
当有大企业为数据进行争论时,我们再一次感慨数据的价值。自从大数据一词被提出之后,我们无时无刻不再提醒着自己,累积了越多的数据,就越能手握金矿。在机器学习、深度神经网络开始走向大众视野之后,我们更加自豪,仿佛分分钟能从自己的数据中诞生个什么算法。
事实上,针对于机器学习应用范畴看来,绝大部分企业所谓的大数据,都只是一大堆占据着储存空间的垃圾。
因为,这些大数据都是未经清洗、处理过的脏数据,完全不足以用来训练算法模型。
今天就来谈谈机器学习这一高级产业中的“苦力工种”——数据预处理。
抛开盲目崇拜,我们其实知道,机器学习对于数据的依赖非常之深,同时对数据的要求也很高。和数据库中的数据不同,现实生活中我们采集到的数据往往存在大量人为造成的异常和缺失,非常不利于算法模型的训练。
而对于数据的清洗、特征标注等等,往往占据了一个项目七成的时间。
在分析了项目的具体需求之后,第一步就是数据的清洗。
数据清洗包含多种步骤,比如对异常值的处理、对缺失数据的处理和对重复数据的处理等等。
常用的办法是将数据制成直方图、点图、箱型图、Q-Q 图等等,从其中可以直观的发现需要清理的数据。
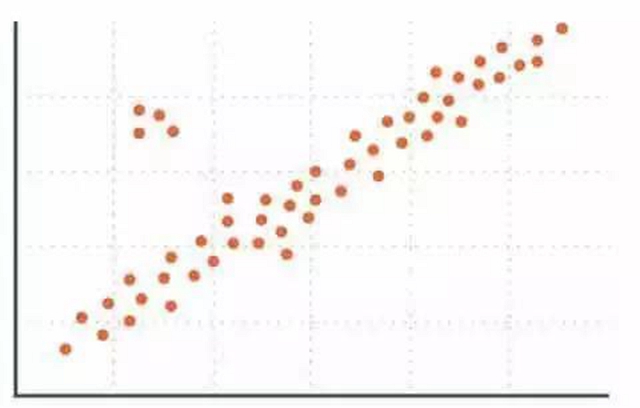
如图所示,远离群体的数据均为需要清理的数据。当然,清理也不一定是删除,可以根据实际情况选择用平均值替代甚至不处理等等。
在经历了痛苦的去异常、去缺失、去重复、降噪音之后,我们得到的仅仅是一份没有明显错误的原始数据。还要经历数据转换、降维等等方式让数据标准化,只保留我们所需要的维度。这样一来才可以进一步降低噪音,去除无关特征带来的巨大计算量。
以上的步骤可以运用于任何数据之上,像是在 NLP 中就要提取波形文件,去掉连接词、分词等等。至于在人脸识别中,则是将每个人的名字和对应的照片标注归类,去掉混乱度较高的人。再提取图片向量,一个人照片中向量的平均值既是他的特征。
总之,数据预处理工作的难度不大,但却能折腾的人欲仙欲死。
这也是为什么 Apollo 这样的平台会为人工智能创业者提供数据库,毕竟对于大多数中小企业来讲,获取数据虽然简单,对于数据的预处理却是几乎不可能完成的任务。而以谷歌、百度等为代表的大企业,拥有足够的人力和算力,能够将自己的数据妥善处理,甚至开放开来组建生态力量。
除去与巨头共舞,另外的选择就是购买第三方提供的数据库,可最大的问题就是数据的真实性和实用性。糟糕数据库带来的结果,往往是算法在数据库内跑的风生水起,一落地应用就漏洞百出。而在资本的揠苗助长下,大多数人都忙着鼓吹自己的算法模型而忽略了数据源头问题,最终就是将万丈高楼建立在沙地之上。
面对这种情况,最苦恼的就是那些还算不上 BAT 级别,但又有了足够规模的互联网企业:他们拥有了足够多的数据,不屑于拿所谓的算法作为融资噱头,而是真的想通过机器学习提升自身业务。可面对复杂的数据预处理工作,他们需要付出极大的人力成本。要是说邀请第三方为其处理,恐怕又不放心自身数据的安全。
而这一切,不正是商机所在吗?
在今年三月的谷歌云开发者大会上,谷歌就发布了一项新服务—— Google Cloud Dataprep。它可以自动检索出数据中的异常值,用户只要给出数据清理规则,整个过程中都不需要人工写代码来干预。所以,用户既可以简单的完成数据清理,又能很大程度上保证数据安全。
数据的预处理的确是机器学习中的“脏活累活”,但这不代表不能用技术的力量提高这部分工作的效率。相比遥遥无期的人工智能,有关数据预处理的需求已经摆在了我们面前,并且每天都在扩大。而专注与数据预处理垂直领域的技术服务商却寥寥无几。
所以,与其在 NLP、自动驾驶的红海中被巨头碾压,不如换个角度,从现在就开始想办法服务那些渴望 AI 的企业。
本文作者:脑极体
来源:51CTO