如今,地理大数据产业在中国方兴未艾。通过地理大数据为企业提供决策服务的GeoHey,是其中的代表。如何寻找并发掘地理大数据的价值。我们请来GeoHey的数据总监高楠,分享了他对地理大数据这座金矿的“掘金秘籍”。
如何获取“无处不在”的地理大数据?
我们先来说说如何获取和清洗地理大数据。
作为一个互联网用户,你是否会留意到不少手机应用在启动时会向你发出获得个人位置定位的请求?比如,你在马路上打开喜马拉雅的FM广播听个相声,边走边听的时候你的位置数据便被不断采集起来,这些被采集的位置数据,便是地理数据,也是值得挖掘的对象。另外,现实中的地理单位,比如一条马路,一栋房屋,它们也是一个个地理数据,可以被采集。
当我们把这些搜集起来的数据赋予维度并交叉应用时,便产生了它的应用价值。

既然位置数据来源于互联网,那么我们就去互联网上爬。
我们将这个过程设定为四个步骤:首先是开发爬虫,我们会开发挖掘数据的爬虫程序,这是我们的核心工具;在爬虫程序设定之后,我们便设定策略,确定要抓取哪一方面的数据,这也是我们的关键环节;在策略设定好之后,我们便设定生产排程,说通俗点就是排好工期;最后获得到我们想要的数据。
正如淘金需要过滤泥沙一样,我们获取到的数据其实有很多“废渣”,会影响整体价值。清洗数据和获取数据也是同样重要。按照上述这套流程下来,我们的系统不仅可以获得数据,还可以清洗数据。
要做到数据去重和清洗,首先要保证数据的获取量足够大。此外,还对数据来源进行评估,保证数据来源的“干净”。
我们是一个仅16人的团队,所以处理数据更多是依靠机器而非人力完成。我们要赋予机器学习能力,即借助计算机强大的计算能力去发现更多的数据信息。

依靠机器,使我们保持了较高的工作效率。所需的数据最快半小时,最多1天就能将全部爬完。而这些数据清洗的工作也仅依靠3、4个人便能完成。
除了提高效率,机器学习还具备三个功能:
数据补全:从网上爬下来的数据很多质量不高,而数据补全功能就是在当数据不完整时,可以根据已有的数据去推测估算缺失的数据;
新数据:在缺少某种数据时,可以从已有的数据提取生产出新数据。就像通过影像数据可以提取建筑数据;
数据生长:从现有的数据中,可以提取出某些数据内在的规律,根据规律生产新数据。凭借完整的流程设置和机器学习,目前我们获得数据量是非常可观的,仅以位置数据为例,目前GeoHey的位置数据总量将近8亿,位置数据年平均增量达到了58%。同时,我们还对数据实行周期更新,更新频率从小时到每季度不等。
当数据被掌握了之后,我们可以用它做哪些事情呢?这就是一个发掘地理大数据价值的过程,我想通过三个案例来介绍。
1. 用大数据来展现,哪家运营商的4G信号好?
如何用地理大数据判断哪里的4G信号哪家强?作为非专业人士,面对这个问题很难回答。不过,我们通过挖掘地理数据,能够给出答案。
首先,万事开头找数据。
那么这些数据从哪里挖掘呢?我们都知道,作为通讯运营商,信号离不开通信基站的支持,每个通信基站上都有一个传感器,传输的信号数据便可以被我们获取,来判断移动、电信和联通三家运营商的4G信号差异。
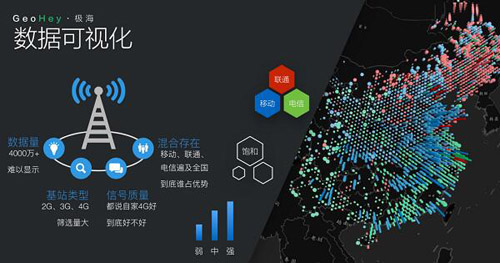
对此,我们采集了7500万通信基站的数据。(DT君注:在现场,高楠还演示了上图右边的这些数据采集后的三维可视化效果。)
在不同区域不同运营商的4G信号强度是不同的。比如,电信的数据应用最普遍且信号强度最高,而在北方尤其是东北地区,联通则更加强势,信号也要明显电信和移动两家运营商。
除了判别不同地区4G信号的差异,我们还能看到不同运营商的信号覆盖密集程度。以西南地区的贵州省为例,在当地除了移动一家独大之外,信号的密集程度也明显要低于中东部地区。从侧面来看,这也说明贵州省的基站分布不均,对于各大运营商而言,依旧存在竞争的可能。
所以,当你吐槽4G信号不给力的时候,不妨拿出这张图,看看你在哪个位置,在用哪家运营商的网络服务。
2. 为商业服务,大数据可以帮助星巴克开下一家店
地理大数据的商业应用,则可以直观体现在店铺选址上。我们就拿星巴克如何开下一家店这个命题来举例。
首先,要判断星巴克此前的选址偏好以及消费人群结构,这样就能了解你会在哪儿遇见星巴克,又能在星巴克遇上哪些人。
举个栗子,交通便利的路段容易获得星巴克青睐,而消费人群中又有20%的商旅乘客。
还记得之前提到的机器学习吗?在星巴克选址上,我们能不能通过机器学习的方式去获得选址的解决方案呢?
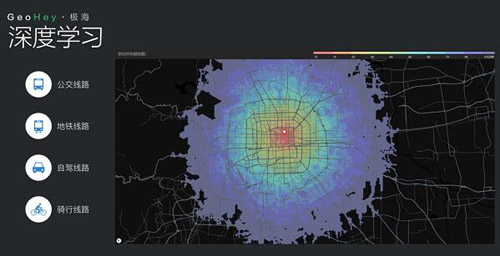
通过机器,以北京的星巴克门店为例,根据不同交通工具的通勤时间情况,我们找到了星巴克门店的辐射范围,也能比较出各家门店辐射范围的重叠(注:以下展现的是演示数据)。
然后我们通过机器学习,发现了星巴克的“朋友圈”(DT君注:也就是星巴克之前开的店,老是跟哪些其他品牌店铺在一起)。
这个“朋友圈”的一些秘密,通过这张结构图可以体现出来(注:以下是演示数据,不是真实分析结果):
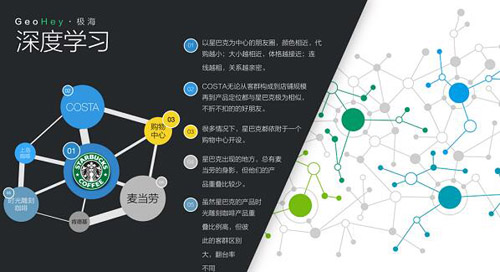
上图中,以星巴克为中心的朋友圈,连线越粗,关系越亲密,比如肯德基与麦当劳,两者紧密相连,各自的产品也颇为接近。而麦当劳和肯德基,和星巴克之间的关系则是比较弱的。相比较之下,同样被人熟知的咖世家(COSTA),无论从客群构成到店铺规模,再到产品定位都与星巴克极为相似,两家极有可能出现在邻近的地方。
那么按照大数据的学习方式,如果我看到一家COSTA咖啡店附近没有星巴克,是不是这里就可以开一家呢?
不过,GeoHey开发出的地理大数据产品,目前并不直接面向市场终端消费者,作为为企业决策提供地理大数据服务的机构,我们的产品是面向B端。这就意味着,从这座金矿中淘到的金,普通消费者要感受到地理大数据的价值,至少需要一道其他的“加工手续”。
3. 避免看病难,大数据提供一些解决方案
第三个案例,我们来看看大数据怎么提供帮助解决民生问题的方案。
看病难一直是个困扰多数人的问题。如何破解这个问题?
我们采集了全国三甲医院的数据,包括就医数据、医生资料情况等。根据这些采集的数据进行分析,我们能够得出这些结论:

首先是三甲医院的地域分布不均,全国80%的三甲医院被20%的城市瓜分。和三甲医院分布不均的还有教授医师的数量,20%的城市占据了全国85%的教授医师资源。其实,大家普遍吐槽的看病难其实就是集中前往大城市的三甲医院寻找教授医师看病造成的。
另外,结合就医数据,我们还可以得出一些普遍性的结论,其实在一个城市里头,忙碌的科室仅占全部科室的29%。在同城的医生里头,仅有22%的医生会非常忙碌。
要避免看病难,如无大病,不一定要前往三甲医院找教授医师就诊。
本文作者:佚名
来源:51CTO