OpenCL内存模型
OpenCL的内存模型定义了各种各样内存类型,各种内存模型之间有层级关系。各种内存之间的数据传输必须是显式进行的,比如从host memory到device memory,从global memory到local memory等等。


WorkGroup被映射到硬件的CU上执行(在AMD 5xxx系列显卡上,CU就是simd,一个simd中有16个pe),OpenCL并不提供各个workgroup之间的一致性,如果我们需要在各个workgroup之间共享数据或者通信之类的,要自己通过软件实现。
Kernel函数的写法
每个线程(workitem)都有一个kenerl函数的实例。下面我们看下kernel的写法:
每个Kernel函数都必须以__kernel开始,而且必须返回void。每个输入参数都必须声明使用的内存类型。通过一些API,比如get_global_id之类的得到线程id。
内存对象地址空间标识符有以下几种:
__global – memory allocated from global address space
__constant – a special type of read-only memory
__local – memory shared by a work-group
__private – private per work-item memory
__read_only/__write_only – used for images
Kernel函数参数如果是内存对象,那么一定是__global,__local或者constant。
运行Kernel
首先要设置线程索引空间的维数以及workgroup大小等。
我们通过函数clEnqueueNDRangeKerne把Kernel放在一个队列里,但不保证它马上执行,OpenCL driver会管理队列,调度Kernel的执行。注意:每个线程执行的代码都是相同的,但是它们执行数据却是不同的。


该函数把要执行的Kernel函数放在指定的命令队列中,globald大小(线程索引空间)必须指定,local大小(work group)可以指定,也可以为空。如果为空,则系统会自动根据硬件选择合适的大小。event_wait_list用来选定一些events,只有这些events执行完后,该kernel才可能被执行,也就是通过事件机制来实现不同kernel函数之间的同步。
当Kernel函数执行完毕后,我们要把数据从device memory中拷贝到host memory中去。


释放资源:
大多数的OpenCL资源都是指针,不使用的时候需要释放掉。当然,程序关闭的时候这些对象也会被自动释放掉。
释放资源的函数是:clRelase{Resource} ,比如: clReleaseProgram(), clReleaseMemObject()等。
错误捕捉:
如果OpenCL函数执行失败,会返回一个错误码,一般是个负值,返回0则表示执行成功。我们可以根据该错误码知道什么地方出错了,需要修改。错误码在cl.h中定义,下面是几个错误码的例子.
CL_DEVICE_NOT_FOUND -1
CL_DEVICE_NOT_AVAILABLE -2
CL_COMPILER_NOT_AVAILABLE -3
CL_MEM_OBJECT_ALLOCATION_FAILURE -4
…
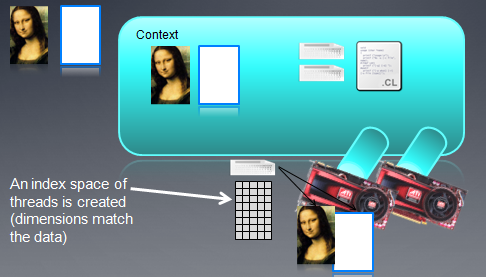
下面是一个OpenCL机制的示意图

程序模型
数据并行:work item和内存对象元素之间是一一映射关系;workgroup可以显示指定,也可以隐式指定。
任务并行:kernel的执行独立于线程索引空间;用其他方法表示并行,比如把不同的任务放入队列,用设备指定的特殊的向量类型等等。
同步:workgroup内work item之间的同步;命令队列中不同命令之间的同步。
完整代码如下:
也可以在http://code.google.com/p/imagefilter-opencl/downloads/detail?name=amdunicourseCode1.zip&can=2&q=#makechanges上下载完整版本。