1.5 在集群上以独立模式部署Spark
在分布式环境中的计算资源需要管理,使得资源利用率高,每个作业都有公平运行的机会。Spark有一个便利的被称为独立模式的自带集群管理器。Spark也支持使用YARN或者Mesos做为集群管理器。
选择集群处理器时,主要需要考虑延迟以及其他架构,例如MapReduce,是否共享同样的计算资源池。如果你的集群运行着旧有的MapReduce作业,并且这些作业不能转变为Spark作业,那么使用YARN作为集群管理器是个好主意。Mesos是一种新兴的、方便跨平台管理作业的、与Spark非常兼容的数据中心操作系统。
如果Spark是你的集群的唯一框架,那么独立模式就足够好用了。随着Spark技术的发展,你会看到越来越多的Spark独立模式被用于处理所有的大数据计算需求。例如,目前有些作业可能在使用Apache Mahout,因为MLlib目前没有作业所需要的特定的机器学习库。只要MLlib包含了这些库,这些特定的作业就可以移动到Spark了。
1.5.1 准备工作
让我们以由6个节点组成的一个集群的设置为例,包含一个主节点和5个从节点(在你的实际集群中以真实的名字替换它们)。
主节点
m1.zettabytes.com
从节点
s1.zettabytes.com
s2.zettabytes.com
s3.zettabytes.com
s4.zettabytes.com
s5.zettabytes.com
1.5.2 具体步骤
1.因为Spark的独立模式是默认的,所以你需要做的就是在所有主节点和从节点上安装Spark二进制文件。把/opt/infoobjects/spark/sbin放到每个节点的路径中。
$ echo "export PATH=$PATH:/opt/infoobjects/spark/sbin">> /home/
hduser/.bashrc
2.开启独立主服务器(先SSH到主节点)。
hduser@m1.zettabytes.com~] start-master.sh
从节点连接主节点的默认端口是7077,8088是它的网页界面端口。
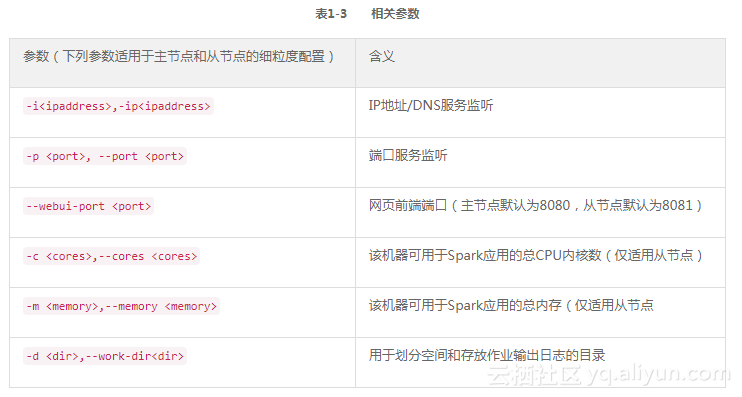
3.请SSH到主节点去开启从节点,主从节点之间的细粒度配置参数如表1-3所示。
hduser@s1.zettabytes.com~] spark-class org.apache.spark.deploy.
worker.Worker spark://m1.zettabytes.com:7077
4.不仅可以手动启动主从节点的守护程度,还可以使用集群启动脚本来完成。
5.首先,在主节点创建conf/slaves文件夹,并加入每一个从节点的主机名(本例有5个从节点,在实际操作中使用你自己从节点的DNS替换它们)。
hduser@m1.zettabytes.com~] echo "s1.zettabytes.com" >> conf/slaves
hduser@m1.zettabytes.com~] echo "s2.zettabytes.com" >> conf/slaves
hduser@m1.zettabytes.com~] echo "s3.zettabytes.com" >> conf/slaves
hduser@m1.zettabytes.com~] echo "s4.zettabytes.com" >> conf/slaves
hduser@m1.zettabytes.com~] echo "s5.zettabytes.com" >> conf/slaves
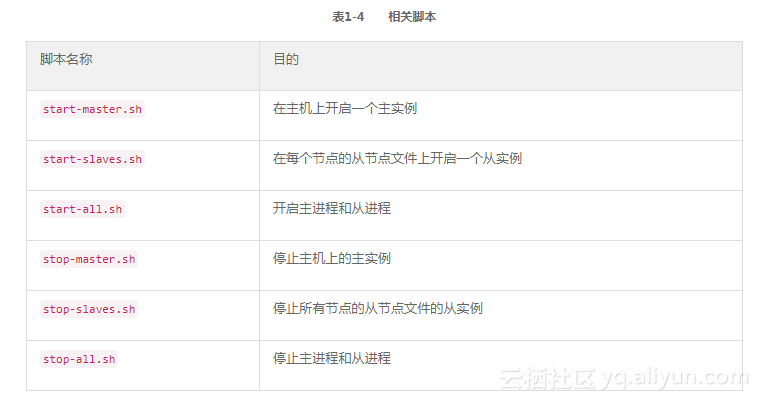
一旦从节点设置好了,你就可以使用如下脚本开启或停止集群,如表1-4所示。
6.使用Scala代码将应用连接到集群。
val sparkContext = new SparkContext(new SparkConf().
setMaster("spark://m1.zettabytes.com:7077")
7.通过Spark shell连接到集群。
$ spark-shell --master spark://master:7077
1.5.3 工作原理
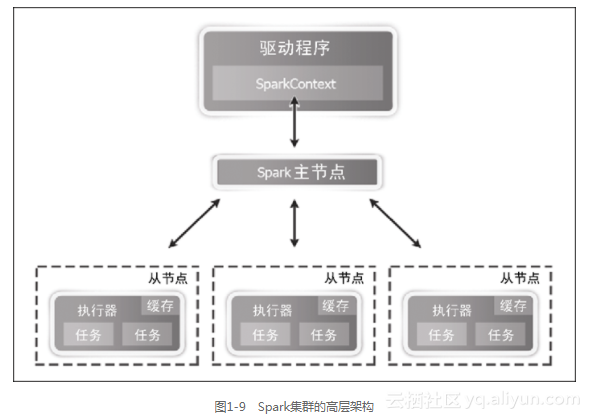
在独立模式下,Spark与Hadoop、MapReduce以及YARN类似,遵循主从架构。计算主程序被称为Spark master,它运行在主节点上。通过使用ZooKeeper,Spark master可以具有高可用性。如果需要的话,你可以增加更多的备用主节点。
计算从程序又被称为worker,它运行在每一个从节点上,worker程序执行如下操作。
报告从节点的可用计算资源给主节点,例如内核数、内存以及其他。
响应Spark master的执行要求,派生执行程序。
重启死掉的执行程序。
每个从节点机器的每个应用程序最多只有一个执行程序。
Spark master和worker都非常轻巧。通常情况下,500 MB到1 GB的内存分配就足够了。可以通过设置conf/spark-env.sh文件里的SPARK_DAEMON_MEMORY参数修改这个值。例如,如下配置将主节点和从节点的计算程序的内存设置为1 GB。确保使用超级用户(sudo)运行:
$ echo "export SPARK_DAEMON_MEMORY=1g" >> /opt/infoobjects/spark/conf/
spark-env.sh
默认情况下,每个从节点上运行一个worker实例。有时候,你的几台机器可能比其他的都强大,在这种情况下,你可以通过以下配置派生多个作业到该机器上(特指那些强大的机器):
$ echo "export SPARK_WORKER_INSTANCES=2" >> /opt/infoobjects/spark/conf/
spark-env.sh
Spark worker在默认情况下使用从节点机器的所有内核执行程序。如果你想要限制worker使用的内核数的话,可以通过如下配置设置该参数(例如12):
$ echo "export SPARK_WORKER_CORES=12" >> /opt/infoobjects/spark/conf/
spark-env.sh
Spark worker在默认情况下使用所有可用的内存(对执行程序来说是1 GB)。请注意,你不能给每一个具体的执行程序分配内存(你可以通过驱动配置对此进行控制)。想要分配所有执行程序的总内存数,可以执行如下设置:
$ echo "export SPARK_WORKER_MEMORY=24g" >> /opt/infoobjects/spark/conf/
spark-env.sh
在驱动级别,你可以进行如下设置。
要通过集群指定特定应用的最大CPU内核数,可以通过设置Spark submit或者Spark shell中的spark.cores.max配置。
$ spark-submit --confspark.cores.max=12
若要指定每个执行程序应分配的内存数(建议最小为8 GB),可以通过设置Spark submit或者Spark shell中的spark.executor.memory配置。
$ spark-submit --confspark.executor.memory=8g
图1-9描述了Spark集群的高层架构。
1.5.4 参考资料
http://spark.apache.org/docs/latest/spark-standalone.html找到更多配置选项。