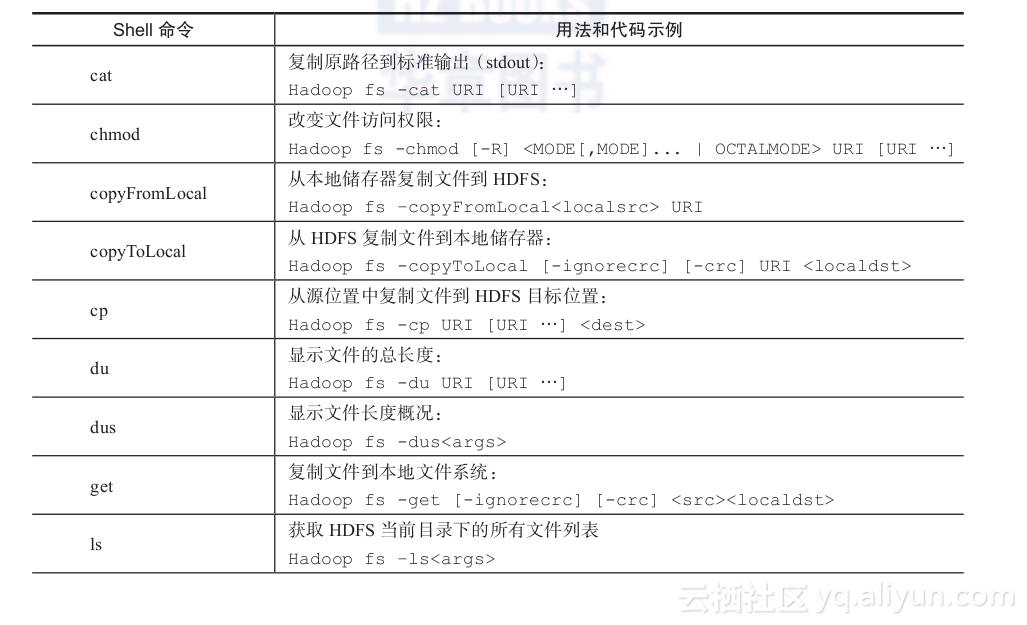
为了高效运行MapReduce job,需要具备一些Hadoop shell命令下执行管理任务的知识。请参考如下表格: