我们在用缓存的时候,不管是Redis或者Memcached,基本上会通用遇到以下三个问题:
- 缓存穿透
- 缓存并发
- 缓存失效
一、缓存穿透
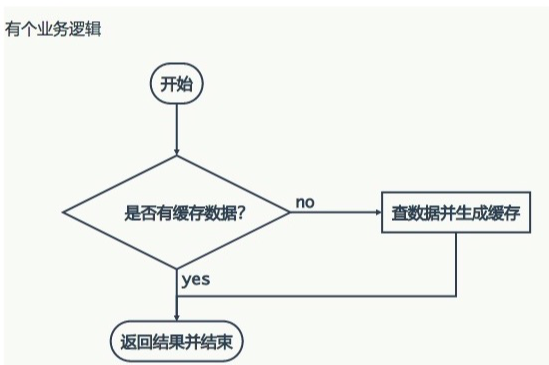


注:
上面三个图会有什么问题呢?
我们在项目中使用缓存通常都是先检查缓存中是否存在,如果存在直接返回缓存内容,如果不存在就直接查询数据库然后再缓存查询结果返回。这个时候如果我们查询的某一个数据在缓存中一直不存在,就会造成每一次请求都查询DB,这样缓存就失去了意义,在流量大时,可能DB就挂掉了。
那这种问题有什么好办法解决呢?
要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
有一个比较巧妙的作法是,可以将这个不存在的key预先设定一个值。
比如,”key” , “&&”。
在返回这个&&值的时候,我们的应用就可以认为这是不存在的key,那我们的应用就可以决定是否继续等待继续访问,还是放弃掉这次操作。如果继续等待访问,过一个时间轮询点后,再次请求这个key,如果取到的值不再是&&,则可以认为这时候key有值了,从而避免了透传到数据库,从而把大量的类似请求挡在了缓存之中。
二、缓存并发
有时候如果网站并发访问高,一个缓存如果失效,可能出现多个进程同时查询DB,同时设置缓存的情况,如果并发确实很大,这也可能造成DB压力过大,还有缓存频繁更新的问题。
我现在的想法是对缓存查询加锁,如果KEY不存在,就加锁,然后查DB入缓存,然后解锁;其他进程如果发现有锁就等待,然后等解锁后返回数据或者进入DB查询。
这种情况和刚才说的预先设定值问题有些类似,只不过利用锁的方式,会造成部分请求等待。
三、缓存失效
引起这个问题的主要原因还是高并发的时候,平时我们设定一个缓存的过期时间时,可能有一些会设置1分钟啊,5分钟这些,并发很高时可能会出在某一个时间同时生成了很多的缓存,并且过期时间都一样,这个时候就可能引发一当过期时间到后,这些缓存同时失效,请求全部转发到DB,DB可能会压力过重。
那如何解决这些问题呢?
其中的一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
我们讨论的第二个问题时针对同一个缓存,第三个问题时针对很多缓存。
总结来看:
1、缓存穿透:查询一个必然不存在的数据。比如文章表,查询一个不存在的id,每次都会访问DB,如果有人恶意破坏,很可能直接对DB造成影响。
2、缓存失效:如果缓存集中在一段时间内失效,DB的压力凸显。这个没有完美解决办法,但可以分析用户行为,尽量让失效时间点均匀分布。
当发生大量的缓存穿透,例如对某个失效的缓存的大并发访问就造成了缓存雪崩。
四、大家提问汇总
1、问题1:
如何解决DB和缓存一致性问题?
答:当修改了数据库后,有没有及时修改缓存。这种问题,以前有过实践,修改数据库成功,而修改缓存失败的情况,最主要就是缓存服务器挂了。而因为网络问题引起的没有及时更新,可以通过重试机制来解决。而缓存服务器挂了,请求首先自然也就无法到达,从而直接访问到数据库。那么我们在修改数据库后,无法修改缓存,这时候可以将这条数据放到数据库中,同时启动一个异步任务定时去检测缓存服务器是否连接成功,一旦连接成功则从数据库中按顺序取出修改数据,依次进行缓存最新值的修改。
2、问题2:
问下缓存穿透那块!例如,一个用户查询文章,通过ID查询,按照之前说的,是将缓存的KEY预先设置一个值,,如果通过ID插过来,发现是预先设定的一个值,比如说是“&&”,那之后的继续等待访问是什么意思,这个ID什么时候会真正被附上用户所需要的值呢?
答:我刚说的主要是咱们常用的后面配置,前台获取的场景。前台无法获取相应的key,则等待,或者放弃。当在后台配置界面上配置了相关key和value之后,那么以前的key &&也自然会被替换掉。你说的那种情况,自然也应该会有一个进程会在某一个时刻,在缓存中设置这个ID,再有新的请求到达的时候,就会获取到最新的ID和value。
3、问题3:
其实用redis的话,那天看到一个不错的例子,双key,有一个当时生成的一个附属key来标识数据修改到期时间,然后快到的时候去重新加载数据,如果觉得key多可以把结束时间放到主key中,附属key起到锁的功能。
答:这种方案,之前我们实践过。这种方案会产生双份数据,而且需要同时控制附属key与key之间的关系,操作上有一定复杂度。
4、问题4:
多级缓存是什么概念呢?
答:多级缓存就像我今天之前给大家发的文章里面提到了,将ehcache与redis做二级缓存,就像我之前写的文章 http://www.jianshu.com/p/2cd6ad416a5a 提到过的。但同样会存在一致性问题,如果我们需要强一致性的话,缓存与数据库同步是会存在时间差的,所以我们在具体开发的过程中,一定要根据场景来具体分析,二级缓存更多的解决是,缓存穿透与程序的健壮性,当集中式缓存出现问题的时候,我们的应用能够继续运行。