数据集成是阿里集团对外提供的稳定高效、弹性伸缩的数据同步平台。本文将介绍如何使用数据集成将数据同步到HBase。我们以如下场景为例:线上有两个云HBase集群,想把其中一个集群的数据同步到另一个集群中。

第一步 创建数据集成项目
在使用数据集成同步数据之前,我们需要先在MaxCompute产品首页购买资源并创建一个项目。后续的数据同步任务就是放在这个项目下面执行的。具体步骤参见购买并创建项目
购买的资源不必和HBase在同一地区。如果已经创建过项目,可以忽略这一步。
第二步 准备调度资源
出于安全方面的考虑,目前HBase导入数据只支持本地模式,所以需要用户先申请ECS并将ESC添加到数据同步的资源组用于执行同步任务。
2.1 申请ECS
在HBase所在Region的任意Zone购买一台ECS,然后设置HBase的白名单。
注意:
(1)ECS要能够访问到HBase,在我们的例子中,两个HBase集群都是经典网络,所以我们购买一台经典网络的ECS,然后设置HBase的白名单即可。如果HBase是vpc网络,可参考HBase访问准备
(2)如果HBase和ECS是专有网络的话,ECS需要绑定公网IP,因为公网 IP 对于数据集成的汇报心跳非常重要。在创建时可以选择分配公网IP,也可以创建后绑定弹性公网 IP
2.2 新增调度资源
1、项目管理员进入进入 大数据开发套件-调度资源列表,点击 新增调度资源,填写新增的调度资源名称,如下图所示: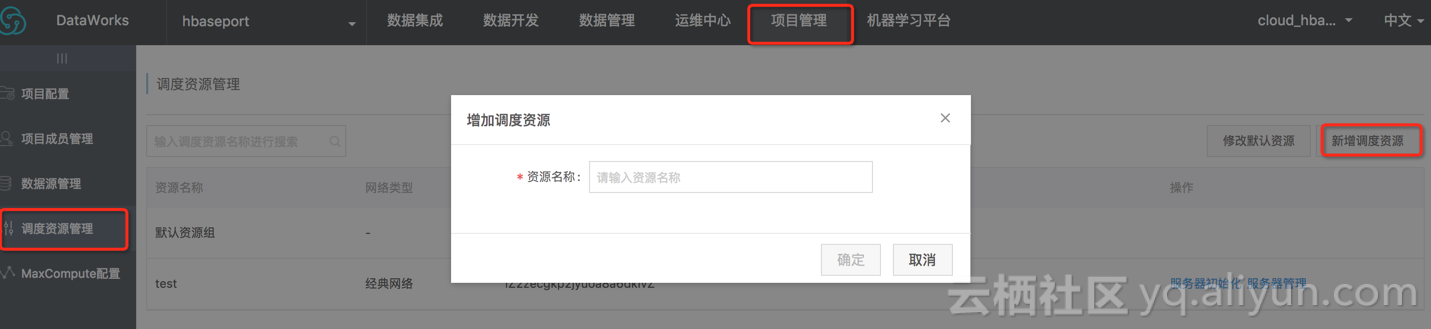
2、添加调度资源后,在弹窗界面内点击新建调度资源操作栏中的 服务器管理,进入服务器添加页面,将购买的 ECS 云服务器添加到资源组,如下图所示: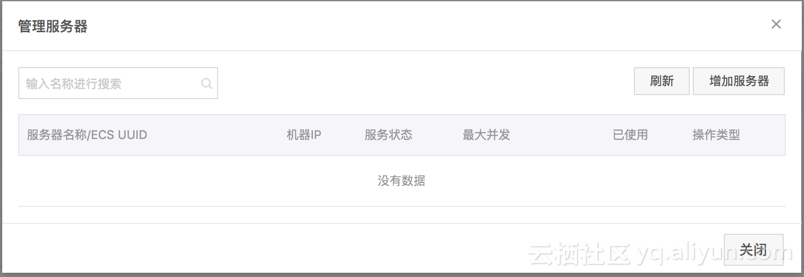
3、点击增加服务器;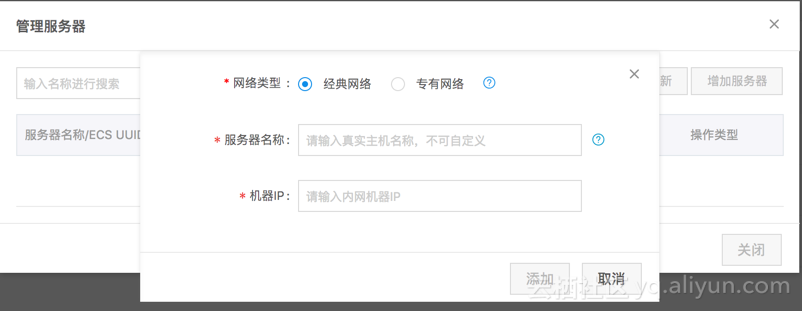
网络类型:选择经典网络;
服务器名称:获取方式:登录 ECS,执行 hostname 命令,取返回值;
机器 IP:输入专有网络 IP。
4、在调度资源管理页面,点击“服务器初始化”,然后按照弹出的提示在ECS上进行操作。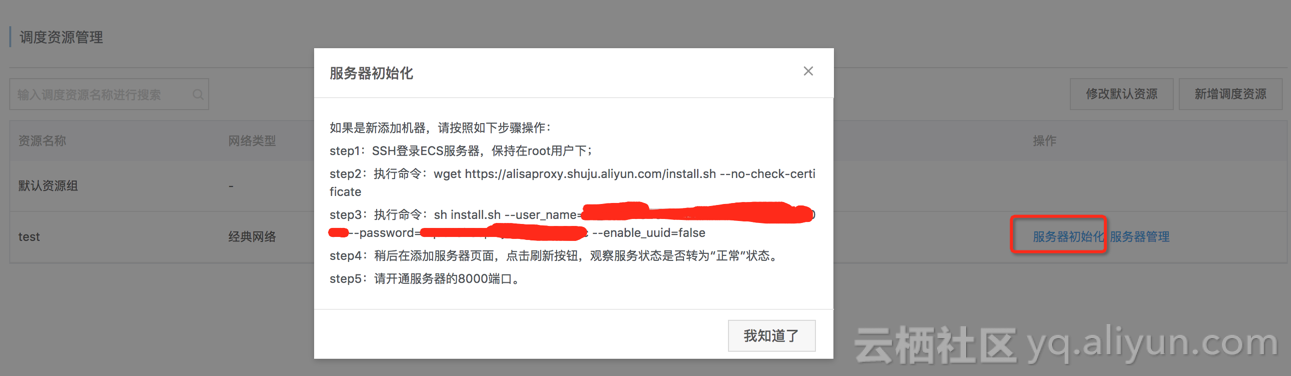
执行完安装命令后,可以看到服务器状态已显示为“正常”。
第三步 创建数据同步任务
HBase目前不支持向导模式,所以需要创建脚本模式任务并修改脚本中的插件配置。
3.1 创建脚本模式任务
1、以开发者身份进入 阿里云数加平台>大数据开发套件>管理控制台,点击“项目列表”下对应项目操作栏中的 进入工作区 ;
2、点击顶部菜单栏中的 数据集成 中左侧导航栏的 同步任务 ;
3、点击界面中的 “脚本模式”;
4、在弹出的“导入模板”中选择自己需要的“来源类型”和“目标类型”,如下图所示: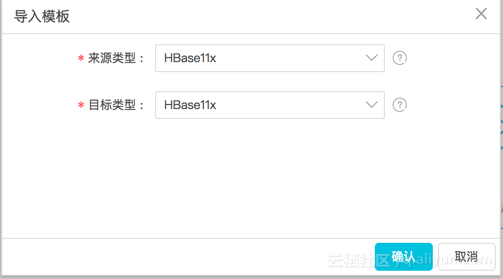
云HBase的版本是1.1,所以目标类型选择“HBase11x”,我们的例子中,源也是云HBase,所以源类型也选择“HBase11x”。
5、点确定后,会按照模版生成默认的配置,先保存。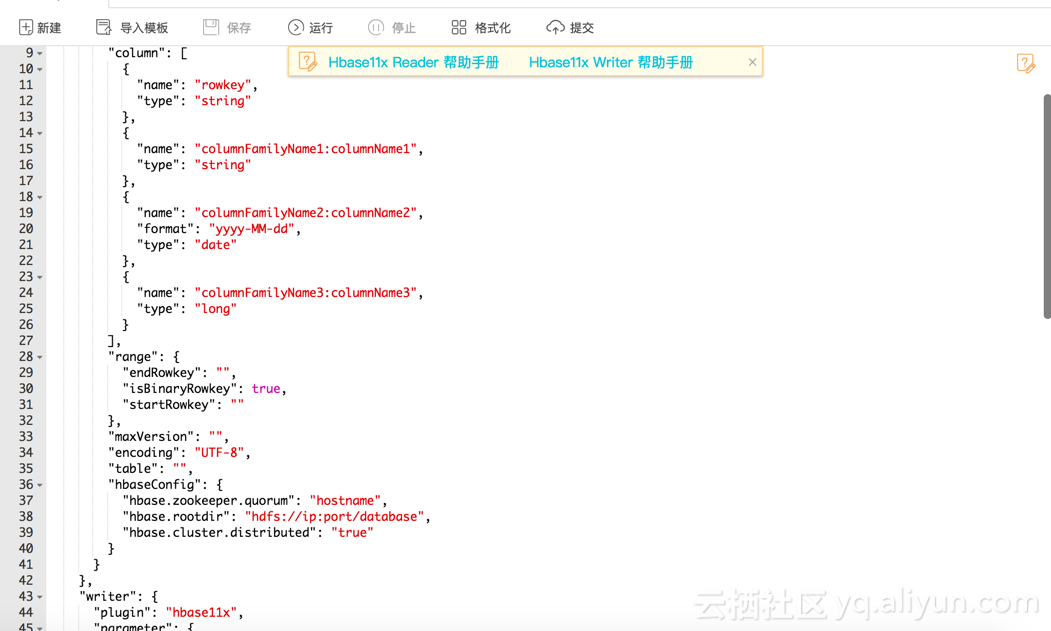
3.2 修改插件配置
reader需要改如下几个地方:
(1)column和table按照我们实际情况修改。
(2)我们同步全量数据,所以把range和maxversion删掉。
(3)hbaseconfig中,hbase.rootdir是不需要的,可以删掉。hbase.zookeeper.quorum可以在HBase实例的管理控制台查看。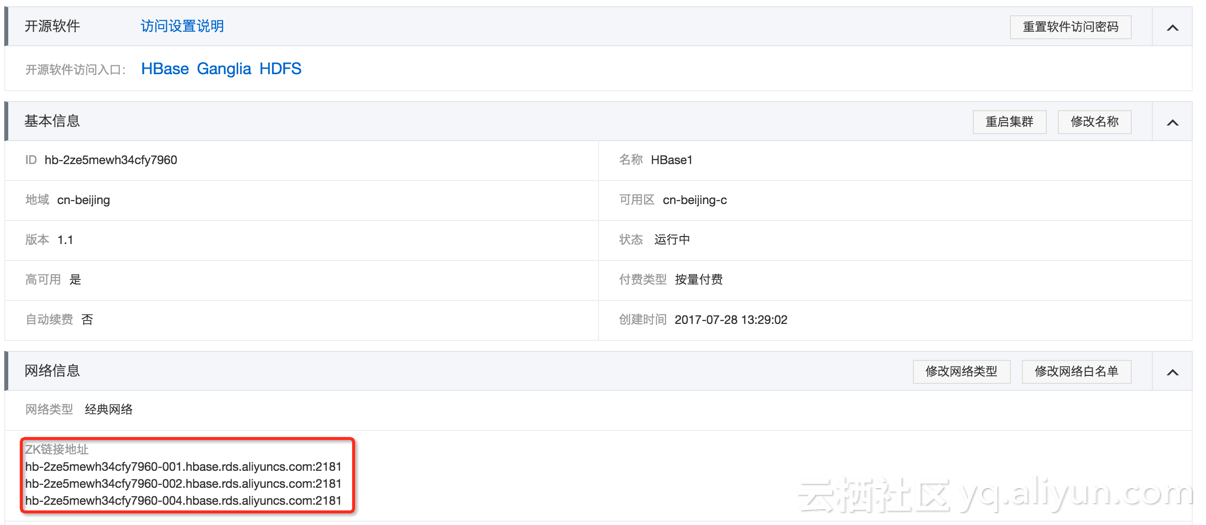
writer需要修改如下几个地方:
(1)rowkeyColumn。在我们的例子中,源表的rowkey导入过来直接做rowkey,所以把rowkeyColumn里面默认生成的:
{
"index": -1,
"type": "string",
"value": "_"
}
删掉。
(2)column和table按照实际情况修改。注意在运行同步任务前要确保已经建好目标表和列族。
(3)versionColumn在我们的例子里不需要,删掉。
(4)hbaseConfig和源插件类似,把hbase.rootdir删掉,hbase.zookeeper.quorum改成目标HBase的zk地址。
其他选项也可以根据实际情况修改。例如,可以修改speed里面的选项增加并行度。具体可参考HbaseReader 配置、HbaseWriter 配置以及脚本模式的配置
我们的例子中,最终的插件配置如下:
{
"configuration": {
"reader": {
"plugin": "hbase11x",
"parameter": {
"mode": "normal",
"scanCacheSize": "256",
"scanBatchSize": "100",
"column": [
{
"name": "rowkey",
"type": "string"
},
{
"name": "cf:a",
"type": "string"
}
],
"encoding": "UTF-8",
"table": "test",
"hbaseConfig": {
"hbase.zookeeper.quorum": "hb-2ze5mewh34cfy7960-001.hbase.rds.aliyuncs.com:2181,hb-2ze5mewh34cfy7960-002.hbase.rds.aliyuncs.com:2181,hb-2ze5mewh34cfy7960-004.hbase.rds.aliyuncs.com:2181",
"hbase.cluster.distributed": "true"
}
}
},
"writer": {
"plugin": "hbase11x",
"parameter": {
"mode": "normal",
"walFlag": "false",
"rowkeyColumn": [
{
"index": 0,
"type": "string"
}
],
"nullMode": "skip",
"column": [
{
"name": "cf:a",
"index": 1,
"type": "string"
}
],
"encoding": "UTF-8",
"table": "test",
"hbaseConfig": {
"hbase.zookeeper.quorum": "hb-2zel37texpqo9umcw-001.hbase.rds.aliyuncs.com:2181,hb-2zel37texpqo9umcw-002.hbase.rds.aliyuncs.com:2181,hb-2zel37texpqo9umcw-004.hbase.rds.aliyuncs.com:2181",
"hbase.cluster.distributed": "true"
}
}
},
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"concurrent": "1",
"mbps": "1"
}
}
},
"type": "job",
"version": "1.0"
}
修改完成后,保存。点击“提交”。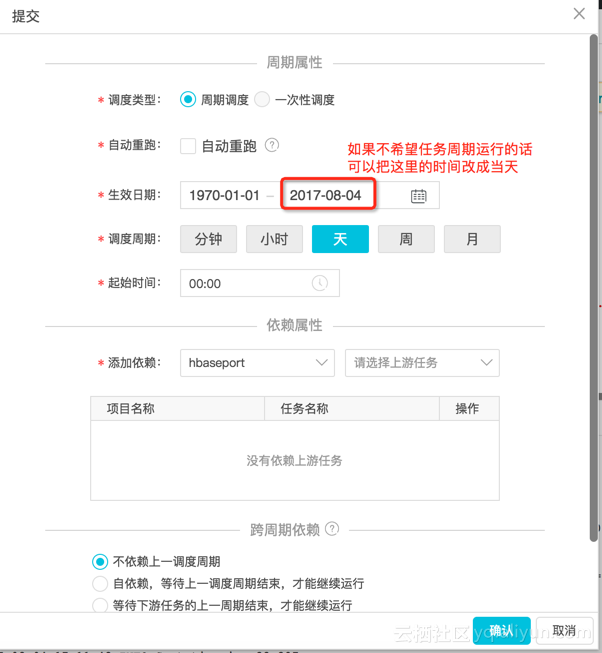
提交任务页面“一次性调度”选不了,如果我们不希望任务周期性运行的话,可以把时间改成当天。
第四步 运行任务
4.1 修改调度资源组
1、进入 大数据开发套件-运维中心-任务管理 页面,点击 列表;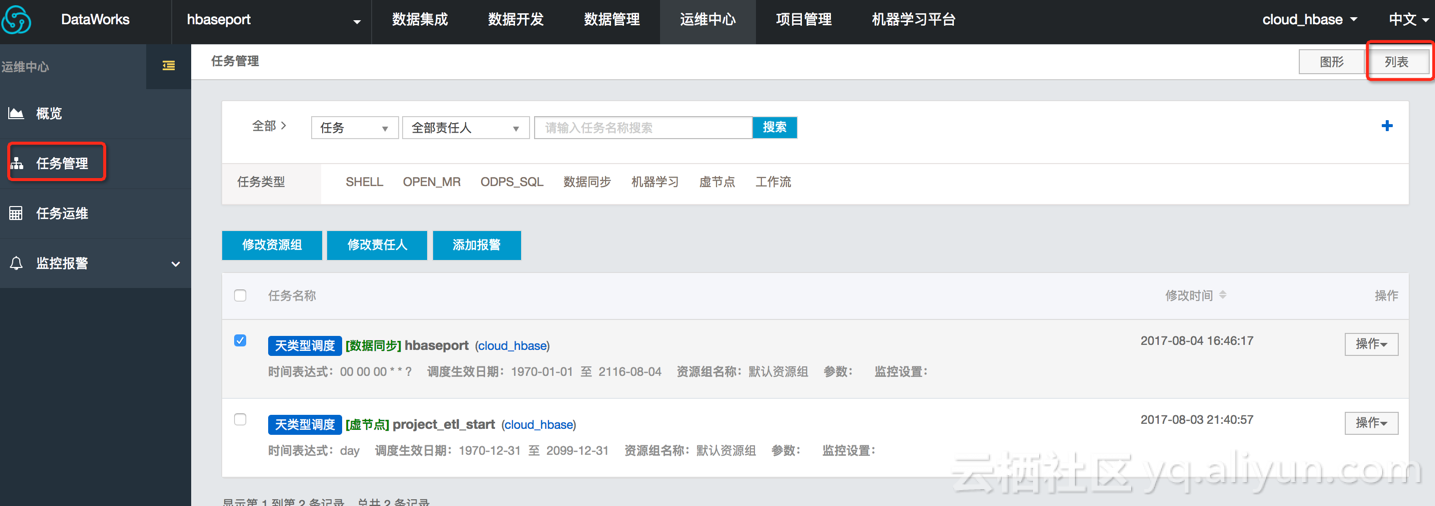
2、选择同步任务,点击 修改资源组;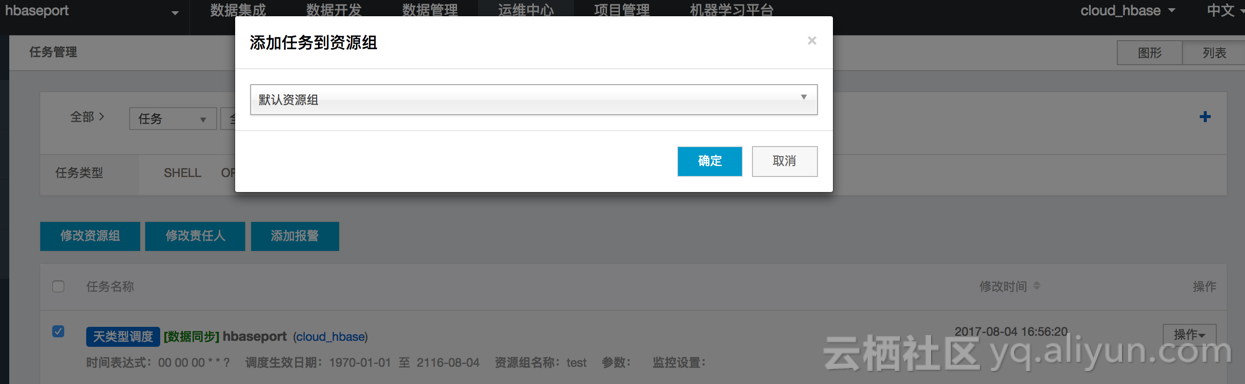
3、选择我们在第二步创建的资源组,点击 确认。
4.2 运行任务
在任务管理页面,点击 操作-补数据。然后等待任务完成。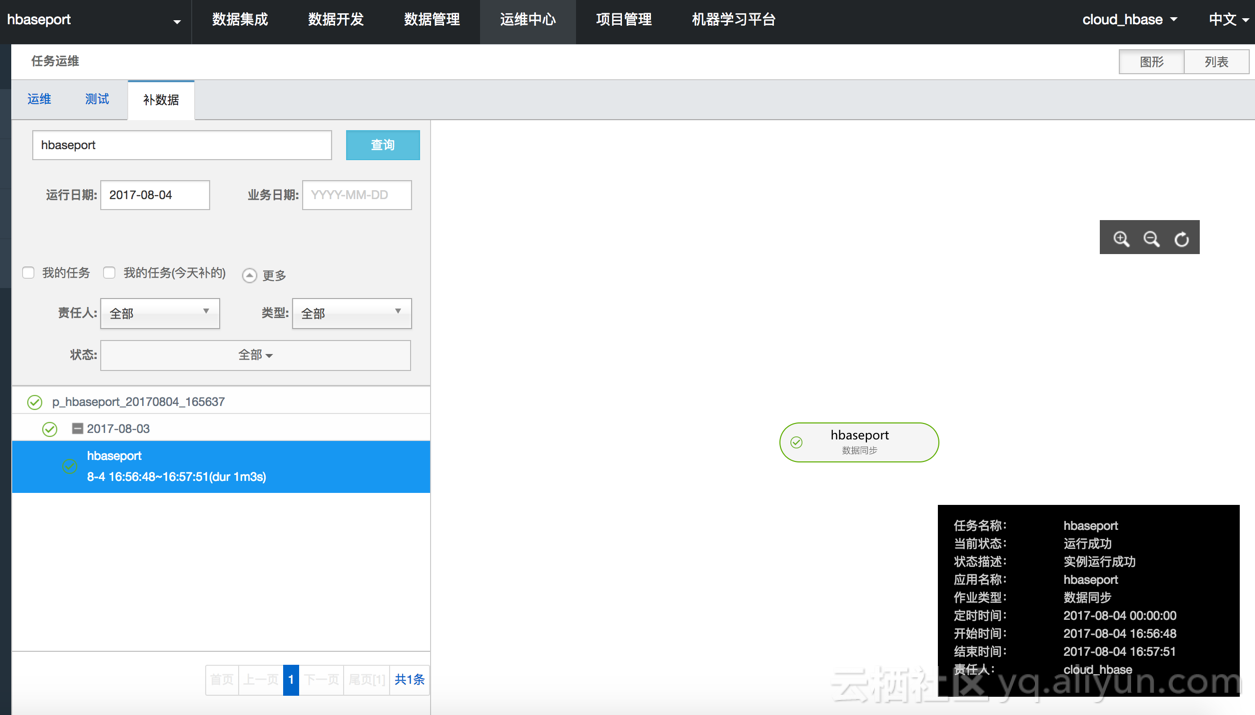
任务执行成功,我们在目标HBase里面已经看到有数据了。