产品概述:
阿里云 Elastic MapReduce(E-MapReduce) 是运行在阿里云平台上的一种大数据处理的系统解决方案。E-MapReduce 构建于阿里云云服务器 ECS 上,基于开源的 Apache Hadoop 和 Apache Spark,让用户可以方便地使用Hadoop和Spark生态系统中的其他周边系统(如 Apache Hive、Apache Pig、HBase 等)来分析和处理自己的数据。不仅如此,用户还可以通过E-MapReduce将数据非常方便的导出和导入到阿里云其他的云数据存储系统和数据库系统中,如阿里云 OSS、阿里云 RDS 等。
E-MapReduce 的用途
当用户想要使用 Hadoop、Spark 等分布式处理系统的时候,通常需要经历如下的步骤:
1.评估业务特点
2.选择机器类型
3.采购机器
4.准备硬件环境
5.安装操作系统
6.部署 Hadoop 和 Spark 等 app
7.启动集群
8.编写应用程序
9.运行作业
10.获取数据等一系列的步骤
在这些流程中,真正跟用户的应用逻辑相关的是从第8步才开始,第1-7步的各项工作都是前期的准备工作,通常这个前期工作都非常冗长繁琐。而 E-MapReduce 提供了集群管理工具的集成解决方案,如主机选型、环境部署、集群搭建、集群配置、集群运行、作业配置、作业运行、集群管理、性能监控等。
通过使用 E-MapReduce,用户可以从集群构建各种繁琐的采购、准备、运维等工作中解放出来,只关心自己应用程序的处理逻辑即可。此外,E-MapReduce 还给用户提供了灵活的搭配组合方式,用户可以根据自己的业务特点选择不同的集群服务。例如,如果用户的需求是对数据进行日常统计和简单的批量运算,则可以只选择在 E-MapReduce 中运行 Hadoop 服务;而如果用户还需要流式计算和实时计算的需求,则可以在 Hadoop 服务基础上再加入 Spark 服务。
E-MapReduce 的组成
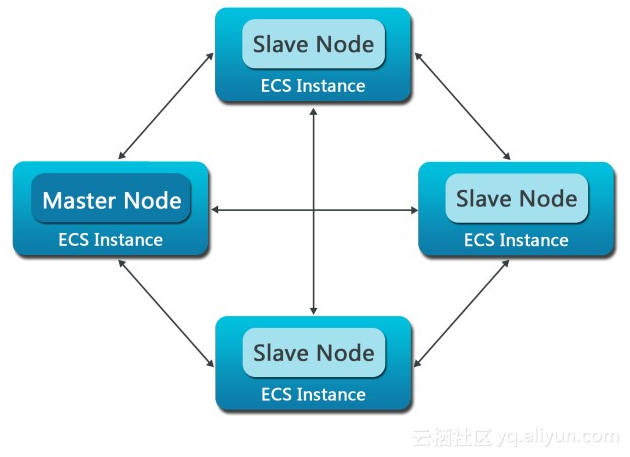
E-MapReduce 最核心也是用户直接面对的组件是集群。一个 E-MapReduce 集群是由一个或多个阿里云 ECS instance 组成的 Hadoop 和 Spark 集群。以 Hadoop 为例,在每一个 ECS instance 上,通常都运行了一些 daemon 进程(如 namenode、datanode、resoucemanager 和 nodemanager),这些 daemon 进程就组成了 Hadoop 集群。运行 namenode 和 resourcemanager 的节点被称为 master 节点,而运行 datanode 和 nodemanager 的节点被称为 slave 节点。
例如,下图表示了一个包含1个 master 节点和3个 slave 节点的 E-MapReduce 集群:
产品优势
与自建集群相比,E-MapReduce 能给您提供相对方便可控的手段,从各方面管理自己的集群。此外,它还具有以下优势:
- 易用性
您可简单选择所需 ECS 机型(CPU、内存)与磁盘,并选择所需的软件,进行自动化部署。
您可以根据自己或数据源所处的地理位置申请对应位置的集群资源。目前阿里云 ECS 支持的区域包括华东 1、华东 2、华北 1、华北 2、华南 1、新加坡、香港、美东 1、美西 1 等区域。E-MapReduce 支持的区域包括华北 2、华东 1、华东 2 和华南 1,后续会陆续开放到阿里云 ECS 支持的所有区域。
- 低价
您可以按需创建集群,即离线作业运行结束就可以释放集群,还可以在需要时动态地增加节点。
- 深度整合
与阿里云其它产品如 OSS、MNS、RDS、MaxCompute 等深度整合,使其可作为 E-MapReduce 产品中 Hadoop/Spark 计算引擎的输入源或者输出目的地。
- 安全
E-MapReduce 整合了阿里云 RAM 资源权限管理系统,通过主子账号对服务权限进行隔离。
基础架构
E-MapReduce 的产品架构如下图所示:
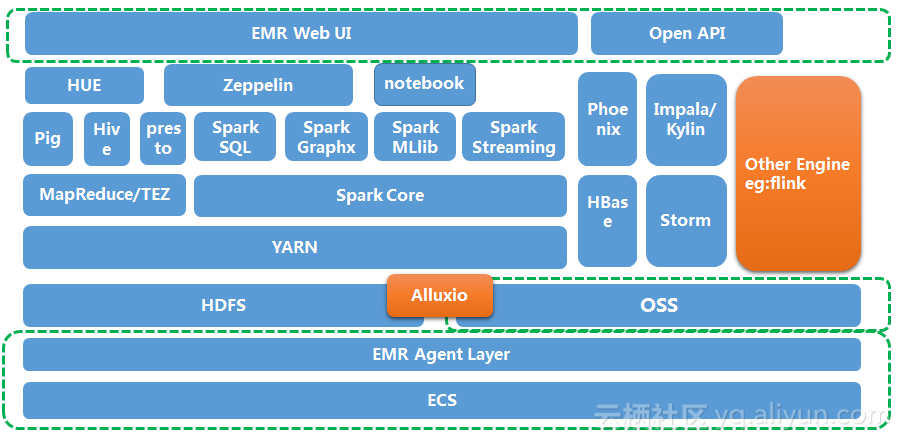
从上图可以看出,E-MapReduce 集群基于 Hadoop 的生态环境来搭建,同时可以跟阿里云的对象存储服务(OSS),云数据库(RDS)等云服务进行无缝数据交换,方便您将数据在多个系统之间进行共享和传输,以满足不同业务类型的访问需要。
使用场景
E-MapReduce 集群适用场景很多。简单说来,Hadoop ecosystem 以及 Spark 能够支持的场景,E-MapReduce 都可以支持。因为 E-MapReduce 本质就是 Hadoop 和 Spark 的集群服务,您完全可以将其使用的阿里云 ECS 主机视为自己专属的物理主机。以下示例列出了 E-MapReduce 使用的经典场景。
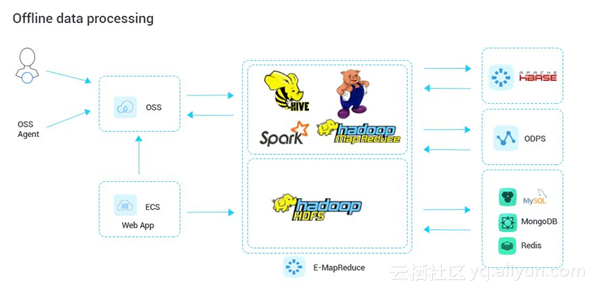
批量数据处理
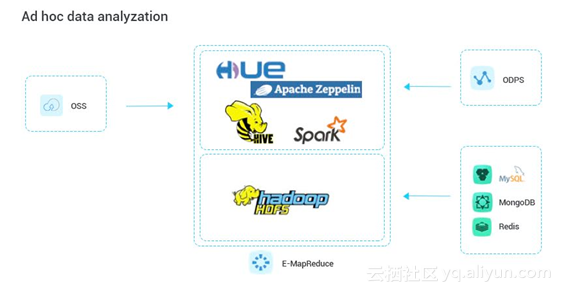
Ad hoc 数据分析查询
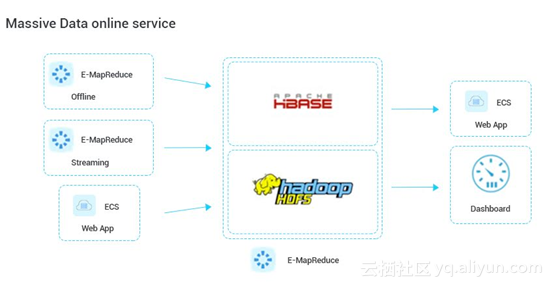
海量数据在线服务
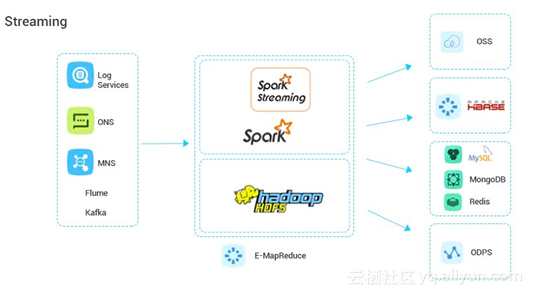
流式数据处理