一直傻傻分不清倒排和列存,今天有空梳理一下,主要有四个概念要明确:
1. 索引方式: 正向索引,反向索引(倒排)
2. 存储方式: 行存,列存
3. 数据结构: HashMap,B-Tree,BitMap...
4. 存储结构:
+ 顺序组织(顺序文件)
+ 索引组织(索引文件)
+ 散列组织(散列文件)
+ 链组织(多关键字文件)
索引方式
- 索引方式是种指导性的的思想,和具体数据结构和存储结构没有直接关系
- 正向索引:DocId->Value
- 反向索引:Value->DocId
倒排索引 Inverted Index
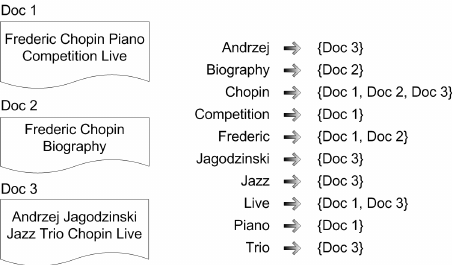
- 倒排索引就是反向索引,是信息检索中最基础的索引方法,具体是把索引存为倒排表和倒排链,倒排表存的是所有的值,倒排链存的是 DocId 列表。
存储方式
- 存储方式就是正排中存value的方式,也是种指导思想,和具体数据结构,存储结构没有关系的

- 存储方式主要分为按行存储和按列存储(column-oriented)两种
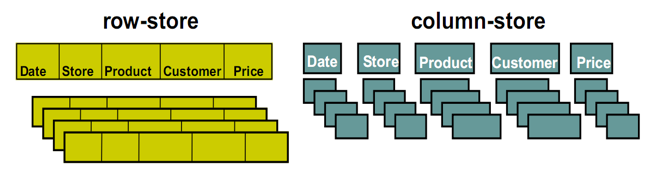
按行存储
- 以单行作为一个最小存储单元,用偏移量表示各列
- 没有索引的查询使用大量I/O
- Mysql 就是种按行存储的方式,对于无条件的单列取出,需要遍历全表
按列存储
- 以一列作为一个record,采取对齐的方式或者 MetaData 的方式记录行信息
- 数据即是索引,只查单列的情况下可以大量降低系统IO
- 同种数据在一起,方便压缩
- HBase 就是按列存储的,采用 MetaData 记录行信息
数据结构
- 数据结构是数据真实的组织形态,是逻辑层面的真实结构
- 同一种数据结构可以实现不同的思想,下面以 B-Tree 举例
B-Tree
倒排
- B 树如果每个内部节点存的是具体的value,叶子节点存 id,那么这就是个倒排
- 真实场景中,的确有不少搜索引擎是这么存倒排的
正排
- 如果内部节点存 Id,叶子节点存内容,这就是个正排
- 真实场景中,mysql 的 pk 索引就是这么存的
- 行存列存
+ 如果正排的 B-tree 的叶子节点存的是一行的值,那么这就是行存,反之,如果是一列的值,就是列存
存储结构
- 存储结构就是数据真实落盘的方式,是物理层面的真实结构
- 根据不同的数据结构有不同的存储结构
- 一般而言,B-Tree 就是索引文件落盘,而 HashTable 则可以以散列存储。
- 目前基本都是索引结构落盘,不同产品的具体实现均不相同。
- 如 IBM 的VSAM就是存储 B-tree 的一种文件格式,由三部分组成:索引集,顺序集和数据集
列存与倒排
- 回到开头的问题,列存和倒排到底是什么关系呢?
- 列存是一种正排的存储思想,和倒排没什么关系
- 一般由于搜索引擎的排序都是少数列的,所以一般搜索引擎都是精确查询用倒排,比较算分用列存
参考资料
版权声明
- 自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)
- 本文首发于: http://czjxy881.coding.me/blog/2017/02/12/dao-pai-yu-lie-cun/
时间: 2024-12-25 23:04:29