长尾问题是分布式计算里最常见的问题之一,也是典型的疑难杂症。究其原因,是因为数据分布不均,导致各个节点的工作量不同,整个任务就需要等最慢的节点完成才能完成。处理这类问题的思路就是把工作分给多个Worker去执行,而不是一个Worker单独抗下最重的那份工作。本文希望就平时工作中遇到的一些典型的长尾问题的场景及其解法做一些分享。
Join
Join能出现长尾,是因为Join时出现某个Key里的数据特别多的情况。不讨论两张表都是小表的情况。如果两张表里有一张大一张小,可以考虑使用Mapjoin,对小表进行缓存。具体语法和说明可以参考这里。如果是MapReduce作业,可以使用资源表的功能,对小表进行缓存。
但是如果两张表都比较大,就需要先尽量去重。实在不行的话,就需要从业务上考虑,为什么会有这样的两个大数据量的Key要做笛卡尔积,能否从业务上进行优化。
Group By
Group By Key 出现长尾的原因是因为某个Key内的计算量特别大。
对SQL进行改写,添加随机数,把长Key进行拆分是解决Group By长尾的一种比较好的方法,具体的原理也比较容易懂。对于一个SQL:
Select Key,Count(*) As Cnt From TableName Group By Key;
不考虑Combiner,M节点会Shuffle到R上,然后R再做Count操作。对应的执行计划是M->R
但是如果对长尾的Key再做一次工作再分配,就变成:
-- 假设长尾的Key已经找到是KEY001
SELECT a.Key
, SUM(a.Cnt) AS Cnt
FROM (
SELECT Key
, COUNT(*) AS Cnt
FROM TableName
GROUP BY Key,
CASE
WHEN Key = 'KEY001' THEN Hash(Random()) % 50
ELSE 0
END
) a
GROUP BY a.Key;
可以看到,这次的执行计划变成了M->R->R。虽然执行的步骤变长了,但是长尾的Key经过了2个步骤的处理,整体的时间消耗可能反而有所减少。不过大家也可以很容易看出来,如果数据的长尾并不严重,用这种方法人为地增加一次R的过程,最终的时间消耗可能反而更大。
对于这种优化方法,有一个通用的实现方法,就是使用系统参数,设置
set odps.sql.groupby.skewindata=true。
但是通用性的优化策略无法针对具体的业务进行分析,得出的结果不总是最优的。开发人员也可以根据实际的数据情况,用更加高效的方法来改写SQL。
Distinct
可以看到,对于Distinct,上面的策略已经不生效了。对这种场景,我们可以考虑:
--原始SQL,不考虑Uid为空
SELECT COUNT(uid) AS Pv
, COUNT(DISTINCT uid) AS Uv
FROM UserLog;
可以改写成
SELECT SUM(PV) AS Pv
, COUNT(*) AS UV
FROM (
SELECT COUNT(*) AS Pv
, uid
FROM UserLog
GROUP BY uid
) a;
可以看到,我们把Distinct改成了普通的Count,这样的计算压力不会落到同一个Reducer上。而且这样改写后,既能支持前面提到的Group By优化,系统又能做Combiner,性能会有较大的提升。
动态分区
动态分区功能为了整理小文件,会在最后起一个Reduce,对数据进行整理。所以如果使用动态分区写入数据时有倾斜的话,就会发生长尾。
另外就平时经验来看,滥用动态分区的功能也是产生这类长尾的一个常见原因。如果写入的数据已经确定需要把数据写入某个具体分区,那可以在Insert的时候指定需要写入的分区,而不是使用动态分区。
Combiner
对于MapRedcuce作业,使用Combiner是一种常见的长尾优化策略。在WordCount的例子里,就已经有提到这种做法。通过Combiner,减少Maper Shuffle往Reducer的数据,可以大大减少网络传输的开销。对于MaxCompute SQL,这种优化会由系统自动完成。
需要注意的是,Combiner只是Map端的优化,需要保证是否执行Combiner的结果是一样的。以WordCount为例,传2个(KEY,1)和传1个(KEY,2)的结果是一样的。但是比如在做平均值的时候,就不能在Combiner里就把(KEY,1)和(KEY,2)合并成(KEY,1.5)。
系统优化
其实针对长尾这种场景,除了前面提到的Local Combiner,MaxCompute系统本身还做了一些优化。比如在跑任务的时候,日志里突然打出这样的内容(+N backups部分):
M1_Stg1_job0:0/521/521[100%] M2_Stg1_job0:0/1/1[100%] J9_1_2_Stg5_job0:0/523/523[100%] J3_1_2_Stg1_job0:0/523/523[100%] R6_3_9_Stg2_job0:1/1046/1047[100%]
M1_Stg1_job0:0/521/521[100%] M2_Stg1_job0:0/1/1[100%] J9_1_2_Stg5_job0:0/523/523[100%] J3_1_2_Stg1_job0:0/523/523[100%] R6_3_9_Stg2_job0:1/1046/1047[100%]
M1_Stg1_job0:0/521/521[100%] M2_Stg1_job0:0/1/1[100%] J9_1_2_Stg5_job0:0/523/523[100%] J3_1_2_Stg1_job0:0/523/523[100%] R6_3_9_Stg2_job0:1/1046/1047(+1 backups)[100%]
M1_Stg1_job0:0/521/521[100%] M2_Stg1_job0:0/1/1[100%] J9_1_2_Stg5_job0:0/523/523[100%] J3_1_2_Stg1_job0:0/523/523[100%] R6_3_9_Stg2_job0:1/1046/1047(+1 backups)[100%]
可以看到1047个Reducer,有1046个已经完成了,但是最后一个一直没完成。系统识别出这种情况后,自动启动了一个新的Reducer,跑一样的数据,然后看两个哪个快,取快的数据归并到最后的结果集里。
业务优化
虽然前面的优化策略有很多,但是实际上还是有限。有时候碰到长尾问题,还需要从业务角度上想想是否有更好的解决方法,比如:
- 实际数据可能包含非常多的噪音,比如如果想根据访问者的ID进行计算,看看每个用户的访问记录的行为,那就需要先去掉爬虫的数据(不过现在的爬虫也越来越难识别了)。否则爬虫数据很容易长尾计算的长尾。类似的情况还包含根据xxid进行关联的时候,需要考虑这个关联字段是否存在为空的情况。
- 因为业务的情况,总会有一些特殊情况,比如ISV的操作记录,在数据量、行为方式上都会和普通的个人会有很大的区别。那么可以考虑针对大客户,使用特殊的分析方式进行单独处理。
- 数据分布不均匀的情况下,不要使用常量字段做Distribute by字段来实现全排序。
优化实战
前面洋洋洒洒说了一堆的理论,这里咱们就动手做个调优。数据来源天池的移动推荐算法线下赛,已经过脱敏。因为线下赛供的数据提比较少,所以我对数据做了一些冗余加权以便让长尾更加明显。
我首先想看看数据的分布,跑了个SQL
SELECT user_id
, COUNT(*) AS cnt
, COUNT(DISTINCT item_id) AS item_cnt
FROM tianchi_fresh_comp_train_user_lt a1
GROUP BY user_id
ORDER BY item_cnt DESC
LIMIT 100;
结果因为前面提到的造数据的时候长尾数据多复制了一些,长尾严重地把backup的优化策略都给跑出来了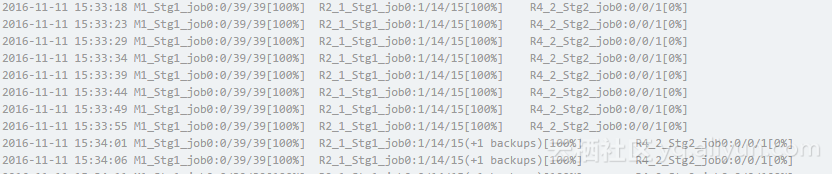

我们这时候不能直接拿到这个数据就直接想技术上怎么优化,作为数据分析师,需要先了解数据,看下这个key是什么。虽然Count()多的Count(Distinct item_id)不一定多,但是一般来说Count()和其他人明显不一样的数据总是有问题的,可以从这里入手。于是跑了个
SELECT user_id
, COUNT(*) AS cnt
FROM tianchi_fresh_comp_train_user_lt
GROUP BY user_id
ORDER BY cnt DESC
LIMIT 100;
很快跑好了,结果如下(这个长尾造的有点多)。不过如果怕Count(*)和Count(Distinct item_id)的Key不同,可以参考本文最后的SQL
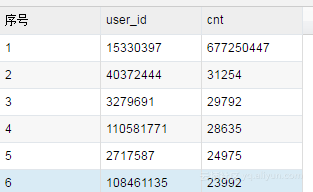
正想看看是不是就是这个Key(15330397)的问题,前面的那个长尾也跑好了(跑了25:13),一看,还真是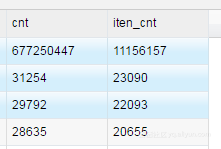
这么明显的数据肯定是异常数据了,回头到底是爬虫还是什么特殊情况再单独研究,这里根据之前的策略,有2种方法:
直接对异常数据做单独处理,这里不计算异常数据:
SELECT user_id
, COUNT(*) AS cnt
, COUNT(DISTINCT item_id) AS item_cnt
FROM tianchi_fresh_comp_train_user_lt a1
WHERE user_id <> '15330397'
GROUP BY user_id
ORDER BY item_cnt DESC
LIMIT 100;
这个SQL很快,一分钟就得出结果。根据这个结果做个可视化,就能够很清楚看到天猫移动端用户的购买情况了。但是有个缺点就是我们这里的长尾比较少,就造了一条。但是实际上,可能会有很多爬虫在爬数据,那就没办法在SQL里写死这些过滤的USER_ID。我们可以考虑先取到这些长尾的数据后做mapjoin过滤异常数据,具体的实现这里就不做了。
另外我们再试试前面提到的MRR的方法以进行SQL改写:
SELECT user_id
, SUM(cnt) AS cnt
, COUNT(*) AS item_cnt
FROM (
SELECT user_id
, item_id
, COUNT(*) AS cnt
FROM tianchi_fresh_comp_train_user_lt a1
GROUP BY user_id,
item_id
) sub
GROUP BY user_id
ORDER BY item_cnt DESC
LIMIT 100;
这个SQL一共花了(3:25)。
通过这两种方法的实验,我们更好地了解到数据里的信息,同时更快地得出结果。
本文使用的产品涉及大数据计算服务(MaxCompute),地址为https://www.aliyun.com/product/odps
配合大数据开发套件 https://data.aliyun.com/product/ide 完成的。
如果有问题,可以加入我们的钉钉群来咨询