阿里云自研PB级nosql数据库TableStore近期发布了新功能Stream,也就是增量通道,可以让用户实时的获取数据库中的增删改操作。很多使用TableStore的用户会定期把数据导入各类计算平台做数据的离线分析,以前的做法是使用DATAX或者使用TableStore的SDK定期拉取数据。之前我们只能采用全量拉取的办法,定期的全量拉取势必会带来很多不必要的开销,并且也失去了新增数据实时处理的可能。那有了Stream增量通道后,之前的这些痛点都会被迎刃而解。
这个功能究竟怎么使用,又可以用在哪里呢?下面我就带大家初探TableStore的Stream功能。大家也可以先阅读下Stream的原理
产品功能
Stream功能和其他表格存储的很多功能一样,是用户表的一个属性。用户在创建表的时候可以指定是否开启Stream功能。用户也可以通过UpdateTable操作在后续需要使用Stream的时候开启。当用户开启Stream后,用户的修改记录在生命周期内(周期长短由用户开启Stream的时候指定,目前默认最大是一天,如有更长周期需要可以在官网提工单)会被一直保留。
除了表操作以外,Stream的API具体有以下:
- ListStreams 获取当前表的 Stream 信息,例如 StreamID。具体请参见ListStreams
- DescribeStream 获取当前表增量数据的分区信息,熟悉表格存储特性的同学会知道表格存储会自动根据用户指定的分片键做分区来实现负载均衡。而我们的增量数据也是通过分区来进行组织,所以消费增量数据之前需要了解当前的分区信息,也就是Stream中的Shard信息。具体参见DescribeStream
- GetShardIterator 获取具体某个分区的读取iterator。这个iterator可以简单理解为一个偏移量标记我们可以从哪里开始消费增量数据。具体参见GetShardIterator
- GetStreamRecord 拉取增量数据,每次拉取结束后,会更新iterator用来下次拉取。如果返回数据为空表示当前尚未读取到新数据。如果返回null说明这个分区已经不存在没有后续的增量数据了。GetStreamRecord
如何理解TableStore的增量数据
介绍了Stream API,可能还不是很直观理解TableStore的Stream数据是如何组织的,下面就以用户轨迹为例来介绍如何使用。如何基于表格存储实现用户轨迹数据的存储,可以参考如何高效存储海量GPS数据。
在这里,我们假设你使用如下的表结构存储你的海量轨迹数据,
| 主键顺序 | 名称 | 类型 | 值 | 备注 |
|---|---|---|---|---|
| 1 | partition_key | string | md5(user_id)前四位 | 为了负载均衡 |
| 2 | user_id | string/int | 用户id | 可以是字符串也可以是长整型数字 |
| 3 | task_id | string/int | 此次轨迹图的id | 可以使字符串也可以是长整型数字 |
| 4 | timestamp | int | 时间戳 | 使用长整型,64位,足够保存毫秒级别的时间戳 |
假如你有原始数据如下:
2017/5/20 10:10:10的时候小王在杭州虎跑路,开着私家宝马车,速度25km/h,当时风速2m/s,温度20度,已经开了8公里。
在表格存储中存储的是(11列);
| part_key | user_id | task_id | timestamp | longitude | latitude | brand | speed | wind_speed | temperature | distance |
|---|---|---|---|---|---|---|---|---|---|---|
| 04fc | 000001 | 001 | 1495246210 | 120.1516525097 | 30.2583277934 | BMW | 25 | 2 | 20 | 8000 |
当用户的位置不断发生变化,我们会产生一系列类似上面的轨迹数据,例如我们的粒度可以是10秒一个轨迹点。这样在一段时间内,我们可以积累海量的轨迹数据。那对于业务方,往往要做一些运营分析。
分析话题1:统计过去10分钟内是否有一个区域有驾驶热点,会带来交通拥堵。发现潜在拥堵点后,提前做一些车流疏散。
分析话题2:又或者我们希望在晚饭时间点,统计一下来某个商圈吃饭的客户都是从哪些地方开车过来的,日后可以在辐射区域内做一些精准推广。
这类问题的共同点是需要在这张轨迹表中获取一个时间段内新写入的数据,针对我们的表结构设计,如果没有增量通道的时候,我们能做的就是拿到所有的用户id和taskid进行时间段内的getrange读,这样如果同时的轨迹用户较多,会带来大量的getrange并发访问,而且我们还需要一张额外的表记录用户和轨迹id的关系。如果我们修改表结构,把时间作为第一主键,又会带来严重的数据写入尾部热点,数据分布不均匀等问题。
那么我们的架构就由以前的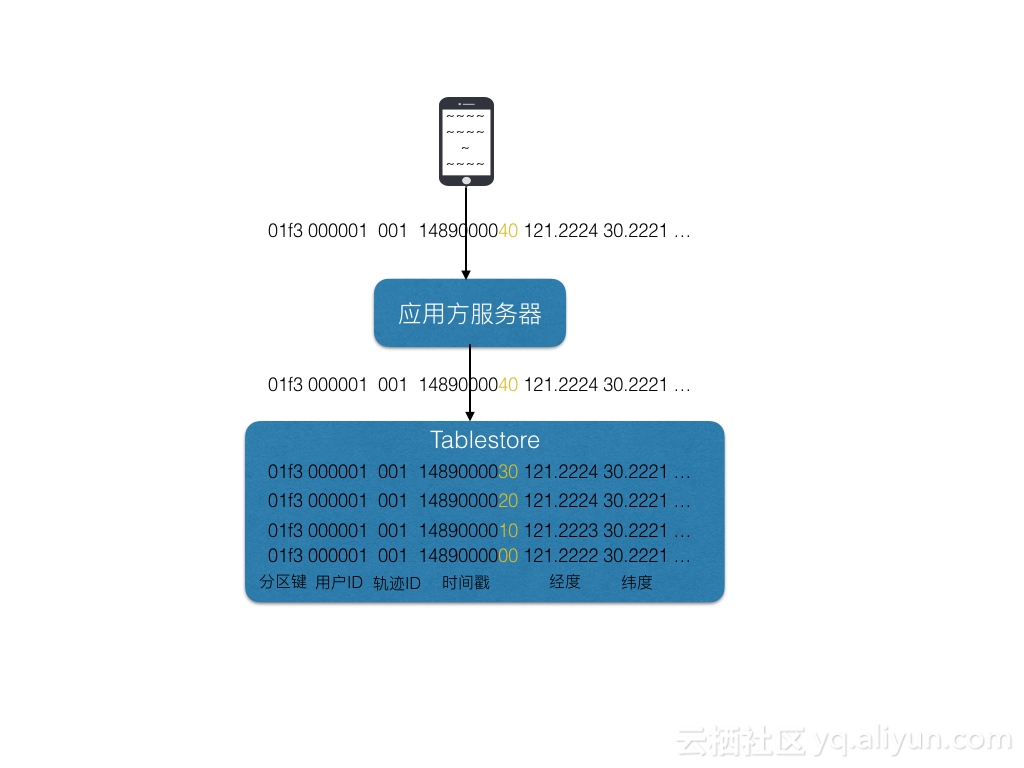 加上大量的range读变为了下图的基于增量获取:
加上大量的range读变为了下图的基于增量获取: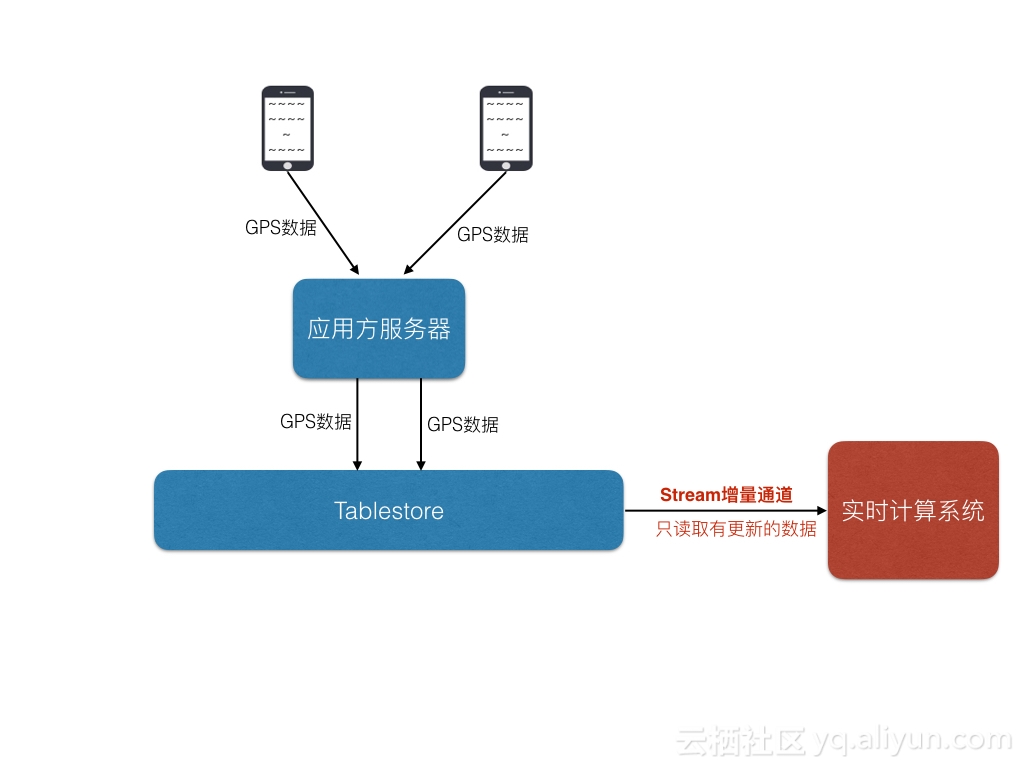
Stream 的数据返回格式
当你使用我们的Stream APi读取增量数据的时候上面的数据会以下面的形式返回,我们以Go Sdk为例返回如下格式的Stream record。
record 0: {"Type":"PutRow", "PrimaryKey":{[{"Name": "pk1", "Value": "04fc"} {"Name": "pk2", "Value": "000001"} {"Name": "pk3", "Value": "001"} {"Name": "pk4", "Value": "%!s(int64=1495246210)"}]}, "Info":{"Epoch":0, "Timestamp": 1503555067832234, "RowIndex": 1}, "Columns":[{"Name":"longitude", "Type":"Put", "Timestamp":1503555067833, "Value":1e+02} {"Name":"latitude", "Type":"Put", "Timestamp":1503555067833, "Value":30.2583277934} {"Name":"brand", "Type":"Put", "Timestamp":1503555067833, "Value":BMW} {"Name":"speed", "Type":"Put", "Timestamp":1503555067833, "Value":25} {"Name":"wind_speed", "Type":"Put", "Timestamp":1503555067833, "Value":2} {"Name":"temperature", "Type":"Put", "Timestamp":1503555067833, "Value":20} {"Name":"distance", "Type":"Put", "Timestamp":1503555067833, "Value":8000}]}
record 1: {"Type":"PutRow", "PrimaryKey":{[{"Name": "pk1", "Value": "04fc"} {"Name": "pk2", "Value": "000001"} {"Name": "pk3", "Value": "001"} {"Name": "pk4", "Value": "%!s(int64=1495246310)"}]}, "Info":{"Epoch":0, "Timestamp": 1503555068082609, "RowIndex": 1}, "Columns":[{"Name":"longitude", "Type":"Put", "Timestamp":1503555068083, "Value":1e+02} {"Name":"latitude", "Type":"Put", "Timestamp":1503555068083, "Value":30.2583277934} {"Name":"brand", "Type":"Put", "Timestamp":1503555068083, "Value":BMW} {"Name":"speed", "Type":"Put", "Timestamp":1503555068083, "Value":25} {"Name":"wind_speed", "Type":"Put", "Timestamp":1503555068083, "Value":2} {"Name":"temperature", "Type":"Put", "Timestamp":1503555068083, "Value":20} {"Name":"distance", "Type":"Put", "Timestamp":1503555068083, "Value":8001}]}
我们可以发现,表格的一次操作对应Stream的一条记录,记录中会涵盖这次操作的类型,操作的主键以及修改列的内容。有了这些数据我们可以方便做以下事情:
- 将数据做清洗写入另一张TableStore表
- 将数据写入流计算平台,做实时计算分析
- 将数据写入MaxCompute做进行分析
下面罗列下我们目前有如下几种方式可以读区表格存储的增量数据:
- SDK直接访问,目前我们的Java SDK和Go SDK已经支持Stream的Api,具体的使用可以参考Java Stream 示例和Go Stream 示例
- DATAX 离线读取stream数据到odps,具体使用参考DATAX 访问TableStore增量
- 基于Stream Client,用户自己开发实时数据通道将数据导出至不同的数据源。使用可以参考Stream Client使用
- Stream对接FC,通过FC触发数据处理逻辑。 即将发布,敬请期待
下面我们就用外卖订单系统为例再说明下Stream如何可以方便我们简化,高效的实现我们的应用。
外卖订单系统
场景描述
现在外卖行业非常火热,几家大厂都在角逐这个领域。而外卖也确实给我们的日常生活带来的很多便利,那如何基于表格存储打造一款高效的外卖应用呢,下面我们来详细介绍下。
系统特点
很多外卖会在不同时间有明显的波峰波谷,例如食品外卖,三餐点和夜宵时间点会有明显的波峰。那么表格存储这类海量高性能弹性计费的数据库产品就非常适合。除此之外,外卖系统还要基于一个区域内所有用户的下单情况做一个做优化的配送,实现效率最优,那么这样的系统我们如何设计表结构呢。
表结构设计
表1 订单表
| 主键顺序 | 名称 | 类型 | 值 | 备注 |
|---|---|---|---|---|
| 1 | partition_key | string | md5(user_id)前四位 | 为了负载均衡 |
| 2 | user_id | string/int | 用户id | 可以是字符串也可以是长整型数字 |
| 3 | timestamp | int | 时间戳 | 使用长整型,64位,足够保存毫秒级别的时间戳 |
| 4 | order_id | string/int | 订单Id | 可以使字符串也可以是长整型数字 |
表2 配送表
| 主键顺序 | 名称 | 类型 | 值 | 备注 |
|---|---|---|---|---|
| 1 | partition_key | string | md5(user_id)前四位 | 为了负载均衡 |
| 2 | user_id | string/int | 配送员id | 可以是字符串也可以是长整型数字 |
| 3 | delivery_id | int | 配送序列 | 使用长整型,基于表格存储主键自增列 |
数据存储示例
设计好表结构后,我们看下具体如何存储:
订单表原始数据是:
2017/5/20 10:12:20小王下了订单,订单号10005,购买了两串烤肉和一杯咖啡,总共支付来51元,收获地址是西湖区XXX路XX号。
配送表原始数据是:
2017/5/20 10:12:20配送员小李收到配送订单信息,订单号10005,购买了两串烤肉和一杯咖啡,收获地址是西湖区XXX路XX号。
| part_key | user_id | timestamp | order_id | merchant_id | commodity | price | address | payment_type | status |
|---|---|---|---|---|---|---|---|---|---|
| 01f3 | 000001 | 1495246210 | 10005 | 黑暗料理 | 2烤肉,1咖啡 | 51 | 西湖区XXX路XX号 | alipay | 等待配送 |
| part_key | user_id | delivery_id | order_id | merchant_id | commodity | price | address | payment_type | status |
|---|---|---|---|---|---|---|---|---|---|
| 01f3 | 000001 | 1495249230 | 10005 | 黑暗料理 | 2烤肉,1咖啡 | 51 | 西湖区XXX路XX号 | alipay | 配送中 |
主键
订单表
- part_key:第一个主键,分区建,主要是为了负载均衡,保证数据可以均匀分布在所有机器上,提高并发度和性能。如果业务主键user_id可以保证均匀分布,那么可以不需要这个主键。
- user_id:第二个主键,用户ID,可以是字符串也可以是数字,唯一标识一个用户。
- timestamp:第三个主键,时间戳,表示某一个时刻,单位可以是秒或者毫秒,用来表示用户订单的时间戳。在这里放置时间,是因为系统往往需要查询某个用户一段时间内的所有订单信息。
- order_id:第四个主键,订单号。
- 至此,上述四个主键可以唯一确定某一个用户在某一个时间点下的一个订单。
配送表
- part_key:第一个主键,分区建,主要是为了负载均衡,保证数据可以均匀分布在所有机器上,提高并发度和性能。如果业务主键user_id可以保证均匀分布,那么可以不需要这个主键。
- user_id:第二个主键,配送员ID,可以是字符串也可以是数字,唯一标识一个用户。
- delivery_id:第三个主键,配送号,注意不是用户的订单号,这一列使用自增列,配送员的客户端可以根据这个id拉去更新的配送信息。
- 至此,上述三个主键可以获取一个配送订单的详细信息。
属性列
订单表
- merchant_id :商家id
- commodity:商品内容。
- price:订单价格。
- address: 配送地址
- payment_type:用户支付类型。
- status:订单的状态。
配送表
- order_id :订单id
- commodity:商品内容。
- price:订单价格。
- address: 配送地址
- payment_type:用户支付类型。
- status:订单的状态。
由于表格存储的分区键可以在数据访问增加时进行分裂,当我们有百万用户同时在高峰期下单时我们可以分裂出较多的分区轻松应对每秒数十万甚至数百万的新增订单。有了这样的一个订单存储系统后,如何衔接我们的派单系统呢,这时候我们就可以使用增量功能,把近期的订单信息导入排单系统进行线路优化计算。前面我们也提到了外卖订单的伸缩特性,所以我们推荐使用函数计算进行订单的派送计算,我们表格存储Stream对接函数计算的功能也即将上线,届时我们是需要一些配置就可以打通表格存储和函数计算这两款全托管完全弹性计费的存储,计算产品。让我们的外卖订单飞的再快一点吧。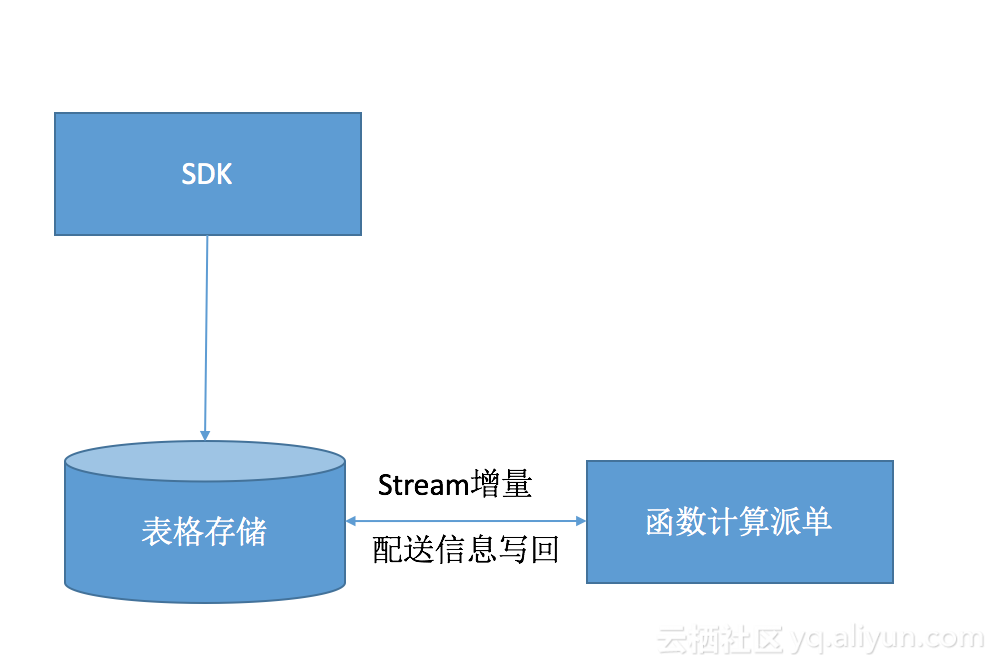
谢谢使用表格存储,欢迎扫码加群讨论
