对一些应用场景而言,需要实时收集公网数据,例如移动端,HTML网页,PC、服务器、硬件设备、摄像头等实时数据进行处理。
在传统的架构中,一般通过前端服务器+Kafka这样的搭配来实现如上的功能。现在日志服务的LogHub功能能够代替这类架构,并提供更稳定、低成本、弹性、安全的解决方案。我们来比较下:
场景
公网有移动端、外部服务器、网页和设备数据进行采集。采集完成后需要进行实时计算、数据仓库等数据应用。
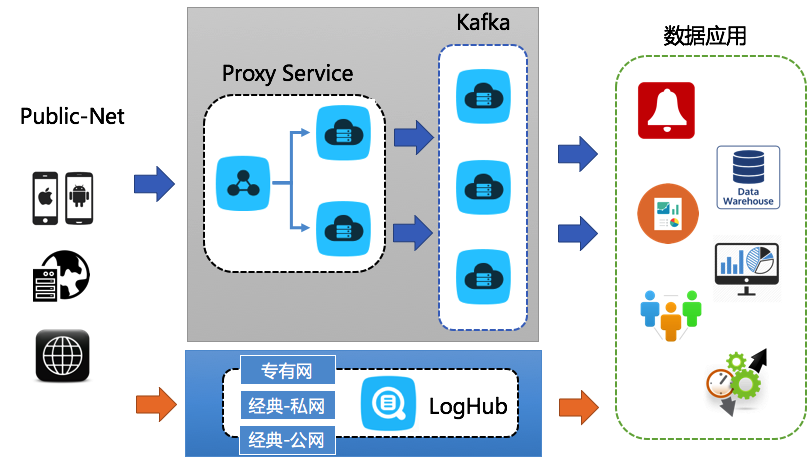
方案1:前端服务器+Kafka
由Kafka不提供Resful协议,更多是在集群内使用。因此一般需要架设Nginx服务器做公网代理,再通过Logstash、或API通过Nginx写Kafka等消息中间件。
需要设施为:
| 设施 | 数目 | 配置 | 作用 | 价格 |
|---|---|---|---|---|
| ECS服务器 | 2台 | 1核2GB | 前端机、负载均衡,互备 | 108 元/台*M |
| SLB | 1台 | 标准 | 按量计费实例 | 14.4 元/Month (租赁) + 0.8元/GB (流量) |
| Kafka / ZK | 3台 | 1核2GB | 数据写入并处理 | 108 元/台*M |
方案2:使用LogHub
通过Mobile SDK、Logtail、Web Tracking JS直接写入LogHub EndPoint。
需要设施为:
| 设施 | 作用 | 价格 |
|---|---|---|
| LogHub | 实时数据采集 | <0.2元/GB,参见计费规则 |
场景对比
场景1:一天10GB数据采集,大约一百万次写请求。( 这里10GB是压缩后,实际前数据大小一般为50GB-100GB左右)
方案1
--------------
SLB 租赁:0.02 24 30 = 14.4 元
SLB 流量:100.830 = 240 元
ECS 费用:108 * 2 = 216
Kafka ECS: 免费,假设与其他服务公用
共计:484.8 元 / 月
方案2:
--------------
LogHub流量:10 0.2 3- = 60 元
LogHub请求次数:0.12 (假设一天100W请求)* 30 = 3.6 元
共计:63.6 元
场景2:一天1TB数据采集,大约一亿次写请求
方案1
--------------
SLB 租赁:0.02 24 30 = 14.4 元
SLB 流量:1000 0.8 30 = 24000 元
ECS 费用:108 * 2 = 216
Kafka ECS: 免费,假设与其他服务公用
共计:24230.4 元 / 月
方案2:
--------------
LogHub流量:1000 0.15 30 = 4500 元 (阶梯计价)
LogHub请求次数:0.12 100(假设一天1亿请求) 30 = 360 元
共计:4860 元 / 月
方案比较
从以上两个场景可以看到,使用Loghub进行公网数据采集成本是非常有竞争力的。除此之外,和方案1相比还有其他优势:
- 弹性伸缩:MB-PB/Day 间流量随意控制
- 丰富权限控制:通过ACL控制读写权限
- 支持HTTPS:传输加密
- 日志投递免费:不需要额外开发就能与数据仓库对接
- 详尽监控数据:让你清楚业务情况
- 丰富SDK与上下游对接:和Kafka一样拥有完整的下游对接能力,和阿里云及开源产品深度整合
有兴趣可以参见日志服务主页体验该服务。
时间: 2024-09-08 11:17:09