【DG】[三思笔记]一步一步学DataGuard
它有无数个名字,有人叫它dg,有人叫它数据卫士,有人叫它data guard,在oracle的各项特性中它有着举足轻理的地位,它就是(掌声)......................Oracle Data Guard。而对于我而言,我一定要亲切的叫它:DG(注:主要是因为打着方便)。
不少未实际接触过dg的初学者可能会下意识以为dg是一个备份恢复的工具。我要说的是,这种形容不完全错,dg拥有备份的功能,某些情况下它甚至可以与primary数据库完全一模一样,但是它存在的目的并不仅仅是为了恢复数据,应该说它的存在是为了 确保企业数据的高可用性,数据保护以及灾难恢复 (注意这个字眼,灾难恢复) 。dg提供全面的服务包括:创建,维护,管理以及监控standby数据库 , 确保数据安全 , 管理员可以通过将一些操作转移到standby数据库执行的方式改善数据库性能 。后面这一长串大家可以把它们理解成形容词,千万不要被其花哨的修饰所迷惑,要抓住重点,要拥有透明现象看本质的能力,如果没有那就要努力学习去拥有,下面我来举一个例子,比如我们夸人会说它聪明勇敢善良等等,这些就属于形容词,不重要,重点在于我们究竟想形容这个人是好人还是坏人。然后再回来看看oracle对dg功能上的形容,数据保护和灾难恢复应该都可以归结为高可用性,那么我们可以清晰的定位dg的用途了,就是构建高可用的企业数据库应用环境。
一、 Data Guard配置(Data Guard Configurations)
Data Guard是一个集合,由一个primary数据库(生产数据库)及一个或多个standby数据库(最多9个)组成。组成Data Guard的数据库通过Oracle Net连接,并且有可能分布于不同地域。只要各库之间可以相互通信,它们的物理位置并没有什么限制,至于操作系统就更无所谓了(某些情况下),只要支持oracle就行了。
你即可以通过命令行方式管理primary数据库或standby数据库,也可以通过Data Guard broker提供的专用命令行界面(DGMGRL),或者通过OEM图形化界面管理。
1. Primary 数据库
前面提到,Data Guard包含一个primary数据库即被大部分应用访问的生产数据库,该库即可以是单实例数据库,也可以是RAC。
2. Standby 数据库
Standby数据库是primary数据库的复制(事务上一致)。在同一个Data Guard中你可以最多创建9个standby数据库。一旦创建完成,Data Guard通过应用primary数据库的redo自动维护每一个standby数据库。Standby数据库同样即可以是单实例数据库,也可以是RAC结构。关于standby数据库,通常分两类:逻辑standby和物理standby,如何区分,两类各有什么特点,如何搭建,这方面内容就是后面的章节主要介绍的,在这里呢三思先简单白话一下:
l 逻辑standby
就像你请人帮你素描画像,基本器官是都会有的,这点你放心,但是各器官位置啦大小啦肤色啦就不一定跟你本人一致了。
l 物理standby
就像拿相机拍照,你长什么样出来的照片就是什么样,眼睛绝对在鼻子上头。或者说就像你去照镜子,里外都是你,哇哈哈。具体到数据库就是不仅文件的物理结构相同,甚至连块在磁盘上的存储位置都是一模一样的(默认情况下)。
为什么会这样呢?这事就得从同步的机制说起了。逻辑standby是通过接收primary数据库的redo log并转换成sql语句,然后在standby数据库上执行SQL语句(SQL Apply)实现同步,物理standby是通过接收并应用primary数据库的redo log以介质恢复的方式(Redo Apply)实现同步。
另外,不知道大家是否注意到形容词上的细节:对于相机拍照而言,有种傻瓜相机功能强大而操作简便,而对于素描,即使是最简单的画法,也需要相当多的练习才能掌握。这个细节是不是也说明逻辑standby相比物理standby需要操作者拥有更多的操作技能呢?
二、 Data Guard服务(Data Guard Services)
l REDO传输服务(Redo Transport Services)
控制redo数据的传输到一个或多个归档目的地。
l Log应用服务(Log Apply Services)
应用redo数据到standby数据库,以保持与primary数据库的事务一致。redo数据即可以从standby数据库的归档文件读取,也可直接应用standby redo log文件(如果实时应用打开了的话)。
l 角色转换服务(Role Transitions)
Dg中只有两种角色:primary和standby。所谓角色转换就是让数据库在这两个角色中切换,切换也分两种:switchover和failover
switchover:转换primary数据库与standby数据库。switchover可以确保不会丢失数据。
failover:当primary数据库出现故障并且不能被及时恢复时,会调用failover将一个standby数据库转换为新的primary数据库。在最大保护模式或最高可用性模式下,failover可以保证不会丢失数据。
注:上述各概念简要了解即可,这里写的太简单,不要咬文嚼字,不然你会越看越糊涂,相关服务在后面章节将会有详细介绍,不仅有直白的描述,还会有示例,再加上浅显的图片,就算你一看不懂,再看肯定懂:)
三、 Data Guard保护模式(Data Guard Protection Modes)
对于Data Guard而言,其生存逻辑非常简单,好好活,做有意义的事,做黑多黑多有意义的事:)
由于它提供了三种数据保护的模式,我们又亲切的叫它:有三模:
l 最大保护(Maximum protection):
这种模式能够确保绝无数据丢失。要实现这一步当然是有代价的,它要求所有的事务在提交前其redo不仅被写入到本地的online redo log,还要同时提交到standby数据库的standby redo log,并确认redo数据至少在一个standby数据库可用(如果有多个的话),然后才会在primary数据库上提交。如果出现了什么故障导致standby数据库不可用的话,primary数据库会被shutdown。
l 最高性能(Maximum performance):
这种模式提供在不影响primary数据库性能前提下最高级别的数据保护策略。事务可以随时提交,当前primary数据库的redo数据也需要至少写入一个standby数据库,不过这种写入可以是不同步的。
如果网络条件理想的话,这种模式能够提供类似最高可用性的数据保护而仅对primary数据库有轻微的性能影响。
l 最高可用性(Maximum availability):
这种模式提供在不影响primary数据库可用前提下最高级别的数据保护策略。其实现方式与最大保护模式类似,也是要求所有事务在提交前必须保障redo数据至少在一个standby数据库可用,不过与之不同的是,如果出现故障导入无法同时写入standby数据库redo log,primary数据库并不会shutdown,而是自动转为最高性能模式,等standby数据库恢复正常之后,它又会再自动转换成最高可用性模式。
最大保护及最高可用性需要至少一个standby数据库redo数据被同步写入。三种模式都需要指定LOG_ARCHIVE_DEST_n初始化参数。LOG_ARCHIVE_DEST_n很重要,你看着很眼熟是吧,我保证,如果你完完整整学完dataguard,你会对它更熟。
四、 Data Guard优点总结
l 灾难恢复及高可用性
l 全面的数据保护
l 有效利用系统资源
l 在高可用及高性能之间更加灵活的平衡机制
l 故障自动检查及解决方案
l 集中的易用的管理模式
l 自动化的角色转换
经常开篇的灌输,相信大家已经看的出来,上面这几条都是形容词,看看就好,记住更好,跟人穷白活的时候通常能够用上:)
同一个Data Guard配置包含一个 Primary 数据库和最多九个 Standby 数据库。 Primary的创建就不说了,Standby数据库初始可以通过primary数据库的备份创建。一旦创建并配置成standby后,dg负责传输primary数据库redo data到standby数据库,standby数据库通过应用接收到的redo data保持与primary数据库的事务一致。
一、 Standby数据库类型
前章我们简单介绍了Standby数据库,并且也知道其通常分为两类:物理standby和逻辑standby,同时也简短的描述了其各自的特点,下面我们就相关方面进行一些稍深入的研究:
1. 物理standby
我们知道物理standby与primary数据库完全一模一样(默认情况下,当然也可以不一样,事无绝对嘛),Dg通过redo应用维护物理standby数据库。通常在不应用恢复的时候,可以以read-only模式打开,如果数据库指定了快速恢复区的话,也可以被临时性的置为read-write模式。
l Redo应用
物理standby通过应用归档文件或直接从standby系统中通过oracle恢复机制应用redo文件。恢复操作属于块对块的应用(不理解?那就理解成块复制,将redo中发生了变化的块复制到standby)。如果正在应用redo,数据库不能被open。
Redo应用是物理standby的核心,务必要搞清楚其概念和原理,后续将有专门章节介绍。
l Read-only模式
以read-only模式打开后,你可以在standby数据库执行查询,或者备份等操作(变相减轻primary数据库压力)。此时standby数据库仍然可以继续接收redo数据,不过并不会触发操作,直到数据库恢复redo应用。也就是说read-only模式时不能执行redo应用,redo应用时数据库肯定处于未打开状态。如果需要的话,你可以在两种状态间转换,比如先应用redo,然后read-only,然后切换数据库状态再应用redo,呵呵,人生就是循环,数据库也是一样。
l Read-write模式
如果以read-write模式打开,则standby数据库将暂停从primary数据库接收redo数据,并且暂时失去灾难保护的功能。当然,以read-write模式打开也并非一无是处,比如你可能需要临时调试一些数据,但是又不方便在正式库操作,那就可以临时将standby数据库置为read-write模式,操作完之后将数据库闪回到操作前的状态(闪回之后,Data Guard会自动同步,不需要重建standby)。
l 物理standby特点
? 灾难恢复及高可用性
物理standby提供了一个健全而且极高效的灾难恢复及高可用性的解决方案。更加易于管理的switchover/failover角色转换及最更短的计划内或计划外停机时间。
? 数据保护
应用物理standby数据库,Dg能够确保即使面对无法预料的灾害也能够不丢失数据。前面也提到物理standby是基于块对块的复制,因此对象、语句统统无关,primary数据库上有什么,物理standby也会有什么。
? 分担primary数据库压力
通过将一些备份任务、仅查询的需求转移到物理standby,可以有效节省primary数据库的cpu以及i/o资源。
? 提升性能
物理standby所使用的redo应用技术使用最底层的恢复机制,这种机制能够绕过sql级代码层,因此效率最高。
2. 逻辑standby
逻辑standby是逻辑上与primary数据库相同,结构可以不一致。逻辑standby通过sql应用与primary数据库保持一致,也正因如此,逻辑standby可以以read-write模式打开,你可以在任何时候访问逻辑standby数据库。同样有利也有弊,逻辑standby对于某些数据类型以及一些ddl,dml会有操作上的限制。
l 逻辑standby的特点:
除了上述物理standby中提到的类似灾难恢复,高可用性及数据保护等之外,还有下列一些特点:
? 有效的利用standby的硬件资源
除灾难恢复外,逻辑standby数据库还可用于其它业务需求。比如通过在standby数据库创建额外的索引、物化视图等提高查询性能并满足特定业务需要。又比如创建新的schema(primary数据库并不存在)然后在这些schema中执行ddl或者dml操作等。
? 分担primary数据库压力
逻辑standby数据库可以在更新表的时候仍然保持打开状态,此时这些表可同时用于只读访问。这使得逻辑standby数据库能够同时用于数据保护和报表操作,从而将主数据库从那些报表和查询任务中解脱出来,节约宝贵的 CPU和I/O资源。
? 平滑升级
比如跨版本升级啦,打小补丁啦等等,应该说应用的空间很大,而带来的风险却很小(前提是如果你拥有足够的技术实力。另外虽然物理standby也能够实现一些升级操作,但如果跨平台的话恐怕就力不从心,所以此项就不做为物理standby的特点列出了),我个人认为这是一种值的推荐的在线的滚动的平滑的升级方式。
二、 Data Guard操作界面(方式)
做为oracle环境中一项非常重要的特性,oracle提供了多种方式搭建、操作、管理、维护Data Guard配置,比如:
l OEM(Oracle Enterprise Manager)
Orcale EM提供了一个窗口化的管理方式,基本上你只需要点点鼠标就能完全dg的配置管理维护等操作(当然三思仍然坚持一步一步学rman中的观点,在可能的情况下,尽可能不依赖视窗化的功能,所以这种操作方式不做详细介绍),其实质是调用oracle为dg专门提供的一个管理器:Data Guard Broker来实施管理操作。
l Sqlplus命令行方式
命令行方式的管理,本系列文章中主要采用的方式。不要一听到命令行就被吓倒,data guard的管理命令并不多,你只需要在脑袋瓜里稍微挪出那么一小点地方用来记忆就可以了。
l DGMGRL(Data Guard broker命令行方式)
就是Data Guard Broker,不过是命令行方式的操作。
l 初始化参数文件
我感觉不能把参数化参数视为一种操作方式,应该说,在这里,通过初始化参数,更多是提供更灵活的Data Guard配置。
三、 Data Guard 的软硬件需求
1、 硬件及操作系统需求
l 同一个Data Gurid配置中的所有oracle数据库必须运行于相同的平台。比如inter架构下的32位linux系统可以与inter架构下的32位linux系统组成一组Data Guard。另外,如果服务器都运行于32位的话,64位HP-UX也可以与32位HP-UX组成一组Data Guard。
l 不同服务器的硬件配置可以不同,比如cpu啦,内存啦,存储设备啦,但是必须确保standby数据库服务器有足够的磁盘空间用来接收及应用redo数据。
l primary数据库和standby数据库的操作系统必须一致,不过操作系统版本可以略有差异,比如(linux as4&linux as5),primary数据库和standby数据库的目录路径也可以不同。
2、 软件需求
l Data Guard是Oracle企业版的一个特性,明白了吧,标准版是不支持地。
l 通过Data Guard的SQL应用,可以实现滚动升级服务器数据库版本(要求升级前数据库版本不低于10.1.0.3)。
l 同一个Data Guard配置中所有数据库初始化参数:COMPATIBLE的值必须相同。
l P rimary数据库必须运行于归档模式 ,并且务必确保在primary数据库上打开FORCE LOGGING,以避免用户通过nologging等方式避免写redo造成对应的操作无法传输到standby数据库。
l P rimary和standby数据库均可应用于单实例或RAC架构下 ,并且同一个data guard配置可以混合使用逻辑standby和物理standby 。
l Primary和standby数据库可以在同一台服务器,但需要注意各自的数据文件存放目录,避免重写或覆盖。
l 使用具有sysdba系统权限的用户管理primary和standby数据库。
l 建议数据库必须采用相同的存储架构。比如存储采用ASM/OMF的话,那不分primarty或是standby也都需要采用ASM/OMF。
另外还有很重要一点,注意各服务器的时间设置,不要因为时区/时间设置的不一置造成同步上的问题 。
四、 分清某某REDO LOGS(Online Redo Logs, Archived Redo Logs, Standby Redo Logs)
黑多黑多的redo,想必诸位早已晕头并吐过多次了吧。哎,说实话我描述的时候也很痛苦。这块涉及到中英文之间的意会。我又不能过度白话,不然看完我这篇文章再看其它相关文档的相关概念恐怕您都不知道人家在说什么,这种误人子弟的事情咱不能干(也许干过,但主观意愿上肯定是不想的),更何况咱也是看各乱杂七杂八文档被误过XXXXXXXXXXXXXXXXX次(X=9),深受其害,坚决不能再让跟俺一样受尽苦楚,历经磨难的DDMM们因为看俺的文档被再次一百遍啊一百遍。
但是已到关键时刻,此处不把redo混清楚,后头就得被redo混了,所以这里我要用尽我全部的口水+目前为止我所有已成体系的认识再给大家浅显的白话一回。注:基础概念仅一笔带过,水太大了也不好,要响应胡书记号召,书写节约型笔记。
REDO:中文直译是重做,与UNDO对应(天哪又扯出个概念,你看不见我看不见我看不见我)。重做什么?为什么要重做呢?首先重做是oracle对操作的处理机制,我们操作数据(增册改)并非直接反映到数据文件,而是先被记录(就是online redo log喽),等时机合适的时候,再由相应的进程操作提交到数据文件(详细可见: 数据写过程中各项触发条件及逻辑)。你是不是想说如果把所有的online redo logs都保存下来,不就相当于拥有了数据库做过的所有操作了吗?en,我可以非常负责任的告诉你,你说的对,oracle跟你想到一块去了并且也将其实现了,这就是archived redo logs,简称archive log即归档日志。我们再回来看Data Guard,由于standby数据库的数据通常都来自于primary数据库,怎么来的呢,通过RFS进程接收primary数据库的redo,保存在本地,就是Standby redo logs喽,然后standby数据库的ARCn再将其写入归档,就是standby服务器的archived redo logs。保存之后数据又是怎么生成的呢,两种方式,物理standby通过redo应用,逻辑standby通过sql应用,不管是哪种应用,应用的是什么呢?是redo log中的内容(默认情况下应用archived redo logs,如果打开了实时应用,则直接从standby redo logs中读取),至于如何应用,那就是redo应用和sql应用机制的事情了(也许后头我们会深入聊一聊这个话题,很复杂也很有趣)。
针对上述内容我们试着总结一下,看看能否得出一些结论:
对于primary数据库和逻辑standby数据库,online redo log文件肯定是必须的,而对于物理standby是否还需要redo log呢?毕竟物理standby通常不会有写操作,所以物理standby应该不会生成有redo数据。为保证数据库的事务一致性必然需要有归档,也就是说不管primary或standby都必须运行于归档模式。
standby redo logs是standby数据库特有的文件(如果配置了的话),就本身的特点比如文件存储特性,配置特性等等都与online redo logs非常类似,不过它存储的是接收自primary数据库的redo数据,而online redo logs中记录的是本机中的操作记录。
上面的描述大家尽可能意会,能够理解最好,理解不了也没关系,我始终认为,只要坚定不移的学习下去,总会水到渠成。下面进入实战章节,先来个简单的,创建物理standby。
一、 准备工作
不管物理standby还是逻辑standby,其初始创建都是要依赖primary数据库,因为这个准备工作中最重要的一部分,就是对primary数据库的配置。
1、 打开Forced Logging模式
将primary数据库置为FORCE LOGGING模式。通过下列语句:
SQL> alter database force logging;
提示:关于FORCE LOGGING
想必大家知道有一些DDL语句可以通过指定NOLOGGING子句的方式避免写redo log(目的是提高速度,某些时候确实有效),指定数据库为FORCE LOGGING模式后,数据库将会记录除临时表空间或临时回滚段外所有的操作而忽略类似NOLOGGING之类的指定参数。如果在执行force logging时有nologging之类的语句在执行,则force logging会等待直到这类语句全部执行。FORCE LOGGING是做为固定参数保存在控制文件中,因此其不受重启之类操作的影响(只执行一次即可),如果想取消,可以通过alter database no force logging语句关闭强制记录。
2、 创建密码文件(如果不存在的话)
需要注意的是,同一个Data Guard配置中所有数据库必须都拥有独立的密码文件,并且必须保证同一个Data Guard配置中所有数据库服务器的SYS用户拥有相同密码以保证redo数据的顺利传输,因为redo传输服务通过认证的网络会话来传输redo数据,而会话使用包含在密码文件中的SYS用户密码来认证。
3、 配置Standby Redo Log
对于最大保护和最高可用性模式,Standby数据库必须配置standby redo log,并且oracle推荐所有数据库都使用LGWR ASYNC模式传输,当然你现在可能还不知道LGWR ASYNC是什么问题,没关系,你很快就会知道了。
Oracle建议你在创建standby时就考虑standby redolog配置的问题。standby redologs与online redologs非常类似,应该说两者只是服务对象不同,其它参数属性甚至操作的命令格式几乎都一样,你在设计standby redologs的时候完全可以借鉴创建online redologs的思路,比如多个文件组啦,每组多个文件冗余之类的。除些之外呢,oracle提供了一些标准的建议如下:
l 确保standby redo log的文件大小与primary数据库online redo log文件大小相同。
这个很好理解的吧,就是为了接收和应用方便嘛。
l 创建适当的日志组
一般而言,standby redo日志文件组数要比primary数据库的online redo日志文件组数至少多一个。推荐standby redo日志组数量基于primary数据库的线程数(这里的线程数可以理解为rac结构中的rac节点数)。
有一个推荐的公式可以做参考:(每线程的日志组数+1)*最大线程数
例如primary数据库有两个线程,每个线程分配两组日志,则standby日志组数建议为6组,使用这个公式可以降低primary数据库实例LGWR进程锁住的可能性。
提示:逻辑standby数据库有可能需要视工作量增加更多的standby redo log文件(或增加归档进程),因为逻辑standby需要同时写online redo log文件。
Standby redo log的操作方式与online redo log几乎一模一样,只不过在创建或删除时需要多指定一个standby关键字,例如添加:
SQL> alter database add standby logfile group 4 ('e:ora10goradatajsspdgSTANDBYRD0 1 .LOG') size 20 M;
删除也同样简单:
SQL> alter database drop standby logfile group 4;
另外,从可靠性方面考虑,建议在primary数据库也创建standby redologs,这样一旦发生切换,不会影响primary做为standby的正常运行。
验证standby redo log文件组是否成功创建
例如:
SQL> SELECT GROUP#,THREAD#,SEQUENCE#,ARCHIVED,STATUS FROM V$STANDBY_LOG;
4、 设置初始化参数
对于primary数据库,需要定义几个primary角色的初始化参数控制redo传输服务,还有几个附加的standby角色的参数需要添加以控制接收redo数据库并应用(switchover/failover后primary/standby角色可能互换,所以建议对于两类角色 相关的 初始化参数都进行配置)。
|
下列参数为primary角色相关的初始化参数: |
|
|
DB_NAME |
注意保持同一个Data Guard中所有数据库DB_NAME相同。 例如:DB_NAME=jssweb |
|
DB_UNIQUE_NAME |
为每一个数据库指定一个唯一的名称,该参数一经指定不会再发生变化,除非你主动修改它。 例如:DB_UNIQUE_NAME=jssweb |
|
LOG_ARCHIVE_CONFIG |
该参数通过DG_CONFIG属性罗列同一个Data Guard中所有DB_UNIQUE_NAME(含primary db及standby db),以逗号分隔 例如:LOG_ARCHIVE_CONFIG='DB_CONFIG=(jssweb,jsspdg)' |
|
CONTROL_FILES |
没啥说的,控制文件所在路径。 |
|
LOG_ARCHIVE_DEST_n |
归档文件的生成路径 。该参数非常重要,并且属性和子参数也特别多(这里不一一列举,后面用到时单独讲解如果你黑好奇,建议直接查询oracle官方文档。Data guard白皮书第14章专门介绍了该参数各属性及子参数的功能和设置)。 例如: LOG_ARCHIVE_DEST_1= 'LOCATION=E:ora10goradatajssweb VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=jssweb' |
|
LOG_ARCHIVE_DEST_STATE_n |
指定参数值为ENABLE,允许redo传输服务传输redo数据到指定的路径。 该参数共拥有4个属性值,功能各不相同。 |
|
REMOTE_LOGIN_PASSWORDFILE |
推荐设置参数值为EXCLUSIVE或者SHARED,注意保证相同Data Guard配置中所有db服务器sys密码相同。 |
|
LOG_ARCHIVE_FORMAT |
指定归档文件格式。 |
|
LOG_ARCHIVE_MAX_PRODUCESSES |
指定归档进程的数量(1-30),默认值通常是4 。 |
|
以下参数为standby角色相关的参数,建议在Primary数据库 的初始化参数中也进行 设置,这样在role transition后(Primary转为Standby)也能正常运行: |
|
|
FAL_SERVER |
指定一个数据库SID,通常该库为primary角色。 例如:FAL_SERVER=jssweb |
|
FAL_CLIENT |
指定一个数据库SID,通常该库为standby角色。 例如:FAL_CLIENT=jsspdg 提示:FAL是Fetch Archived Log的缩写 |
|
DB_FILE_NAME_CONVERT |
在做duplicate复制和传输表空间的时候这类参数讲过很多遍,该参数及上述内容中同名参数功能,格式等完全相同。 |
|
LOG_FILE_NAME_CONVERT |
同上 |
|
STANDBY_FILE_MANAGEMENT |
如果primary数据库数据文件发生修改(如新建,重命名等)则按照本参数的设置在standby中做相应修改。设为AUTO表示自动管理。设为MANUAL表示需要手工管理。 例如:STANDBY_FILE_MANAGEMENT=AUTO |
注意:上面列举的这些参数仅只是对于primary/standby两角色可能会相关的参数,还有一些基础性参数比如*_dest,*_size等数据库相关的参数在具体配置时也需要根据实际情况做出适当修改。
5、 确保数据库处于归档模式
SQL> archive log list;
数据库日志模式 存档模式
自动存档 启用
.......
如果当前primary数据库并未处于归档模式,可通过下列命令将数据库置为归档模式:
SQL> STARTUP MOUNT;
SQL> ALTER DATABASE ARCHIVELOG;
SQL> ALTER DATABASE OPEN;
手把手 的 创建 物理standby
1、 创建备份(手工复制数据文件或通过RMAN) ---primary库操作
2、 创建控制文件 --primary库操作
通过下列语句为standby数据库创建控制文件
SQL> alter database create standby controlfile as 'd:backupjsspdg01.ctl';
注意哟,控制文件通常需要有多份,你要么手工将上述文件复制几份,要么用命令多创建几个出来。另外,创建完控制文件之后到standby数据库创建完成这段时间内,要保证primary数据库不再有结构性的变化(比如增加表空间等等),不然primary和standby同步时会有问题。
3、 创建初始化参数文件
l 创建客户端初始化参数文件
例如:
SQL> create pfile='d:backupinitjsspdg.ora' from spfile;
l 修改初始化参数文件中的参数
根据实际情况修改吧,注意primary和standby不同角色的属性配置,注意文件路径。
4、 复制文件到standby服务器
至少三部分:数据文件,控制文件,修改过的初始化参数文件,注意路径。
5、 配置standby数据库
如果你看过三思之前"一步一步学rman"系列,看过"duplicate复制数据库",或看过"传输表空间复制数据"系列,那么对于创建一个新的数据库应该非常熟悉了,下面再简单描述一下步骤:
1) .创建新的OracleService(windows环境下需要)。
2) .创建密码文件,注意保持密码与primary数据库一致。
3) .配置监听并启动
4) .修改primary和standby的tnsnames.ora,各自增加对应的Net Service Name。
5) .创建服务器端的初始化文件
6、 启动standby
注意哟,咱们前面说过的,物理standby极少情况下可以以read-write模式打开,某些情况下可以以read-only模式打开,所以默认情况下,加载到mount状态即可。
SQL> STARTUP MOUNT;
启动redo应用
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION;
启动实时应用
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT FROM SESSION;
提示:disconnect from session 子句并非必须,该子句用于指定启动完应用后自动退出到命令操作符前,如果不指定的话,当前session就会一直停留处理redo应用,如果想做其它操作,就只能新建一个连接。
7、 停止standby
正常情况下,我们停止也应该是先停止redo应用,可以通过下列语句:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CALCEL;
然后再停止standby数据库
SQL> SHUTDOWN IMMEDIATE;
当然你非要直接shutdown也没问题,dg本来就是用于容灾的,别说你生停standby,就是直接拔电源也不怕。
为了最大的降低硬件需求,此处创建的data guard处于同一台机器,但其创建过程与多机并无区别。做为演示用的示例足够了,我们分两阶段配置,分别是配置primary数据库和配置standby数据库,如下:
一、 Primary数据库配置及相关操作
1、 确认主库处于归档模式
SQL> archive log list;
数据库日志模式 存档模式
自动存档 启用
存档终点 E:ora10goradatajssweb
最早的联机日志序列 148
下一个存档日志序列 150
当前日志序列 150
SQL>
2、 将primary数据库置为FORCE LOGGING模式。通过下列语句:
SQL> alter database force logging;
数据库已更改。
3、 创建standby数据库控制文件
SQL> alter database create standby controlfile as 'd:backupjsspdg01.ctl';
数据库已更改。
4、 创建primary数据库客户端初始化参数文件
注:主要此处修改项较多,为了方便,我们首先创建并修改pfile,然后再通过pfile重建spfile,你当然也可以通过alter system set命令直接修改spfile内容。
SQL> create pfile from spfile;
文件已创建。
将该初始化参数文件复制一份,做为standby数据库的客户端初始化参数文件
SQL> host copy e:ora10gproduct10.2.0db_1databaseinitjssweb.ora d:backupinitjsspdg.ora
已复制 1 个文件。
SQL>
修改客户端初始化参数文件,增加下列内容
DB_UNIQUE_NAME=jssweb
LOG_ARCHIVE_CONFIG='DG_CONFIG=(jssweb,jsspdg)'
LOG_ARCHIVE_DEST_1='LOCATION=E:ora10goradatajssweb VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=jssweb'
LOG_ARCHIVE_DEST_2='SERVICE=jsspdg LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=jsspdg'
LOG_ARCHIVE_DEST_STATE_1=ENABLE
LOG_ARCHIVE_DEST_STATE_2=ENABLE
REMOTE_LOGIN_PASSWORDFILE=EXCLUSIVE
#--------配置standby角色的参数用于角色转换
FAL_SERVER=jss pdg
FAL_CLIENT=jss web
DB_FILE_NAME_CONVERT='oradatajsspdg','oradatajssweb'
LOG_FILE_NAME_CONVERT='oradatajsspdg',' oradata jssweb'
STANDBY_FILE_MANAGEMENT=AUTO
通过pfile重建spfile
SQL> shutdown immediate
...
SQL> create spfile from pfile='initjssweb.ora';
文件已创建。
5、 复制数据文件到standby服务器(方式多样,不详述)
注意需要复制所有数据文件,备份的控制文件及客户端初始化参数文件
6、 配置listener及net service names(方式多样,不详述)。
完之后重启listener:
E:ora10g>lsnrctl stop
E:ora10g>lsnrctl start
通过tnsping测试tnsnames是否正确有效:
E:ora10g>tnsping jssweb
...
Attempting to contact (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = jss)(PORT = 1521)) (CONNECT_
DATA = (SERVER = DEDICATED) (SERVICE_NAME = jssweb)))
OK (30 毫秒)
E:ora10g>tnsping jsspdg
...
Attempting to contact (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = jss)(PORT = 1521)) (CONNECT_
DATA = (SERVER = DEDICATED) (SERVICE_NAME = jsspdg)))
OK (10 毫秒)
二、 Standby数据库配置及相关操作
1、 通过ORADIM创建新的OracleService
2、 创建密码文件,注意保持sys密码与primary数据库一致。
E:ora10g>orapwd file=e:ora10gproduct10.2.0db_1databasePWDjsspdg
.ora password=verysafe entries=30
3、 创建目录
E:ora10gproduct10.2.0adminjsspdg>mkdir adump
4、 复制文件,不做过多描述
5、 修改初始化参数文件
增加下列参数
db_unique_name=jsspdg
LOG_ARCHIVE_CONFIG='DG_CONFIG=(jssweb,jsspdg)'
DB_FILE_NAME_CONVERT='oradatajssweb','oradatajsspdg'
LOG_FILE_NAME_CONVERT='oradatajssweb','oradatajsspdg'
LOG_ARCHIVE_FORMAT=log%t_%s_%r.arc
LOG_ARCHIVE_DEST_1='LOCATION=E:ora10goradatajsspdg VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=jsspdg'
LOG_ARCHIVE_DEST_STATE_1=ENABLE
#---下列参数用于角色切换
LOG_ARCHIVE_DEST_2='SERVICE=jssweb LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=jssweb'
LOG_ARCHIVE_DEST_STATE_2=ENABLE
REMOTE_LOGIN_PASSWORDFILE=EXCLUSIVE
FAL_SERVER=jssweb
FAL_CLIENT=jsspdg
STANDBY_FILE_MANAGEMENT=AUTO
注意同时修改*_dest的路径。
通过该pfile创建spfile
SQL> create spfile from pfile='D:backupinitjsspdg.ora';
文件已创建。
6、 启动standby到mount
SQL> startup mount;
ORACLE 例程已经启动。
Total System Global Area 167772160 bytes
Fixed Size 1289484 bytes
Variable Size 62915316 bytes
Database Buffers 96468992 bytes
Redo Buffers 7098368 bytes
数据库装载完毕。
7、 启动redo应用
SQL> alter database recover managed standby database disconnect from session;
数据库已更改。
8、 查看同步情况
首先连接到primary数据库
SQL> show parameter instance_name;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
instance_name string jssweb
SQL> alter system switch logfile;
系统已更改。
SQL> select max(sequence#) from v$archived_log;
MAX(SEQUENCE#)
--------------
51
连接到standby数据库
SQL> show parameter instance_name;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
instance_name string jsspdg
SQL> select max(sequence#) from v$archived_log;
MAX(SEQUENCE#)
--------------
51
9、 暂停应用
通过下列语句暂停redo应用。
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;
数据库已更改。
注意,此时只是暂时redo应用,并不是停止Standby数据库,standby仍会保持接收只不过不会再应用接收到的归档,直到你再次启动redo应用为止。
哈哈,成功鸟!现在你是不是想知道怎么把standby变成primary呢?接着往下看~~~~~~~~~
第1节的时候我们就提到了角色切换,我们也听说了其操作简单但用途广泛,同时我们也猜测其属于primary与standby之间的互动,那么在primary和standby数据库(之一)上都需要有操作,并且切换又分了:switchover和failover,前者是无损切换,不会丢失数据,而后者则有可能会丢失数据,并且切换后原primary数据库也不再是该data guard配置的一部分了.针对不同standby(逻辑或物理)的处理方式也不尽相同。en,内容也挺多地。我们还是先大概了解下概念,然后再通过实战去印证。
角色转换前的准备工作
l 检查各数据库的初始化参数,主要确认对不同角色相关的初始化参数都进行了正确的配置。
l 确保可能成为primary数据库的standby服务器已经处于archivelog模式。
l 确保standby数据库的临时文件存在并匹配primary数据库的临时文件
l 确保standby数据库的RAC实例只有一个处于open状态。(对于rac结构的standby数据库,在角色转换时只能有一个实例startup。其它rac实例必须统统shutdown,待角色转换结束后再startup)
Switchover :
无损转换,通常是用户手动触发或者有计划的让其自动触发,比如硬件升级啦,软件升级啦之类的。通常它给你带来的工作量非常小并且都是可预计的。其执行分两个阶段,第一步,primary数据库转换为standby角色,第二步,standby数据库(之一)转换为primary角色,primary和standby只是简单的角色互换,这也印证了我们前面关于角色转换是primary/standby互动的猜测。
Failover :
不可预知原因导致primary数据库故障并且短期内不能恢复就需要failover。如果是这种切换那你就要小心点了,有可能只是虚惊一场,甚至连你可能损失的脑细胞的数量都能预估,但如果运气不好又没有完备的备份恢复策略而且primary数据并非处于最大数据保护或最高可用性模式地话,黑黑,哭是没用地,表太伤心了,来,让三思GG安慰安慰你,这种情况下呢丢失数据有可能是难免的,并且如果其故障未能修复,那它甚至连快速修复成为standby的机会也都失去了呐,咦,你脑门怎么好像在往外冒水,难道是强效净肤液,你的脸也忽然好白皙哟~~~~
在执行failover之前,尽可能将原primary数据库的可用redo都复制到standby数据库。
注意,如果要转换角色的standby处于maximum protection模式,需要你首先将其切换为maximum performance模式(什么什么,你不知道怎么转换模式?oooo,对对,我们还没有操作过,这块并不复杂,接下来会通过专门章节讨论),这里先提供透露一下,转换standby数据库到MAXIMIZE PERFORMANCE执行下列SQL即可:
SQL> ALTER DATABASE SET STANDBY DATABASE TO MAXIMIZE PERFORMANCE;
等standby切换为新的primary之后,你可以再随意更改数据库的保护模式。
你是不是有疑问关于为什么待切换角色的standby不能处于maximum protection模式呢?这个其实很好理解,我们在第一节学习三种保护模式的时候就介绍过其各自的特点,脑袋瓜好使的同学应该还有印象,maximum protection模式需要确保绝无数据丢失,因此其对于提交事务对应的redo数据一致性要求非常高,另外,如果处于maximum protection模式的primary数据库仍然与standby数据库有数据传输,此时alter database语句更改standby数据库保护模式会失败,这也是由maximum protection模式特性决定的。
下面分别演示switchover和failover的过程:
一、 物理standby的Switchover
注意操作步骤的先后,很关键的哟。
1、 检查是否支持switchover操作 --primary数据库操作
登陆primary数据库,查询v$database视图的switchover_status列。
E:ora10g>set oracle_sid=jssweb
E:ora10g>sqlplus "/ as sysdba"
SQL*Plus: Release 10.2.0.3.0 - Production on 星期四 12月 13 09:41:29 2007
Copyright (c) 1982, 2006, Oracle. All Rights Reserved.
已连接。
SQL> select switchover_status from v$database;
SWITCHOVER_STATUS
--------------------
TO STANDBY
如果该列值为"TO STANDBY"则表示primary数据库支持转换为standby角色,否则的话你就需要重新检查一下Data Guard配置,比如看看LOG_ARCHIVE_DEST_n之类参数值是否正确有效等等。
2、 启动switchover --primary数据库操作
首先将primary转换为standby的角色,通过下列语句:
SQL> alter database commit to switchover to physical standby;
数据库已更改。
语句执行完毕后,primary数据库将会转换为standby数据库,并自动备份控制文件到trace。
3、 重启动到mount --原primary数据库操作
SQL> shutdown immediate
ORA-01507: 未装载数据库
ORACLE 例程已经关闭。
SQL> startup mount
ORACLE 例程已经启动。
Total System Global Area 167772160 bytes
Fixed Size 1289484 bytes
Variable Size 104858356 bytes
Database Buffers 54525952 bytes
Redo Buffers 7098368 bytes
数据库装载完毕。
4、 检查是否支持switchover操作 --待转换standby数据库操作
待原primary切换为standby角色之后,检查待转换的standby数据库switchover_status列,看看是否支持角色转换。
E:ora10g>set oracle_sid=jsspdg
E:ora10g>sqlplus " / as sysdba"
SQL*Plus: Release 10.2.0.3.0 - Production on 星期四 12月 13 10:08:15 2007
Copyright (c) 1982, 2006, Oracle. All Rights Reserved.
已连接。
SQL> select switchover_status from v$database;
SWITCHOVER_STATUS
--------------------
TO PRIMARY
SQL>
此时待转换standby数据库switchover_status列值应该是"TO_PRIMARY",如否则检查其初始化参数文件中的设置,提示一下,比着原primary数据库的初始化参数改改。
5、 转换角色到primary --待转换standby数据库操作
通过下列语句转换standby到primary角色:
SQL> alter database commit to switchover to primary;
数据库已更改。
注意:待转换的物理standby可以处于mount模式或open read only模式,但不能处于open read write模式。
6、 完成转换,打开新的primary数据库
SQL> alter database open;
数据库已更改。
注:如果数据库处于open read-only模式的话,需要先shutdown然后直接startup即可。
7、 验证一下
新的primary数据库
SQL> show parameter db_unique
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_unique_name string jsspdg
SQL> select max(sequence#) from v$archived_log;
MAX(SEQUENCE#)
--------------
67
SQL> alter system switch logfile;
系统已更改。
SQL> select max(sequence#) from v$archived_log;
MAX(SEQUENCE#)
--------------
68
新的standby数据库
SQL> show parameter db_unique
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_unique_name string jssweb
SQL> select max(sequence#) from v$archived_log;
MAX(SEQUENCE#)
--------------
68
转换成功。
物理standby的failover
注意几点:
l failover之后,原primary数据库默认不再是data guard配置的一部分。
l 多数情况下,其它逻辑/物理standby数据库不直接参与failover的过程,因此这些数据库不需要做任何操作。
l 某些情况下,新的primary数据库配置之后,需要重新创建其它所有的standby数据库。
另外,如果待转换角色的standby处于maximum protection或maximum availability模式的话,归档日志应该是连续存在的,这种情况下你可以直接从第 3 步执行,否则建议你按照操作步骤从第1步开始执行。
一般情况下failover都是表示primary数据库瘫痪,最起码也是起不来了,因此这种类型的切换基本上不需要primary数据库做什么操作。所以下列步骤中如果有提到primary和standby执行的,只是建议你如果primary还可以用,那就执行一下,即使它能用你却不执行,也没关系,不影响standby数据库的切换:)
1、 检查归档文件是否连续
查询待转换standby数据库的V$ARCHIVE_GAP视图,确认归档文件是否连接:
SQL> SELECT THREAD#, LOW_SEQUENCE#, HIGH_SEQUENCE# FROM V$ARCHIVE_GAP;
未选定行
如果返回的有记录,按照列出的记录号复制对应的归档文件到待转换的standby服务器。这一步非常重要,必须确保所有已生成的归档文件均已存在于standby服务器,不然可能会数据不一致造成转换时报错。文件复制之后,通过下列命令将其加入数据字典:
SQL> ALTER DATABASE REGISTER PHYSICAL LOGFILE 'filespec1';
2、 检查归档文件是否完整
分别在primary/standby执行下列语句:
SQL> select distinct thread#,max(sequence#) over(partition by thread#) a from v$archived_log;
该语句取得当前数据库各线程已归档文件最大序号,如果primary与standby最大序号不相同,必须将多出的序号对应的归档文件复制到待转换的standby服务器。不过既然是failover,有可能primary数据库此时已经无法打开,甚至无法访问,那你只好听天由命喽,三思在这里替你默念:苍天啊,大地啊,哪路的神仙大姐能来保佑俺们不丢数据呀!
3、 启动failover
执行下列语句:
SQL> alter database recover managed standby database finish force;
数据库已更改。
FORCE关键字将会停止当前活动的RFS进程,以便立刻执行failover。
剩下的步骤就与前面switchover很相似了
4、 切换物理standby角色为primary
SQL> alter database commit to switchover to primary;
数据库已更改。
5、 启动新的primary数据库。
如果当前数据库已mount,直接open即可,如果处于read-only模式,需要首先shutdown immediate,然后再直接startup。
SQL> alter database open;
数据库已更改。
角色转换工作完成。剩下的是补救措施(针对原primary数据库),由于此时primary数据库已经不再是data guard配置的一部分,我们需要做的就是尝试看看能否恢复原primary数据库,将其改造为新的standby服务器。具体操作方式可以分为二类:1.重建 2.备份恢复。所涉及的技术前面的系列文章中均有涉及,此处不再赘述。
世上没有永恒的主角,能够留住永恒的反是那些默默无闻的小角色,这一节出场的都是重量级选手,它们虽然不是主角,但他们比主角更重要(有时候)。
一、 READ ONLY/WRITE模式打开物理STANDBY
前面提到关于物理standby可以有效分担primary数据库压力,提升资源利用,实际上说的就是这个。以read only或read write模式打开物理standby,你可以转移一些查询任何啦,备份啦之类的操作到standby数据库,以这种方式来分担一些primary的压力。下面我们来演示一下,如何切换standby数据库的打开模式,其实,非常简单。例如,以Read-only模式打开物理standby:
这里要分两种情况:
1) .standby数据库处于shutdown状态
直接startup即可。
SQL> startup
ORACLE 例程已经启动。
......
2) .standby数据库处于redo应用状态。
首先取消redo应用:
SQL> alter database recover managed standby database cancel;
数据库已更改。
然后再打开数据库
SQL> alter database open ;
数据库已更改。
提示:open的时候不需要附加read only子句,oracle会根据控制文件判断是否是物理standby,从而自动启动到read only模式,直接startup也是同理。
3) .如果想从open状态再切换回redo应用状态,并不需要shutdown,直接启用redo应用即可,例如:
SQL> select status from v$instance;
STATUS
------------
OPEN
SQL> alter database recover managed standby database disconnect from session;
数据库已更改。
SQL> select status from v$instance;
STATUS
------------
MOUNTED
正如演示中我们所看到的,操作有一点点复杂,并且由于只读打开时就不能应用,虽然我们能够查询,但是查询的结果确是与primary不同步的,这点大大降低了物理standby做报表服务分担主库压力的可能性,对于这点呢,我们有两个解决方案:
1、 改用逻辑standby,由于逻辑standby是打开状态下的实时应用,因此数据同步应该是没啥问题了(只要 primary的数据类型和操作逻辑standby都能被支持),当然逻辑standby有逻辑standby 的问题,这个看完后面的逻辑standby相关章节,您就明白了。
2、 据称oracle11g全面改良了物理standby,最突出的特点就是在read only打开模式下,可以边接收边应用了(这下不用担心查询的数据不及时的问题了),您可以考虑升级您的数据库到最新版本,当然新版本也有新版本的问题,比如各种尚未暴露出来的bug,想想就担心是不是:)
所以你看,做技术其实并不困难,难的是做决择。这么引申过来看一看,老板们不容易啊,怪不得越大的领导脑袋上头发越少呢,为了保持我干净整洁浓密的发型,我我,我还是选择干技术吧~~~~
管理影响standby的primary数据库事件
为预防可能的错误,你必须知道primary数据库的某些事件可能影响standby数据库,并且了解如何处理。
某些情况下,primary数据库的某些改动会自动通过redo数据传播到standby数据库,因此不需要在standby数据库做额外的操作,而某些情况,则需要你手工调整。
下列事件会由redo传输服务及redo应用自动处理,不需要dba的干预,分别是:
l ALTER DATABASE ENABLE|DISABLE THREAD 语句(主要针对rac环境,目前基本已废弃,因为ENABLE|DISABLE INSTANCE子句完全能够实现类似功能)
l 修改表空间状态(例如read-write到read-only,online到offline)
l 创建修改删除表空间或数据文件(如果初始化参数STANDBY_FILE_MANAGEMENT被设置为AUTO的话,这点在前面第一章的时候提到过)
下列事情则需要dba手工干预:
1、 添加修改删除数据文件或表空间
前面提到了,初始化参数STANDBY_FILE_MANAGEMENT可以控制是否自动将primary数据库增加删除表空间、数据文件的改动继承到standby。
l 如果该参数值设置为auto,则自动创建。
l 如果设置为manual,则需要手工复制新创建的数据文件到standby服务器。
不过需要注意一点,如果数据文件是从其它数据库复制而来(比如通过tts),则不管STANDBY_FILE_MANAGEMENT参数值如何设置,都必须同时复制到standby数据库,并注意要修改standby数据库的控制文件。
下面分别通过示例演示STANDBY_FILE_MANAGEMENT参数值为AUTO/MANUAL值时增加及删除数据文件时的情形:
1) .STANDBY_FILE_MANAGEMENT设置为AUTO,增加及删除表空间和数据文件
我们先来看看初始化参数的设置: ----standby数据库操作
SQL> show parameter standby_file
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
standby_file_management string AUTO
A) .增加新的表空间 --primary数据库操作
SQL> create tablespace mytmp datafile 'e:ora10goradatajsswebmytmp01.dbf' size 20m;
表空间已创建。
检查刚添加的数据文件
SQL> select name from v$datafile;
NAME
-----------------------------------------------
E:ORA10GORADATAJSSWEBSYSTEM01.DBF
E:ORA10GORADATAJSSWEBUNDOTBS01.DBF
E:ORA10GORADATAJSSWEBSYSAUX01.DBF
E:ORA10GORADATAJSSWEBUSERS01.DBF
E:ORA10GORADATAJSSWEBWEBTBS01.DBF
E:ORA10GORADATAJSSWEBMYTMP01.DBF
已选择6行。
切换日志
SQL> alter system switch logfile;
系统已更改。
B) .验证standby库 --standby数据库操作
SQL> select name from v$datafile;
NAME
----------------------------------------------------
E:ORA10GORADATAJSSPDGSYSTEM01.DBF
E:ORA10GORADATAJSSPDGUNDOTBS01.DBF
E:ORA10GORADATAJSSPDGSYSAUX01.DBF
E:ORA10GORADATAJSSPDGUSERS01.DBF
E:ORA10GORADATAJSSPDGWEBTBS01.DBF
E:ORA10GORADATAJSSPDGMYTMP01.DBF
已选择6行。
SQL> select name from v$tablespace;
NAME
------------------------------
SYSTEM
UNDOTBS1
SYSAUX
TEMP
USERS
WEBTBS
MYTMP
已选择7行。
可以看到,表空间和数据文件已经自动创建,你是不是奇怪为什么数据文件路径自动变成了jsspdg,赫赫,因为我们设置了db_file_name_convert嘛。
C) .删除表空间 --primary数据库操作
SQL> drop tablespace mytmp including contents and datafiles;
表空间已删除。
SQL> select name from v$datafile;
NAME
--------------------------------------------------
E:ORA10GORADATAJSSWEBSYSTEM01.DBF
E:ORA10GORADATAJSSWEBUNDOTBS01.DBF
E:ORA10GORADATAJSSWEBSYSAUX01.DBF
E:ORA10GORADATAJSSWEBUSERS01.DBF
E:ORA10GORADATAJSSWEBWEBTBS01.DBF
SQL> alter system switch logfile;
系统已更改。
提示:使用including子句删除表空间时,
D) .验证standby数据库 --standby数据库操作
SQL> select name from v$datafile;
NAME
--------------------------------------------------
E:ORA10GORADATAJSSPDGSYSTEM01.DBF
E:ORA10GORADATAJSSPDGUNDOTBS01.DBF
E:ORA10GORADATAJSSPDGSYSAUX01.DBF
E:ORA10GORADATAJSSPDGUSERS01.DBF
E:ORA10GORADATAJSSPDGWEBTBS01.DBF
SQL> select name from v$tablespace;
NAME
------------------------------
SYSTEM
UNDOTBS1
SYSAUX
TEMP
USERS
WEBTBS
已选择6行。
得出结论,对于初始化参数STANDBY_FILE_MANAGMENT设置为auto的话,对于表空间和数据文件的操作完全无须dba手工干预,primary和standby都能很好的处理。
2) .STANDBY_FILE_MANAGEMENT设置为MANUAL,增加及删除表空间和数据文件
A) .增加新的表空间 --primary数据库操作
SQL> create tablespace mytmp datafile 'e:ora10goradatajsswebmytmp01.dbf' size 20m;
表空间已创建。
检查刚添加的数据文件
SQL> select name from v$datafile;
NAME
-----------------------------------------------
E:ORA10GORADATAJSSWEBSYSTEM01.DBF
E:ORA10GORADATAJSSWEBUNDOTBS01.DBF
E:ORA10GORADATAJSSWEBSYSAUX01.DBF
E:ORA10GORADATAJSSWEBUSERS01.DBF
E:ORA10GORADATAJSSWEBWEBTBS01.DBF
E:ORA10GORADATAJSSWEBMYTMP01.DBF
已选择6行。
切换日志
SQL> alter system switch logfile;
系统已更改。
B) .验证standby库 --standby数据库操作
SQL> select name from v$datafile;
NAME
----------------------------------------------------
E:ORA10GORADATAJSSPDGSYSTEM01.DBF
E:ORA10GORADATAJSSPDGUNDOTBS01.DBF
E:ORA10GORADATAJSSPDGSYSAUX01.DBF
E:ORA10GORADATAJSSPDGUSERS01.DBF
E:ORA10GORADATAJSSPDGWEBTBS01.DBF
E:ORA10GPRODUCT10.2.0DB_1DATABASEUNNAMED00006
已选择6行。
SQL> select name from v$tablespace;
NAME
------------------------------
SYSTEM
UNDOTBS1
SYSAUX
TEMP
USERS
WEBTBS
MYTMP
已选择7行。
可以看到,表空间已经自动创建,但是,数据文件却被起了个怪名字,手工修改其与primary数据库保持一致,如下(注意执行命令之后手工复制数据文件到standby):
SQL> alter database create datafile 'E:ORA10GPRODUCT10.2.0DB_1DATABASEUNNAMED00006'
2 as 'E:ora10goradatajsspdgmytmp01.dbf' ;
数据库已更改。
C) .删除表空间 --primary数据库操作
SQL> drop tablespace mytmp including contents and datafiles;
表空间已删除。
SQL> select name from v$datafile;
NAME
--------------------------------------------------
E:ORA10GORADATAJSSWEBSYSTEM01.DBF
E:ORA10GORADATAJSSWEBUNDOTBS01.DBF
E:ORA10GORADATAJSSWEBSYSAUX01.DBF
E:ORA10GORADATAJSSWEBUSERS01.DBF
E:ORA10GORADATAJSSWEBWEBTBS01.DBF
SQL> alter system switch logfile;
系统已更改。
D) .验证standby数据库 --standby数据库操作
SQL> select name from v$datafile;
NAME
----------------------------------------------------
E:ORA10GORADATAJSSPDGSYSTEM01.DBF
E:ORA10GORADATAJSSPDGUNDOTBS01.DBF
E:ORA10GORADATAJSSPDGSYSAUX01.DBF
E:ORA10GORADATAJSSPDGUSERS01.DBF
E:ORA10GORADATAJSSPDGWEBTBS01.DBF
E:ORA10GPRODUCT10.2.0DB_1DATABASEUNNAMED00006
已选择6行。
SQL> select name from v$tablespace;
NAME
------------------------------
SYSTEM
UNDOTBS1
SYSAUX
TEMP
USERS
WEBTBS
MYTMP
已选择7行。
呀,数据还在啊。赶紧分析分析,查看alert_jsspdg.log文件,发现如下(特别注意粗体):
File #6 added to control file as 'UNNAMED00006' because
the parameter STANDBY_FILE_MANAGEMENT is set to MANUAL
The file should be manually created to continue.
Errors with log E:ORA10GORADATAJSSPDGLOG1_753_641301252.ARC
MRP0: Background Media Recovery terminated with error 1274
Fri Jan 18 09:48:45 2008
这下明白了,为什么有个UNNAMED00006的数据文件,也晓得为啥standby数据库没能删除新加的表空间了吧,原来是后台的redo应用被停掉了,重启redo应用再来看看:
SQL> alter database recover managed standby database disconnect from session;
数据库已更改。
SQL> select name from v$datafile;
NAME
----------------------------------------------
E:ORA10GORADATAJSSPDGSYSTEM01.DBF
E:ORA10GORADATAJSSPDGUNDOTBS01.DBF
E:ORA10GORADATAJSSPDGSYSAUX01.DBF
E:ORA10GORADATAJSSPDGUSERS01.DBF
E:ORA10GORADATAJSSPDGWEBTBS01.DBF
注意,既使你在primary数据库执行删除时加上了including子句,在standby数据库仍然只会将表空间和数据文件从数据字典中删除,你还需要手工删除表空间涉及的数据文件。
再次得出结论,初始化参数STANDBY_FILE_MANAGMENT设置为manual的话,对于表空间和数据文件的操作必须有dba手工介入,你肯定会问,这太麻烦了,那我干脆配置dg的时候直接把初始化参数设置为auto不就好了嘛,en,你想的很好,不过三思需要提醒你地是,如果你的存储采用文件系统,那当然没有问题,但是如果采用了裸设备,你就必须将该参数设置为manual。
2、 重命名数据文件
如果primary数据库重命令了一个或多个数据文件,该项修改并不会自动传播到standby数据库。因为此,如果你想让standby和数据文件与primary保持一致,那你也只能自己手工操作了。这会儿就算STANDBY_FILE_MANAGEMENT也帮不上忙啦,不管它是auto还是manual。
下面通过示例做个演示:
A) .将重命名的数据文件所在表空间offline --primary数据库操作
SQL> alter tablespace webtbs offline;
表空间已更改。
B) .手工将数据文件改名(操作系统) --primary数据库操作
方式多样,不详述。
C) .通过命令修改数据字典中的数据文件路径,并online表空间 --primary数据库操作
SQL> alter tablespace webtbs rename datafile
2 'E:ORA10GORADATAJSSWEBWEBTBS01.DBF' to
3 'E:ORA10GORADATAJSSWEBTBSWEB01.DBF';
表空间已更改。
SQL> alter tablespace webtbs online;
表空间已更改。
D) .暂停redo应用,并shutdown --standby数据库操作
SQL> alter database recover managed standby database cancel;
数据库已更改。
SQL> shutdown immediate
ORA-01109: 数据库未打开
......
E) .手工将数据文件改名(操作系统) --standby数据库操作
方式多样,不详述。
F) .重启standby,修改数据文件路径(数据字典) --standby数据库操作
SQL> startup mount
ORACLE 例程已经启动。
Total System Global Area 167772160 bytes
Fixed Size 1289484 bytes
Variable Size 150995700 bytes
Database Buffers 8388608 bytes
Redo Buffers 7098368 bytes
数据库装载完毕。
SQL> alter database rename file
2 'E:ORA10GORADATAJSSPDGWEBTBS01.DBF' to
3 'E:ORA10GORADATAJSSPDGTBSWEB01.DBF';
数据库已更改。
G) .重新启动redo应用。
SQL> alter database recover managed standby database disconnect from session;
数据库已更改。
H) .切换日志 --primary数据库操作
对open resetlogs的primary数据库standby的恢复
当primary数据库被以resetlogs打开之后,dg提供了一些方案,能够让你快速的恢复物理standby ,当然这是有条件的,不可能所有的情况都可以快速恢复。 我们都知道alter database open resetlogs之后,数据库的scn被重置,也就是此时其redo数据也会从头开始。当物理standby接收到新的redo数据时,redo应用会自动获取这部分redo数据。对于物理standby而言,只要数据库没有应用resetlogs之 后 的redo数据,那么这个过程是不需要dba手工参与的。
下表描述 其它 情况下如何同步standby与primary数据库。
|
Standby数据库状态 |
Standby服务器操作 |
解决方案 |
|
没有应用resetlog之前的redo数据 |
自动应用新的redo数据 |
无须手工介入 |
|
应用了resetlog之 后 的redo数据,不过standby打开了flashback。 |
可以应用,不过需要dba手工介入 |
1. 手工flashback到应用之前 2. 重启redo应用,以重新接收新的redo数据。 |
|
应用了resetlog之 后 的redo数据,而且没有flashback。 |
完全无法应用 |
重建物理standby是唯一的选择 |
很绕是吧,举个例子你就明白了:
假设primary数据库当前生成的archive sequence#如下:...26,27,28,然后在28的时候执行了resetlogs,又生成了新的1,2,3.....,那么standby能够正常接收并应用26,27,28及新产生的1,2,3....
如果primary数据库在28的时候发生数据出现故障,recover到27,然后resetlogs,又生成了新的1,2,3.....,这个时候(大家注意,招子放亮点):如果standby还没有应用28,刚刚应用到27,则standby还可以继续接收新的redo数据1,2,3.....并应用。
如果此时不幸,standby由于是实时应用,已经应用了28的redo数据,那么如果standby打开了flashback,不幸中的万幸啊,这时候只需要dba手工介绍先flashback到27,然后再接收并应用新的1,2,3....
如果此时非常不幸,standby由于是实时应用,已经应用了28的redo数据,并且standby也没有打开flashback,那么,重建物理standby是你唯一的选择。
这下大家都明白了吧,赶紧起立鼓掌感谢yangtingkun大大的友情客串及形象示例,很通俗,很易懂:)。
监控primary/standby数据库
本节主要介绍一些监控dg配置的方式, 先给大家提供一个表格(描述不同事件的不同信息监控途径):
|
primary数据库事件 |
primary监控途径 |
standby监控途径 |
|
带有enable|disable thread子句的alter database命令 |
? Alert.log ? V$THREAD |
? Alert.log |
|
当前数据库角色,保护模式,保护级别,switchover状态,failover快速启动信息等 |
? V$DATABASE |
? V$DATABASE |
|
Redo log切换 |
? Alert.log ? V$LOG ? V$LOGFILE的status列 |
? Alert.log |
|
重建控制文件 |
? Alert log |
? Alert log |
|
手动执行恢复 |
? Alert log |
? Alert log |
|
表空间状态修改(read-write/read-only,online/offline) |
? DBA_TABLESPACES ? Alert log |
? V$RECOVER_FILE |
|
创建删除表空间或数据文件 |
? DBA_DATA_FILES ? Alert log |
? V$DATAFILE ? Alert log |
|
表空间或数据文件offline |
? V$RECOVER_FILE ? Alert log ? DBA_TABLESPACES |
? V$RECOVER_FILE ? DBA_TABLESPACES |
|
重命名数据文件 |
? V$DATAFILE ? Alert log |
? V$DATAFILE ? Alert log |
|
未被日志记录或不可恢复的操作 |
? V$DATAFILE view ? V$DATABASE view |
? Alert log |
|
恢复的进程 |
? V$ARCHIVE_DEST_STATUS ? Alert log |
? V$ARCHIVED_LOG ? V$LOG_HISTORY ? V$MANAGED_STANDBY ? Alert log |
|
Redo传输的状态和进度 |
? V$ARCHIVE_DEST_STATUS ? V$ARCHIVED_LOG ? V$ARCHIVE_DEST ? Alert log |
? V$ARCHIVED_LOG ? Alert log |
|
数据文件自动扩展 |
? Alert log |
? Alert log |
|
执行 OPEN RESETLOGS或CLEAR UNARCHIVED LOGFILES |
? Alert log |
? Alert log |
|
修改初始化参数 |
? Alert log |
? Alert log |
概括起来 主要 通过二 个方面:
1、 Alert Log
一句话:一定要养成有事没事定期不定期随时查看alert.log的好习惯同时特别注意alert中的提示通常不经意间会发现它的提示能够让你的思路豁然开朗。
2、 动态性能视图
先也是一句话:做为oracle自己自觉主动维护的一批虚拟表它的作用非常明显通过它可以及时获得当前数据库状态及处理进度总之好处多多也需特别关注后面示例也会多处用到大家要擦亮双眼。
l 先来点与恢复进度相关的v$视图应用示例:
A) .查看进程的活动状况--- v$managed_standby
该视图就是专为显示standby数据库 相关进程的 当前 状态信息,例如:
SQL> select process,client_process,sequence#,status from v$managed_standby;
PROCESS CLIENT_P SEQUENCE# STATUS
--------- -------- ---------- ------------
ARCH ARCH 763 CLOSING
ARCH ARCH 762 CLOSING
MRP0 N/A 764 WAIT_FOR_LOG
RFS LGWR 764 IDLE
RFS N/A 0 IDLE
PROCESS列显示进程信息
CLIENT_PROCESS列显示对应的主数据库中的进程
SEQUENCE#列显示归档redo的序列号
STATUS列显示的进程状态
通过上述查询可以得知primary开了两个归档进程,使用lgwr同步传输方式与standby通信,已经接收完763的日志,正等待764。
B) .确认redo应用进度---v$archive_dest_status
该视图显示归档文件路径配置信息及redo的应用情况等,例如:
SQL> select dest_name,archived_thread#,archived_seq#,applied_thread#,applied_seq#,db_unique_name
2 from v$archive_dest_status where status='VALID';
DEST_NAME ARCHIVED_THREAD# ARCHIVED_SEQ# APPLIED_THREAD# APPLIED_SEQ# DB_UNIQUE_
-------------------- ---------------- ------------- --------------- ------------ ----------
LOG_ARCHIVE_DEST_1 1 765 0 0 jsspdg
LOG_ARCHIVE_DEST_2 0 0 0 0 jssweb
STANDBY_ARCHIVE_DEST 1 764 1 764 NONE
C) .检查归档文件路径及创建信息---v$archived_log
该视图查询standby数据库归档文件的一些附加信息,比如文件创建时间啦,创建进程啦,归档序号啦,是否被应用啦之类,例如:
SQL> select name,creator,sequence#,applied,completion_time from v$archived_log;
NAME CREATOR SEQUENCE# APP COMPLETION_TIM
-------------------------------------------------- ------- ---------- --- --------------
E:ORA10GORADATAJSSPDGLOG1_750_641301252.ARC ARCH 750 YES 18-1月 -08
E:ORA10GORADATAJSSPDGLOG1_749_641301252.ARC ARCH 749 YES 18-1月 -08
E:ORA10GORADATAJSSPDGLOG1_751_641301252.ARC ARCH 751 YES 18-1月 -08
E:ORA10GORADATAJSSPDGLOG1_752_641301252.ARC ARCH 752 YES 18-1月 -08
E:ORA10GORADATAJSSPDGLOG1_753_641301252.ARC ARCH 753 YES 18-1月 -08
E:ORA10GORADATAJSSPDGLOG1_754_641301252.ARC ARCH 754 YES 18-1月 -08
D) .查询归档历史---v$log_history
该视图查询standby库中所有已被应用的归档文件信息(不论该归档文件是否还存在),例如:
SQL> select first_time,first_change#,next_change#,sequence# from v$log_history;
FIRST_TIME FIRST_CHANGE# NEXT_CHANGE# SEQUENCE#
------------------- ------------- ------------ ----------
2008-01-03 12:00:51 499709 528572 18
2008-01-08 09:54:42 528572 539402 19
2008-01-08 22:00:06 539402 547161 20
2008-01-09 01:05:57 547161 560393 21
2008-01-09 10:13:53 560393 561070 22
l 再来点与log应用相关的v$视图应用示例:
A) .查询当前数据的基本信息---v$database信息。
例如,查询数据库角色,保护模式,保护级别等:
SQL> select database_role,db_unique_name,open_mode,protection_mode,protection_level,switchover_status from v$database;
DATABASE_ROLE DB_UNIQUE_NAME OPEN_MODE PROTECTION_MODE PROTECTION_LEVEL SWITCHOVER_STATUS
---------------- ------------------------------ ---------- -------------------- -------------------- --------------------
PHYSICAL STANDBY jsspdg MOUNTED MAXIMUM AVAILABILITY MAXIMUM AVAILABILITY SESSIONS ACTIVE
再比如,查询failover后快速启动的信息
SQL> select fs_failover_status,fs_failover_current_target,fs_failover_threshold,
2 fs_failover_observer_present from v$database;
FS_FAILOVER_STATUS FS_FAILOVER_CURRENT_TARGET FS_FAILOVER_THRESHOLD FS_FAIL
--------------------- ------------------------------ --------------------- -------
DISABLED 0
B) .检查应用模式(是否启用了实时应用)---v$archive_dest_status
查询v$archive_dest_status视图,如果打开了实时应用,则recovery_mode会显示为:MANAGED REAL TIME APPLY,例如:
SQL> select recovery_mode from v$archive_dest_status where dest_id=2;
RECOVERY_MODE
-----------------------
MANAGED REAL TIME APPLY
C) .Data guard事件---v$dataguard_status
该视图显示那些被自动触发写入alert.log或服务器trace文件的事件。通常是在你不便访问到服务器查询alert.log时,可以临时访问本视图查看一些与dataguard相关的信息,例如:
SQL> select message from v$dataguard_status;
MESSAGE
----------------------------------------------------------------------------
ARC0: Archival started
ARC1: Archival started
ARC0: Becoming the 'no FAL' ARCH
准备工作
正如我们打小就被叮嘱饭前一定要洗手,在创建逻辑standby之前,准备工作同样必不可少。
在创建逻辑standby之前,首先检查primary数据库的状态,确保primary数据库已经为创建逻辑standby做好了全部准备工作,比如说是否启动了归档,是否启用了forced logging等,这部分可以参考创建物理standby时的准备工作。
除此之外呢,由于逻辑standby是通过sql应用来保持与primary数据库的同步。sql应用与redo应用是有很大区别地,这事儿咱们前面提到过,redo应用实际上是物理standby端进行recover,sql应用则是分析redo文件,将其转换为sql语句在逻辑standby端执行,因此,需要注意:
l 并非所有的数据类型都能被逻辑standby支持;
支持的数据类型有:
BINARY_DOUBLE、BINARY_FLOAT、BLOB、CHAR、CLOB and NCLOB、DATE、INTERVAL YEAR TO MONTH、INTERVAL DAY TO SECOND、LONG、LONG RAW、NCHAR、NUMBER、NVARCHAR2、RAW、TIMESTAMP、TIMESTAMP WITH LOCAL TIMEZONE、TIMESTAMP WITH TIMEZONE、VARCHAR2 and VARCHAR
提示:
下列类型在获取standby支持时需要注意兼容性:
? clob,需要primary数据库的兼容级别运行于10.1或更高
? 含lob字段的索引组织表(IOT),需要primary数据库的兼容级别运行于10.2或更高
? 不含lob字段的索引组织表(IOT),需要primary数据库的兼容级别运行于10.1或更高
不支持的数据类型有:
BFILE、Encrypted columns、ROWID, UROWID、XMLType、对象类型、VARRAYS、嵌套表、自定义类型。
洗手杀菌可以用肥皂或洗手液,检查数据库是否有不被逻辑standby支持的对象也同样有简单方式,我们 可以通过查询视图DBA_LOGSTDBY_UNSUPPORTED来确定主数据库中是否含有不支持的对象 :
SQL> SELECT * FROM DBA_LOGSTDBY_UNSUPPORTED;
提示:关于DBA_LOGSTDBY_UNSUPPORTED
该视图显示包含不被支持的数据类型的表的列名及该列的数据类型。注意该视图的ATTRIBUTES列,列值会显示表不被sql应用支持的原因。
l 并非所有的存储类型都能被逻辑standby支持;
支持簇表(Cluster tables)、索引组织表(Index-organized tables)、堆组织表(Heap-organized tables),不支持段压缩(segment compression)存储类型
l 并非所有的pl/sql包都能被SQL应用支持。
那些可能修改系统元数据的包不会被sql应用支持,因此即使它们在primary执行过,并且被成功传输到逻辑standby端,也不会执行,例如:DBMS_JAVA, DBMS_REGISTRY, DBMS_ALERT, DBMS_SPACE_ADMIN, DBMS_REFRESH, DBMS_REDEFINITION, DBMS_SCHEDULER, and DBMS_AQ等。
只有dbms_job例外,primary数据库的jobs会被复制到逻辑standby,不过在standby数据库不会执行这些job。
l 并非所有的sql语句都能在逻辑standby执行;
默认情况下,下列sql语句在逻辑standby会被sql应用自动跳过:
ALTER DATABASE
ALTER MATERIALIZED VIEW
ALTER MATERIALIZED VIEW LOG
ALTER SESSION
ALTER SYSTEM
CREATE CONTROL FILE
CREATE DATABASE
CREATE DATABASE LINK
CREATE PFILE FROM SPFILE
CREATE MATERIALIZED VIEW
CREATE MATERIALIZED VIEW LOG
CREATE SCHEMA AUTHORIZATION
CREATE SPFILE FROM PFILE
DROP DATABASE LINK
DROP MATERIALIZED VIEW
DROP MATERIALIZED VIEW LOG
EXPLAIN
LOCK TABLE
SET CONSTRAINTS
SET ROLE
SET TRANSACTION
另外,还有一大批ddl操作,同样也不会在逻辑standby端执行,由于数目较重,此处不再一一列举,感兴趣的话请google查看官方文档。
l 并非所有的dml操作都能在逻辑standby端SQL应用;
维护逻辑standby与primary的数据库同步是通过sql应用实现,SQL应用转换的SQL语句在执行时,对于insert还好说,对于update,delete操作则必须能够唯一定位到数据库待更新的那条记录。问题就在这里,如果primary库中表设置不当,可能就无法确认唯一条件。
你可能会说可以通过rowid唯一嘛!!同学,千万要谨记啊,逻辑standby,为啥叫逻辑standby呢,它跟物理standby有啥区别呢,就是因为它只是逻辑上与primary数据库相同,物理上可能与primary数据库存在相当大差异,一定要认识到,逻辑standby的物理结构与primary是不相同的(即使初始逻辑standby是通过primary的备份创建),因此想通过rowid更新显然是不好使的,就不能再将其做为唯一条件。那怎么办泥,OK,话题被引入,下面请听三思向您一一道来:
如何确保primary库中各表的行可被唯一标识
Oracle 通过主键、唯一索引/约束补充日志(supplemental logging)来确定待更新逻辑standby库中的行。当数据库启用了补充日志(supplemental logging),每一条update语句写redo的时候会附加列值唯一信息,比如:
v 如果表定义了主键,则主键值会随同被更新列一起做为update语句的一部分,以便执行时区别哪些列应该被更新。
v 如果没有主键,则非空的唯一索引/约束会随同被更新列做为update语句的一部分,以便执行时区分哪些列应该被更新,如果该表有多个唯一索引/约束,则oracle自动选择最短的那个。
v 如果表即无主键,也没有定义唯一索引/约束,所有可定长度的列连同被更新列作为update语句的一部分。更明确的话,可定长度的列是指那些除:long,lob,long raw,object type,collection类型外的列。
确定在主数据库上,补充日志是否被启用,可以查询v$database,如下:
SQL> select supplemental_log_data_pk,supplemental_log_data_ui from v$database;
SUP SUP
--- ---
YES YES
因此,Oracle 建议你为表创建一个主键或非空的唯一索引/约束,以尽可能确保sql应用能够有效应用redo数据,更新逻辑standby数据库。
执行下列语句检查sql应用能否唯一识别表列,找出不被支持的表
SQL> SELECT OWNER, TABLE_NAME FROM DBA_LOGSTDBY_NOT_UNIQUE
2> WHERE (OWNER, TABLE_NAME) NOT IN
3> (SELECT DISTINCT OWNER, TABLE_NAME FROM DBA_LOGSTDBY_UNSUPPORTED)
4> AND BAD_COLLUMN = 'Y';
提示:
关于DBA_LOGSTDBY_NOT_UNIQUE
该视图显示所有即没主键也没唯一索引的表。如果表中的列包括足够多的信息通常也可支持在逻辑standby的更新,不被支持的表通常是由于列的定义包含了不支持的数据类型。
注意BAD_COLUMN列值,该列有两个值:
Y:表示该表中有采用大数据类型的字段,比如LONG啦,CLOB啦之类。如果表中除log列某些行记录完全匹配,则该表无法成功应用于逻辑standby。standby会尝试维护这些表,不过你必须保证应用不允许
N:表示该表拥有足够的信息,能够支持在逻辑standby的更新,不过仍然建议你为该表创建一个主键或者唯一索引/约束以提高log应用效率。
假设某张表你可以确认数据是唯一的,但是因为效率方面的考虑,不想为其创建主键或唯一约束,,怎么办呢,没关系,oracle想到了这一点,你可以创建一个disable的primary-key rely约束:
关于primary-key RELY约束:
如果你能够确认表中的行是唯一的,那么可以为该表创建rely的主键,RELY约束并不会造成系统维护主键的开销,主你对一个表创建了rely约束,系统则会假定该表中的行是唯一,这样能够提供sql应用时的性能。但是需要注意,由于rely的主键约束只是假定唯一,如果实际并不唯一的话,有可能会造成错误的更新哟。
创建rely的主键约束非常简单,只要在标准的创建语句后加上RELY DISABLE即可,例如:
SQL> alter table jss.b add primary key (id) rely disable;
表已更改。
创建步骤
1、 创建物理standby
最方便的创建逻辑standby的方式就是先创建一个物理standby,然后再将其转换成逻辑standby,因此第一步就是先创建一个物理standby。注意,在将其转换为逻辑standby前,可以随时启动和应用redo,但是如果你决定将其转换为逻辑standby,就必须先停止该物理standby的redo应用,以避免提前应用含LogMiner字典的redo数据,造成转换为逻辑standby后,sql应用时logMiner字典数据不足而影响到逻辑standby与primary的正常同步。
2、 设置primary数据库
在前面创建standby时我们曾经设置过无数个初始化参数用于primary与物理standby的角色切换,我想说的是,对于逻辑standby的角色切换,那些参数同样好使。
不过注意,如果希望primary数据库能够正常切换为逻辑standby角色的话,那么你还需要设置相应的log_archive_dest_N,并且valid_for属性,需要更改成:(STANDBY_LOGFILES,STANDBY_ROLE)。
然后需要生成LogMiner字典信息,通过执行下列语句生成( 务必执行 ):
SQL> EXECUTE DBMS_LOGSTDBY.BUILD;
该过程专门用于生成记录的元数据信息到redo log,这样改动才会被传输到逻辑standby,然后才会被逻辑standby进行SQL应用。
提示:
? 该过程会自动启用primary数据库的补充日志(supplemental logging)功能(如果未启用的话)。
? 该过程执行需要等待当前所有事务完成,因此如果当前有较长的事务运行,可能该过程执行也需要多花一些等待时间。
? 该过程是通过闪回查询的方式来获取数据字典的一致性,因此oracle初始化参数UNDO_RETENTION值需要设置的足够大。
3、 转换物理standby为逻辑standby
执行下列语句,转换物理standby为逻辑standby:
SQL> alter database recover to logical standby NEW_DBNAME;
关于db_name(注意哟,这可不是db_unique_name,不同于物理standby,逻辑standby是一个全新的数据库,因此建议你指定一个唯一的,与primary不同的数据库名),如果当前使用spfile,则数据库会自动修改其中的相关信息,如果使用的pfile,在下次执行shutdown的时候oracle会提示你去修改db_name初始化参数的值。
提示:执行该语句前务必确保已经暂停了redo应用,另外转换是单向的,即只能由物理standby向逻辑standby转换,而不能由逻辑standby转成物理standby。这并不仅仅是因为dbname发生了修改,更主要的原因是逻辑standby仅是数据与primary一致,其它如存储结构,scn等基于dbid都不一相同。
另外,该语句执行过程中,需要应用全部的LogMiner字典相关的redo数据。这部分操作完全依赖于primary数据库DBMS_LOGSTDBY.BUILD的执行以及传输到standby后有多少数据需要被应用。如果primary数据库执行DBMS_LOGSTDBY.BUILD失败,则转换操作也不会有结果,这时候你恐怕不得不先cancel掉它,解决primary数据库的问题之后再尝试执行转换。
4、 重建逻辑standby的密码文件
主要是由于转换操作修改了数据库名,因此密码文件也需要重建,这个操作我们做的比较多,这里就不详述了。
5、 调整逻辑standby初始化参数
之所以要调整初始化参数,一方面是由于此处我们的逻辑standby是从物理standby转换来的,某些参数并不适合甚至可能造成错误,比如log_archive_dest_n参数的设置。另一方面,由于逻辑standby会有读写操作,因此需要读写本地online redologs及并产生archivelogs,务必需要注意本地的archivelogs路径不要与应用接收自primary数据库的redo数据生成的archivelogs路径冲突。当然归根结底是因为逻辑standby是从物理standby转换而来,因此standby的初始化参数就需要第二次调整(第一次是创建物理standby),这里为什么要选择从物理standby转换呢?很简单,因为前面测试过程中创建了两个standby,所以我觉着直接转换一个当成逻辑standby,操作更省事儿:)
当然我相信,看完这个系列,如果你对于创建的流程能够非常清晰,完全可以跳过先创建物理standby的过程,直接创建逻辑standby。
关于修改初始化参数的方式有多种,通过alter system set也可以,或者先生成pfile修改相关参数,然后再根据修改过的pfile生成spfile也可以。
6、 打开逻辑standby
由于逻辑standby与primary数据库事务并不一致,因此第一次打开时必须指定resetlogs选择,如下:
SQL> alter database open resetlogs;
然后可以通过执行下列sql命令应用redo数据:
SQL> alter database start logical standby apply immediate;
如果想停止逻辑standby的sql应用,可以通过下列命令:
SQL> alter database stop logical standby apply immediate;
假设当前架构为一个primary+二个物理standby,我们转换其中一个物理standby成为逻辑standby,专用于查询服务,另一个物理standby用于执行备份操作及提供灾备。这里我们直接借用之前创建的物理standby,只演示创建过程,我们假设当前primary数据库状态良好,没有任何不被逻辑standby支持的对象或类型。
为了方便区分当前操作的数据库,我们设置一下操作符:
SQL> set sqlprompt JSSWEB> --表示primary数据库
SQL> set sqlprompt JSSPDG> --表示物理standby
SQL> set sqlprompt JSSLDG> --表示逻辑standby
一、 创建物理standby
此步跳过,如有不明,具体可参考第二部分。
提示:表忘记暂停该standby的redo应用
JSSLDG>alter database recover managed standby database cancel;
数据库已更改。
二、 设置primary数据库
由于有前期创建物理standby时的基础,此处primary数据库的初始化参数可以不做修改,最重要的是不要忘记生成LogMiner字典信息。
JSSWEB>execute dbms_logstdby.build;
PL/SQL 过程已成功完成。
三、 转换物理standby为逻辑standby
执行下列语句,转换物理standby为逻辑standby:
JSSLDG>show parameter db_name;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_name string jssweb
JSSLDG> alter database recover to logical standby jssldg;
数据库已更改。
JSSLDG>shutdown immediate
ORA-01507: 未装载数据库
ORACLE 例程已经关闭。
JSSLDG>startup mount;
ORACLE 例程已经启动。
Total System Global Area 167772160 bytes
Fixed Size 1289484 bytes
Variable Size 79692532 bytes
Database Buffers 79691776 bytes
Redo Buffers 7098368 bytes
数据库装载完毕。
JSSLDG>show parameter db_name;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_name string JSSLDG
JSSLDG>select database_role from v$database;
DATABASE_ROLE
----------------
LOGICAL STANDBY
四、 重建逻辑standby的密码文件
E:ora10g>orapwd file=e:ora10gproduct10.2.0db_1databasePWDjssldg.ora password=verysafe entries=30
注意保持sys密码与primary数据库一致。
五、 调整逻辑standby初始化参数
注意归档文件路径不要冲突:
JSSLDG>alter system set log_archive_dest_1='location=E:ora10goradataJSSLDGarc valid_for=(online_logfiles,all_roles) db_unique_name=JSSLDG';
系统已更改。
JSSLDG>alter system set log_archive_dest_2='location=E:ora10goradataJSSLDGstd valid_for=(standby_logfiles,standby_role) db_unique_name=JSSLDG';
系统已更改。
另外,由于之前我们创建JSSLDG时并未创建standby redologs,但对于逻辑standby的sql应用,standby redologs是必须的,因此我们在此处也要为该standby创建几组standby redologs:
JSSLDG>alter database add standby logfile group 4 ('E:ora10goradataJSSLDGstandbyrd01.log') size 20m;
数据库已更改。
JSSLDG>alter database add standby logfile group 5 ('E:ora10goradataJSSLDGstandbyrd02.log') size 20m;
数据库已更改。
JSSLDG>alter database add standby logfile group 6 ('E:ora10goradataJSSLDGstandbyrd03.log') size 20m;
数据库已更改。
JSSLDG>select member from v$logfile;
MEMBER
----------------------------------------------------------
E:ORA10GORADATAJSSLDGREDO01.LOG
E:ORA10GORADATAJSSLDGREDO02.LOG
E:ORA10GORADATAJSSLDGREDO03.LOG
E:ORA10GORADATAJSSLDGSTANDBYRD01.LOG
E:ORA10GORADATAJSSLDGSTANDBYRD02.LOG
E:ORA10GORADATAJSSLDGSTANDBYRD03.LOG
已选择6行。
六、 打开逻辑standby
由于逻辑standby与primary数据库事务并不一致,因此第一次打开时必须指定resetlogs选择,如下:
SQL> alter database open resetlogs;
数据库已更改。
然后执行下列sql命令应用redo数据:
SQL> alter database start logical standby apply immediate;
数据库已更改。
七、 检查一下
首先在primary数据库执行:
JSSWEB> select *from jss.b;
ID
----------
1
2
3
已选择3行。
JSSWEB> insert into jss.b values (4);
已创建 1 行。
JSSWEB> insert into b values (5);
已创建 1 行。
JSSWEB> insert into b values (6);
已创建 1 行。
JSSWEB> commit;
提交完成。
JSSWEB> alter system switch logfile;
系统已更改。
查询物理standby的同步情况,由于物理standby处于mount状态,无法直接查询,因此我们需要先暂停redo应用,然后以read only模式打开数据库再执行查询:
JSSPDG>alter database recover managed standby database cancel;
数据库已更改。
JSSPDG>alter database open read only;
数据库已更改。
JSSPDG>select * from jss.b;
ID
----------
1
2
3
4
5
6
已选择6行。
查询逻辑standby的同步情况:
JSSLDG>select * from jss.b;
ID
----------
1
2
3
4
5
6
已选择6行。
提示:细心观察,发现逻辑standby有一点很好,从primary接收到的redo文件,应用过之后会自动删除,节省磁盘空间。
Ok,逻辑standby也创建完成了,我们再回过头来回忆回忆我们最开始的假设:
对于相机拍照而言,有种傻瓜相机功能强大而操作简便,而对于素描,即使是最简单的画法,也需要相当多的练习才能掌握。这个细节是不是也说明逻辑standby相比物理standby需要操作者拥有更多的操作技能呢?
现在看起来,操作呢相比物理standby是稍稍复杂了一点点,但机理呢与物理standby大同小异,功能呢也不见的就比物理standby强到哪里,主要是前期准备工作略嫌繁琐(尤其你的数据库系统比较宏大时,毕竟有那么多支持和不支持的数据类型/操作/语句需要dba手工处理),这么看来,画画的仿佛是要比搞摄影的更讲究基本功啊,不过事物要辩证着看,爱好摄影的朋友千万莫因此而感到沮丧,从实用角度看,搞摄影不知要比画画强多少倍啊,效率在那摆着呢,要出片子按下快门就成啦!对于standby也是如此,你究竟是想要物理的,还是想要逻辑的呢,这是个问题~~~~~
关于角色转换的一些概念在物理standby章节的时候已经讲了很多,在概念和操作方式上二者基本一致,不过如果你真正深刻理解了物理standby和逻辑standby,你会意识到,对于逻辑standby而言,不管是switchover还是failover,怎么操作起来,都这么怪怪的呢~~~
逻辑standby之switchover
要在primary和逻辑standby之间切换角色,一般是从操作primary开始。
提示:
如果primary或逻辑standby是rac结构,切记只保留一个实例启动,其它实例全部shutdown。等角色转换操作完成之后再启动其它实例,角色转换的操作会自动传播到这些实例上,并不需要你再对这些实例单独做处理。
一、 准备工作
1、检查primary和逻辑standby的初始化参数设置,常规的检查包括:
·确保fal_server,fal_client值设置正确
·确保log_archive_dest_n参数设置正确
更多可能涉及的初始化参数可以参考2.1中的第4小章
首先来看当前的primary数据库:
JSSWEB> show parameter fal
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
fal_client string jssweb
fal_server string jsspdg
JSSWEB> show parameter name_convert
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_file_name_convert string oradatajsspdg, oradatajssweb
log_file_name_convert string oradatajsspdg, oradatajssweb
JSSWEB> show parameter log_archive_dest
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_archive_dest string
log_archive_dest_1 string LOCATION=E:ora10goradatajss
webarc VALID_FOR=(ALL_LOGFIL
ES,ALL_ROLES) DB_UNIQUE_NAME=j
ssweb
log_archive_dest_2 string service=jsspdg
OPTIONAL LGWR SYNC AFFIRM VALI
D_FOR=(ONLINE_LOGFILES,PRIMARY
_ROLE) DB_UNIQUE_NAME=jsspdg
................
................
................
log_archive_dest_state_1 string ENABLE
log_archive_dest_state_2 string defer
由于此处primary的初始化参数并不合适,为了避免其转换之后发生错误,我们需要提前做些修改:
JSSWEB> alter system set log_archive_dest_2='location=e:ora10goradatajsswebstd valid_for=(standby_logfiles,standby_role) db_unique_name
=jssweb';
系统已更改。
JSSWEB> alter system set log_archive_dest_1='location=e:ora10goradatajsswebarc valid_for=(online_logfiles,all_roles) db_unique_name=jss
web';
系统已更改。
JSSWEB> alter system set log_archive_dest_state_2='enable';
系统已更改。
JSSWEB> alter system set fal_server='jssldg';
系统已更改。
--xx_file_name_convert这两个参数无法动态修改,因此我们首先修改spfile,然后再重启一下数据库
JSSWEB> alter system set db_file_name_convert='oradatajssldg','oradatajssweb' scope=spfile;
系统已更改。
JSSWEB> alter system set log_file_name_convert='oradatajssldg','oradatajssweb' scope=spfile;
系统已更改。
JSSWEB> startup force
然后再看看待转换的逻辑standby
JSSLDG> show parameter fal
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
fal_client string
fal_server string
JSSLDG> show parameter file_name
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_file_name_convert string oradatajssweb, oradatajssldg
log_file_name_convert string oradatajssweb, oradatajssldg
JSSLDG> show parameter log_archive
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_archive_config string DG_CONFIG=(jssweb,jsspdg,jssld
g)
log_archive_dest string
log_archive_dest_1 string location=E:ora10goradatajss
ldgarc valid_for=(online_log
files,all_roles) db_unique_nam
e=jssldg
log_archive_dest_10 string
log_archive_dest_2 string location=E:ora10goradataJSS
LDGstd valid_for=(standby_lo
gfiles,standby_role) db_unique
_name=JSSLDG
.......................
.......................
对于待转换的逻辑standby中,某些初始化参数也可以不设置,不过走到这一步了,顺手全设置一遍。
JSSLDG> alter system set fal_server='jssweb';
系统已更改。
JSSLDG> alter system set fal_client='jssldg';
系统已更改。
JSSLDG> alter system set log_archive_dest_3='service=jssweb lgwr async valid_for=(online_logfiles,primary_role) db_unique_name=jssweb';
系统已更改。
2、检查primary数据库是否配置了standby redologs
JSSWEB> select * from v$standby_log;
未选定行
对于逻辑standby数据库,standby redologs是必须的,因此我们需要为当前的primary创建几个standby redologs。
JSSWEB> alter database add standby logfile group 4 ('e:ora10goradatajsswebstandbyrd01.log') size 20m;
数据库已更改。
.....................
.......................
.........................
JSSWEB> alter database add standby logfile group 8 ('e:ora10goradatajsswebstandbyrd05.log') size 20m;
数据库已更改。
二、 检查primary数据库状态
在当前的primary数据库查询v$database视图中的switchover_status列,查看当前primary数据库状态。
JSSWEB> select switchover_status from v$database;
SWITCHOVER_STATUS
--------------------
TO STANDBY
如果该查询返回TO STANDBY 或SESSIONS ACTIVE则表示状态正常,可以执行转换操作,如果否的话,就需要你先检查一下当前的dataguard配置,看看是否
三、 准备转换primary为逻辑standby
执行下列语句,将primary置为准备转换的状态:
JSSWEB> alter database prepare to switchover to logical standby;
数据库已更改。
查看一下switchover_status的状态,哟,果然变成准备ing啦~~
JSSWEB> select switchover_status from v$database;
SWITCHOVER_STATUS
--------------------
PREPARING SWITCHOVER
四、 准备转换逻辑standby为primary
我们一定要学习oracle这种逻辑,甭管想做什么,都得先有个准备的过程~
JSSLDG> alter database prepare to switchover to primary;
数据库已更改。
JSSLDG> select switchover_status from v$database;
SWITCHOVER_STATUS
--------------------
PREPARING SWITCHOVER
五、 再次检查primary数据库状态
JSSWEB> select switchover_status from v$database;
SWITCHOVER_STATUS
--------------------
TO LOGICAL STANDBY
注意:这步虽然不做什么操作,但检查结果却非常重要,它直接关系到switchover转换是否能够成功。逻辑standby执行完prepare命令之后,就会生成相应的LogMiner字典数据(就像我们前面创建逻辑standby时,primary会生成LogMiner字典数据一样),只有它正常生成并发送至当前的primary,转换操作才能够继续下去。不然当前的primary数据库在转换完之后,可能就失去了从新的primary接收redo数据的能力了。
因此,如果上述查询的返回结果不是:TO LOGICAL STANDBY的话,你可能就需要取消此次转换,检查原因,然后再重新操作了。
提示:
取消转换可以通过下列语句:
ALTER DATABASE PREPARE TO SWITCHOVER CANCEL;
需要分别在primary和逻辑standby执行。
六、 转换primary为逻辑standby
执行下列语句:
JSSWEB> alter database commit to switchover to logical standby;
数据库已更改。
该语句需要等待当前primary所有事务全部结束。同时该语句也会自动拒绝用户发布的新事务或修改需求。为确保该操作尽可能快的执行,最好自开始切换操作起就禁止所有用户的操作。
该命令执行完之后,这个primary就已经成为新的逻辑standby了。不过在新primary执行完转换之前,不要关闭当前这个数据库。
七、 再次检查逻辑standby状态
逻辑standby在接收到前primary的转换消息,并应用完相关的redo数据之后,会自动暂停sql应用,然后查询switchover_status的状态,应该为:TO PRIMARY
JSSLDG> select switchover_status from v$database;
SWITCHOVER_STATUS
--------------------
TO PRIMARY
八、 转换逻辑standby为primary
最后的工作总会在逻辑standby上操作,通过上列语句,将该逻辑standby转换为新的primary。
JSSLDG> alter database commit to switchover to primary;
数据库已更改。
转换完成
九、 启动新逻辑standby的sql应用
最后启动新逻辑standby的sql应用。
JSSWEB> alter database start logical standby apply;
数据库已更改。
提示:还记的我们的jsspdg吗,虽然它也是standby(物理),不过它现在也并非这个dataguard配置中的一员了,这也是由于逻辑standby自身特性决定的,每一个逻辑standby都相当于是一个不同于primary的数据库(DBID都不同),因此在逻辑standby完成了转换之后,相当于原primary已经消失,因此原primary配置的物理standby也失去了主从参照,不过原primary配置的逻辑standby不会有影响。
逻辑standby之failover
前面学习物理standby的failover时我们提到过,failover有可能会丢失数据(视当前的数据库保护模式而定),对于逻辑standby也一样;物理standby在做failover演示时还提到过,所有的操作都会在standby端执行,对于逻辑standby这也一样,甚至对于明确提及在前primary执行的,你不执行,也没关系,毕竟对于failover,我们假设的就是,primary已经over了:)
一、 准备工作要充分
准备工作可以从以下几个方面着手:
1、 检查及处理丢失的归档
虽然本步不是必须的,但如果希望尽可能少丢失数据,除了数据保护模式之外,本步操作也非常重要。如果此时primary仍可被访问,首先检查当前的归档日志序号与逻辑standby是否相同:
JSSLDG> select max(sequence#) from v$archived_log;
MAX(SEQUENCE#)
--------------
24
JSSWEB> select sequence#,applied from dba_logstdby_log;
SEQUENCE# APPLIED
---------- --------
23 YES
24 YES
已选择2行。
提示:如果primary的数据库已经无法打开,您就只好直接到磁盘上查看归档目录中的序号来与standby端做比较了。
如果不同序号,则将primary尚未发送至standby的归档文件手工复制到待转换的逻辑standby服务器,然后在standby端通过 ALTER DATABASE REGISTER LOGICAL LOGFILE ''; 命令将文件手工注册
如果standby与primary的归档序号相同,但某些序号的applied状态为no,建议你检查一下当前standby是否启动了SQL应用:)。
2、 检查待转换逻辑standby的日志应用情况
可以通过查询v$logstdby_progress视图:
JSSWEB> select applied_scn,latest_scn from v$logstdby_progress;
APPLIED_SCN LATEST_SCN
----------- ----------
1259449 1259453
如果两值一致,表示所有接收到的归档都已经应用了。
3、 检查及修正待转换逻辑standby的初始化参数配置
确认待转换的逻辑standby配置了正确的归档路径,不仅是写本地的归档,还要有写远程的归档,不然转换完之后,这台新的primary就成了光杆司令了。
JSSWEB> show parameter log_archive_dest
.......................
当然一般来说,我们都是推荐在创建standby的同时将一些用于角色切换的初始化参数也配置好(primary和standby端都应如此),以减小切换时操作的时间,提高切换效率。
二、 激活新的primary数据库
首先查看当前操作的角色
JSSWEB> select database_role,force_logging from v$database;
DATABASE_ROLE FOR
---------------- ---
LOGICAL STANDBY YES
注意,如果当前force_logging为no,务必执行:Alter database force logging;
转换standby角色为primary
JSSWEB> alter database activate logical standby database finish apply;
数据库已更改。
该语句主要是停止待转换的逻辑standby中RFS进程,并应用完当前所有已接收但并未应用的redo数据,然后停止sql应用,将数据库转换成primary角色。
JSSWEB> select database_role,force_logging from v$database;
DATABASE_ROLE FOR
---------------- ---
PRIMARY YES
基本上到这一步,我们可以说角色转换的工作已经完成了,但是注意,活还没有干完!
此处与逻辑standby的switchover同理,切换完之后,原dg配置就失效了(不仅原物理standby没了,原逻辑standby也失去了参照,看看,逻辑standby的failover确实威力巨大呀,怪不得逻辑standby用的人这么人呢,环境脆弱肯定是原因之一啊),因此我们需要做些设置,重新将原来的standby再加入到新的dg配置环境中。
三、 修复其它standby
注意哟,逻辑standby的修复可并不像物理standby那样简单,每个逻辑standby都相当于是独立的数据库,如果你不希望重建逻辑standby的话呢,oracle倒是也提供了其它解决方案(虽然不一定好使):
1、 在各个原逻辑standby中创建数据库链,连接到新的primary
注意,数据库链中用于连接新primary的用户必须拥有SELECT_CATALOG_ROLE角色。
JSSLDG2> alter session disable guard;
会话已更改。
JSSLDG2> create database link getjssweb connect to jss identified by jss using 'jssweb';
数据库链接已创建。
JSSLDG2> alter session enable guard;
会话已更改。
验证一下数据链是否能够正常访问:
JSSLDG2> select sysdate from dual@getjssweb;
SYSDATE
--------------
23-2月 -08
提示:关于alter session enable|disable guard语句,用于允许或禁止用户修改逻辑standby中的结构。例如:
JSSLDG2> conn jss/jss
已连接。
JSSLDG2> select *from b;
ID
----------
1
2
3
4
5
6
7
8
已选择8行。
JSSLDG2> alter table b rename to a;
alter table b rename to a
*
第 1 行出现错误:
ORA-16224: Database Guard 已启用
JSSLDG2> alter session disable guard;
会话已更改。
JSSLDG2> alter table b rename to a;
表已更改。
2、 重新启动SQL应用
在各个逻辑standby执行下列语句启动sql应用(注意更新dblinkName):
JSSLDG2> alter database start logical standby apply new primary getjssweb;
数据库已更改。
如果你运气好,等语句执行完之后,恢复过程就完成了。如果你非常不幸的碰到了ORA-16109错误,那么我不得不告诉你,恐怕你得重建逻辑standby了。所以,祝你好运吧:)
语句顺利执行完之后,我们来验证一下:
JSSWEB> alter system switch logfile;
系统已更改。
JSSWEB> select max(sequence#) from v$archived_log;
MAX(SEQUENCE#)
--------------
862
JSSLDG2> select sequence#,applied from dba_logstdby_log;
SEQUENCE# APPLIED
---------- --------
862 NO
注意:出现问题了!!
日志是传输过去了,但是逻辑standby并没有开始应用,怎么回事?
我们先来确认一下standby的各进程状态:
JSSLDG2> select process,status,group#,thread#,sequence#,block#,blocks from v$managed_standby;
PROCESS STATUS GROUP# THREAD# SEQUENCE# BLOCK# BLOCKS
--------- ------------ ---------------------------------------- ---------- ---------- ---------- ----------
ARCH CLOSING 2 1 4 16385 1836
ARCH CLOSING 6 1 862 1 18
RFS IDLE N/A 0 0 0 0
RFS IDLE 3 1 863 2 1
看起来也是正常的,接收完了862,正在等待863,但是,为什么不应用呢。
手工查询一下新primary生成的归档日志情况:
JSSWEB> select sequence#,name,COMPLETION_TIME from v$archived_log where sequence#>855;
SEQUENCE# NAME COMPLETION_TIME
---------- ---------------------------------------------------------------------- -------------------
856 E:ORA10GORADATAJSSWEBARCLOG1_856_641301252.ARC 2008-02-21 10:15:42
857 E:ORA10GORADATAJSSWEBARCLOG1_857_641301252.ARC 2008-02-21 10:16:46
858 E:ORA10GORADATAJSSWEBARCLOG1_858_641301252.ARC 2008-02-23 14:15:18
859 E:ORA10GORADATAJSSWEBARCLOG1_859_641301252.ARC 2008-02-23 14:56:55
860 E:ORA10GORADATAJSSWEBARCLOG1_860_641301252.ARC 2008-02-23 14:57:03
861 E:ORA10GORADATAJSSWEBARCLOG1_861_641301252.ARC 2008-02-23 16:58:14
861 jssldg2 2008-02-23 16:58:16
862 E:ORA10GORADATAJSSWEBARCLOG1_862_641301252.ARC 2008-02-23 17:08:57
862 jssldg2 2008-02-23 17:08:57
863 E:ORA10GORADATAJSSWEBARCLOG1_863_641301252.ARC 2008-02-23 17:19:48
863 jssldg2 2008-02-23 17:20:59
864 E:ORA10GORADATAJSSWEBARCLOG1_864_641301252.ARC 2008-02-23 17:21:11
864 jssldg2 2008-02-23 17:21:13
已选择13行。
发现了一点点痕迹,我们的切换操作是下午3点左右进行的,期间还产生了序列号为860,861之类的归档文件,但并未传输至standby,是不是因为这些文件中包含了一部分应被应用的数据,因此造成standby接收到的新primary传输过来的归档scn与最后应用的scn不连续,所以无法应用?再来验证一下:
JSSLDG2> select applied_scn,latest_scn from v$logstdby_progress;
APPLIED_SCN LATEST_SCN
----------- ----------
1259449 1284126
果然如此,应用的scn与最后的scn确实不匹配,剩下的就好解决了,把所有可疑的应传输到standby的归档文件手工复制到standby,然后通过alter命令注册一下:
JSSLDG2> alter database register logical logfile 'E:ora10goradatajssldg2stdLOG1_859_641301252.ARC';
数据库已更改。
JSSLDG2> alter database register logical logfile 'E:ora10goradatajssldg2stdLOG1_860_641301252.ARC';
数据库已更改。
JSSLDG2> alter database register logical logfile 'E:ora10goradatajssldg2stdLOG1_861_641301252.ARC';
数据库已更改。
提示:复制文件的时候尽可能把相近时间段的归档文件都拷过来,不用担心无用归档会不会影响到应用,oracle会自动判断归档中的scn,对于已经应用过的正常情况下是不会重复应用的,因此我们把859,860,861全部复制过来。
再查看一下应用状态:
JSSLDG2> select sequence#,applied from dba_logstdby_log;
SEQUENCE# APPLIED
---------- --------
862 CURRENT
863 CURRENT
哈哈,已经开始应用了。逻辑standby恢复成功!想起官方文档中有一句提示,说的是在打开新的primary数据库,生成数据字典之前,不要执行任何DDL,不然就只能重建逻辑standby了,估计就是担心执行ddl后不幸触发日志切换,造成逻辑standby接收新primary传来的归档文件不连续,无法顺利应用。
切换完成之后,在修复逻辑standby的同时,顺手打扫一下战场,比如设置新primary数据库的备份策略,以及考虑如何修复前故障的primary等等,dba这份工作,人前看起来光鲜,如果你已经下定决心要从事这行,那对于人后的辛苦一定要有深刻心理准备哟,你看看像上面这种情况,primary只要随随便便宕个机,引之而来的工作量就够我们忙活的。
也许这个时候dba需要的不仅是保持清晰的大脑,还要能打开思路,此时我们更不妨考虑在做角色切换和修复损坏的primary之间做个选择,究竟哪个更快,哪个更简便一些呢,
你看,干dba这行,不仅压力大,不仅要本领过硬,不仅要耐心细致,关键时刻还要保持清醒的头脑,额地神耶,太刺激啦,太有挑战啦~~~~~~
监控逻辑standby
与物理standby的管理一样,oracle提供了一系列动态性能视图来查看逻辑standby的状态,有一些我们前面已经接触过,而有一些,我们还从未用过。。。。。
1、 DBA_LOGSTDBY_EVENTS
可以把该视图看成逻辑standby操作日志,因此如果发生了错误,可以通过该视图查看近期逻辑standby都做了些什么。默认情况下,该视图保留100条事件的记录,不过你可以通过DBMS_LOGSTDBY.APPLY_SET()过程修改该参数。
例如:
JSSLDG2> select event_time,status,event from dba_logstdby_events;
EVENT_TIME STATUS EVENT
------------------- -------------------------------------------------- ----------------------------------------
2008-03-06 08:58:11 ORA-16112: 日志挖掘和应用正在停止
2008-03-06 09:02:00 ORA-16111: 日志挖掘和应用正在启动
2008-03-06 09:52:53 ORA-16128: 已成功完成用户启动的停止应用操作
2008-03-12 15:52:53 ORA-16111: 日志挖掘和应用正在启动
2008-03-12 16:09:17 ORA-16226: 由于不支持而跳过 DDL ALTER DATABASE OPEN
2008-03-05 17:21:46 ORA-16111: 日志挖掘和应用正在启动
..............................
2、 DBA_LOGSTDBY_LOG
该视图用来记录当前的归档日志应用情况,等同于物理standby中的v$archived_log,多数情况下,你只需要关注SEQUENCE#,APPLIED,即查看日志序号和是否应用,当然该视图还能提供更多信息,比如应用的scn,应用时间等,例如:
JSSLDG2> select sequence#,first_change#,next_change#,timestamp,applied from dba_logstdby_log;
SEQUENCE# FIRST_CHANGE# NEXT_CHANGE# TIMESTAMP APPLIED
---------- ------------- ------------ ------------------- --------
869 1319212 1319811 2008-03-12 16:09:15 CURRENT
通常情况下,该查询只会返回几条记录,如果说你的数据库操作非常频繁,可能记录数会稍多一些,但如果记录数非常多,那你可能就需要关注一下,是不是出了什么问题,难道sql应用没有启动?
3、 V$LOGSTDBY_STATS
从名字就大致猜的出来,该视图显示的是状态信息,没错,你猜对了,该视图就是用来显示LogMiner的统计信息及状态。
JSSLDG2> select *from v$logstdby_stats;
NAME VALUE
---------------------------------------------------------------- ---------------
number of preparers 1
number of appliers 5
maximum SGA for LCR cache 30
parallel servers in use 9
maximum events recorded 100
preserve commit order TRUE
transaction consistency FULL
record skip errors Y
record skip DDL Y
record applied DDL N
.........................
4、 V$LOGSTDBY_PROCESS
该视图显示当前log应用服务的相关信息。常用于诊断归档日志逻辑应用的性能问题(后面优化部分会有涉及),包含的信息也很广:
v 身份信息:SID,SERIAL#,SPID
v SQL应用进程:COORDINATOR, READER, BUILDER, PREPARER, ANALYZER, 或APPLIER
v 进程当前的状态:见status_code或status列
v 该进程当前操作redo记录最大SCN:high_scn列
例如:
JSSLDG2> select sid,serial#,spid,type,status,high_scn from v$logstdby_process;
SID SERIAL# SPID TYPE STATUS HIGH_SCN
---------- ---------- ------------ --------------- ------------------------------------------------------------ ----------
145 1 508 COORDINATOR ORA-16116: 无可用工作 1319811
146 2 2464 READER ORA-16240: 正在等待日志文件 (线程号 1, 序列号 870) 1319811
143 1 1512 BUILDER ORA-16116: 无可用工作 1319742
142 1 4000 PREPARER ORA-16116: 无可用工作 1319741
139 1 2980 ANALYZER ORA-16116: 无可用工作 1319707
135 1 1648 APPLIER ORA-16116: 无可用工作 1319430
138 1 2332 APPLIER ORA-16116: 无可用工作 1319439
132 1 2200 APPLIER ORA-16116: 无可用工作 1319443
134 1 4020 APPLIER ORA-16116: 无可用工作
...........................................
5、 V$LOGSTDBY_PROGRESS
该视图显示log应用服务当前进展状况,比如当前应用到逻辑standby的scn及时间,sql应用开始应用的scn及时间,最后接收及应用的scn和时间等等。
例如:
JSSLDG2> select * from v$Logstdby_progress;
APPLIED_SCN APPLIED_TIME RESTART_SCN RESTART_TIME LATEST_SCN LATEST_TIME MINING_SCN MINING_TIME
----------- ------------------- ----------- ------------------- ---------- ------------------- ---------- -------------------
1319810 2008-03-12 16:06:51 1319662 2008-03-12 16:03:22 1319810 2008-03-12 16:45:33 1319811 2008-03-12 16:06:51
6、 V$LOGSTDBY_STATE
该视图就最简单了,就是显示sql应用的大致状态,比如primary库的dbid啦,是否启动了实时应用啦,当前sql应用的状态啦之类。
注意state列,该列可能有下述的几种状态:
v INITIALIZING: LogMiner session已创建并初始化
v LOADING DICTIONARY: SQL应用调用LogMiner字典
v WAITING ON GAP: SQL应用正等待日志文件,可能有中断
v APPLYING: SQL应用正在工作
v WAITING FOR DICTIONARY LOGS: SQL应用等待LogMiner字典信息
v IDLE: SQL应用工作非常出色,已经干的没什么可干了:)
例如:
JSSLDG2> select * from v$Logstdby_state;
PRIMARY_DBID SESSION_ID REALTIME_APPLY STATE
------------ ---------- -------------------- ------------------------------
3408827880 42 Y APPLYING
管理逻辑standby
1、 接收到的归档文件
前章曾经提到,逻辑standby应用完归档后会自动删除该归档文件,该特性你如果觉着不爽,没关系,执行下面这个过程,屏蔽掉它:
JSSLDG2> EXECUTE DBMS_LOGSTDBY.APPLY_SET('LOG_AUTO_DELETE', FALSE);
提示:这种操作并非毫无意义,比如说逻辑standby打开了flashback database,那如果你想恢复到之前的某个时间点,然后再接着应用,就必须要有该时间点后对应的归档,假如LOG_AUTO_DELETE为TRUE的话,显然应用过的归档就不存在了,想回都回不去。
2、 启动实时应用
默认情况下,log应用服务会等待单个归档文件全部接收之后再启动应用(在前面redo传输服务中我们介绍了不同形式的传输方式),如果standby端使用了standby redologs,就可以打开实时应用(real-time apply),这样dg就不需要再等待接收完归档文件,只要rfs将redo数据写入standby redologs,即可通过MRP/LSP实时写向standby,这样就可以尽可能保持standby与primary的同步。
要启动逻辑standby的实时应用,只需要在启动逻辑standby应用时加上immediate子句即可,前面我们已经无数次的演练过,例如:
JSSLDG2> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
3、 定义DBA_LOGSTDBY_EVENTS视图中事件记录的相关参数。
Dba_logstdby_events视图前面刚讲过,里面记录了逻辑standby的一些操作事件,如果你希望修改该视图中记录的事件信息的话,可以通过下列的方式:
例如,希望该视图能够保留最近999条事件,可以通过执行下列语句:
JSSLDG2> select *from v$logstdby_stats where name='maximum events recorded';
NAME VALUE
---------------------------------------------------------------- ---------------
maximum events recorded 100
JSSLDG2> alter database stop logical standby apply;
数据库已更改。
JSSLDG2> execute dbms_logstdby.apply_set('max_events_recorded','999');
PL/SQL 过程已成功完成。
JSSLDG2> alter database start logical standby apply immediate;
数据库已更改。
JSSLDG2> select *from v$logstdby_stats where name='maximum events recorded';
NAME VALUE
---------------------------------------------------------------- ---------------
maximum events recorded 999
再比如,你如果想在视图中记录ddl操作的信息,可以通过执行下列语句:
JSSLDG2> execute dbms_logstdby.apply_set('RECORD_APPLIED_DDL','TRUE');
4、 指定对象跳过应用,请用DBMS_LOGSTDBY.SKIP
默认情况下,接收自primary的redo数据中,所有能够被standby支持的操作都会在逻辑standby端执行,如果你希望跳过对某些对象的某些操作的话,DBMS_LOGSTDBY.SKIP就能被派上用场了。
先来看看dbms_logstdby.skip的语法:
DBMS_LOGSTDBY.SKIP (
stmt IN VARCHAR2,
schema_name IN VARCHAR2 DEFAULT NULL,
object_name IN VARCHAR2 DEFAULT NULL,
proc_name IN VARCHAR2 DEFAULT NULL,
use_like IN BOOLEAN DEFAULT TRUE,
esc IN CHAR1 DEFAULT NULL);
除stmt外,其它都是可选参数,并且看字面意义就能明白其所指,下面简单描述一下stmt参数调用的关键字都是指定值,详细见下列:
|
STMT关键字 |
包含的操作 |
|
NON_SCHEMA_DDL |
不属于模式对象的所有其它ddl操作 |
|
提示:使用该关键字时, SCHEMA_NAME 和 OBJECT_NAME 两参数也必须指定。 |
|
|
SCHEMA_DDL |
创建修改删除模式对象的所有ddl操作 ( 例如 : tables, indexes, and columns) |
|
提示:使用该关键字时, SCHEMA_NAME 和 OBJECT_NAME 两参数也必须指定。 |
|
|
DML |
Includes DML statements on a table (for example: INSERT, UPDATE, and DELETE) |
|
CLUSTER |
AUDIT CLUSTER CREATE CLUSTER DROP CLUSTER TRUNCATE CLUSTER |
|
CONTEXT |
CREATE CONTEXT DROP CONTEXT |
|
DATABASE LINK |
CREATE DATABASE LINK CREATE PUBLIC DATABASE LINK DROP DATABASE LINK DROP PUBLIC DATABASE LINK |
|
DIMENSION |
ALTER DIMENSION CREATE DIMENSION DROP DIMENSION |
|
DIRECTORY |
CREATE DIRECTORY DROP DIRECTORY |
|
INDEX |
ALTER INDEX CREATE INDEX DROP INDEX |
|
PROCEDURE |
ALTER FUNCTION ALTER PACKAGE ALTER PACKAGE BODY ALTER PROCEDURE CREATE FUNCTION CREATE LIBRARY CREATE PACKAGE CREATE PACKAGE BODY CREATE PROCEDURE DROP FUNCTION DROP LIBRARY DROP PACKAGE DROP PACKAGE BODY DROP PROCEDURE |
|
PROFILE |
ALTER PROFILE CREATE PROFILE DROP PROFILE |
|
ROLE |
ALTER ROLE CREATE ROLE DROP ROLE SET ROLE |
|
ROLLBACK STATEMENT |
ALTER ROLLBACK SEGMENT CREATE ROLLBACK SEGMENT DROP ROLLBACK SEGMENT |
|
SEQUENCE |
ALTER SEQUENCE CREATE SEQUENCE DROP SEQUENCE |
|
SYNONYM |
CREATE PUBLIC SYNONYM CREATE SYNONYM DROP PUBLIC SYNONYM DROP SYNONYM |
|
TABLE |
ALTER TABLE CREATE TABLE DROP TABLE |
|
TABLESPACE |
CREATE TABLESPACE DROP TABLESPACE TRUNCATE TABLESPACE |
|
TRIGGER |
ALTER TRIGGER CREATE TRIGGER DISABLE ALL TRIGGERS DISABLE TRIGGER DROP TRIGGER ENABLE ALL TRIGGERS ENABLE TRIGGER |
|
TYPE |
ALTER TYPE ALTER TYPE BODY CREATE TYPE CREATE TYPE BODY DROP TYPE DROP TYPE BODY |
|
USER |
ALTER USER CREATE USER DROP USER |
|
VIEW |
CREATE VIEW DROP VIEW |
例如,你想跳过jss用户下对tmp1表的dml操作,可以通过执行下列语句实现(执行该过程前需要先停止redo应用):
JSSLDG2> alter database stop logical standby apply;
数据库已更改。
JSSLDG2> execute dbms_logstdby.skip('DML','JSS','TMP1');
PL/SQL 过程已成功完成。
JSSLDG2> alter database start logical standby apply;
数据库已更改。
提示:DBMS_LOGSTDBY.SKIP的功能非常强大,限于篇幅,这里仅举示例,而且由于其操作非常灵活,此篇俺也不可能就其用法做个一一列举,因此,更丰富的操作方式就留待看官们下头自行发现去吧:)
修改逻辑standby端数据
我们前面提到,逻辑standby一个极具实用价值的特性即是可以边查询边应用,因此将其做为报表服务器专供查询是个很不错的想法,而且逻辑standby相对于物理standby而言更具灵活性,比如我们可以在逻辑standby上,对一些表创建primary库上并不方便创建的索引,约束,甚至可以做dml,ddl操作(当然,需要注意不要破坏了与primary之间同步的逻辑关系)。不过由于此时dg仍然控制着对逻辑standby表的读写操作,因此,如果你想对逻辑standby中的数据做些什么的话,alter session database disable|enable guard语句就必须牢记在心了,它拥有像“芝麻开门”一样神奇的能力,不信?下面我们就来感受一下吧。
1、 逻辑standby端执行ddl
在逻辑standby端开始了redo应用的情况下,执行ddl操作:
JSSLDG2> create table tmp55 as select * From b;
create table tmp55 as select * From b
*
第 1 行出现错误:
ORA-01031: 权限不足
看看,出错了吧~~~
JSSLDG2> alter session disable guard;
会话已更改。
JSSLDG2> create table tmp55 as select * From b;
表已创建。
只有关闭了guard保护之后,才能操作数据,然后别忘了再启用guard,以避免不经意的操作对逻辑standby的配置造成影响。
JSSLDG2> alter session enable guard;
会话已更改。
提示:oracle建议还是尽可能不要在逻辑standby执行执行dml之类操作,以免破解其与primary之间同步的逻辑关系,当然,这只是个建议,如果你已经仔细看完了3.1章,并且对数据库表结构及存储结构了如指掌,那您就爱干嘛爱嘛。
2、 取消对象同步
如果说,某些表或者数据不需要dataguard保护(比如一些在逻辑standby端生成的统计表),这个时候就需要DBMS_LOGSTDBY.SKIP,前头已经介绍过了dbms_logstdby.skip的基本用法,下面我们来具体演示一下!
下面我们假设standby端有一批表名为tmp开头的表,这张表不再需要保持与primary的同步,那么按照步骤执行下列语句,sql应用即可跳过这些表:
老规矩,先停了redo应用
JSSLDG2> alter database stop logical standby apply;
数据库已更改。
JSSLDG2> execute dbms_logstdby.skip('SCHEMA_DDL','JSS','TMP%');
--跳过对象的ddl操作
PL/SQL 过程已成功完成。
JSSLDG2> execute dbms_logstdby.skip('DML','JSS','TMP%');
--跳过对象的dml操作
PL/SQL 过程已成功完成。
JSSLDG2> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
数据库已更改。
注意其中的%,该符号为通配符,作用与在sql语句中的相同。
OK,下面来测试一下,先看看逻辑standby中表的信息,我们选择两张表,一张是我们前面已经指定了跳过的表tmp1,另一张是普通表b:
JSSLDG2> select max(aa) from jss.tmp1;
Max(aa)
--------------------
h
JSSLDG2> select max(id) from jss.b;
Max(id)
----------
9
JSSLDG2> select sequence#,applied from dba_logstdby_log;
SEQUENCE# APPLIED
---------- --------
872 YES
然后在primary数据库执行插入操作
JSSWEB> select max(aa) from jss.tmp1;
Max(aa)
--------------------
h
JSSWEB> insert into jss.tmp1 values ('i');
已创建 1 行。
JSSWEB> insert into jss.b values (10);
已创建 1 行。
JSSWEB> commit;
提交完成。
JSSWEB> alter system switch logfile;
系统已更改。
JSSWEB> select max(sequence#) from v$archived_log;
MAX(SEQUENCE#)
--------------
873
再来看看逻辑standby端的同步情况:
JSSLDG2> select sequence#,applied from dba_logstdby_log;
SEQUENCE# APPLIED
---------- --------
873 YES
显然日志已经接收,再看看数据:
JSSLDG2> select max(id) from b;
Max(id)
----------
10
JSSLDG2> select max(aa) from jss.tmp1;
Max(aa)
--------------------
h
b表已应用,而tmp1表则无变化。
3、 恢复对象同步
如果说某些表某个时候取消了同步,现在希望再恢复同步,没问题,DBMS_LOGSTDBY家大业大,它还有个叫UNSKIP的门生就是专干这个的。
我们来看一下dbms_logstdby.unskip的语法:
DBMS_LOGSTDBY.UNSKIP (
stmt IN VARCHAR2,
schema_name IN VARCHAR2,
object_name IN VARCHAR2);
三项均为必选参数,各参数的定义与skip过程相同,这里不再复述。
此处我们来演示恢复tmp%表的同步。
JSSLDG2> select *from dba_logstdby_skip;
ERROR STATEMENT_OPT OWNER NAME U E PROC
----- --------------- ---------- --------------- - - --------------------
N SCHEMA_DDL JSS TMP% Y
N DML JSS TMP% Y
N DML JSS TMP1 Y
........
JSSLDG2> alter database stop logical standby apply;
数据库已更改。
JSSLDG2> execute dbms_logstdby.unskip('DML','JSS','TMP1');
--本步操作是为解决历史遗留问题,不用关注
PL/SQL 过程已成功完成。
JSSLDG2> execute dbms_logstdby.unskip('DML','JSS','TMP%');
PL/SQL 过程已成功完成。
JSSLDG2> execute dbms_logstdby.unskip('SCHEMA_DDL','JSS','TMP%');
PL/SQL 过程已成功完成。
跳过同步已经取消了,紧接着我们需要再调用dbms_logstdby.instantiate_table过程重新同步一下跳地的对象,将skip这段时间,primary对tmp1表所做的操作同步过来(就俺看来,instantiate_table过程实际上是借助dblink重建了一遍对象),以保持与primary的一致。Dbms_logstdby.instantiate_table的语法如下:
DBMS_LOGSTDBY.INSTANTIATE_TABLE (
schema_name IN VARCHAR2,
table_name IN VARCHAR2,
dblink IN VARCHAR2);
使用DBMS_LOGSTDBY.INSTANTIATE_TABLE过程重新执行一下同步(执行前别忘了暂停redo应用):
JSSLDG2> EXECUTE DBMS_LOGSTDBY.INSTANTIATE_TABLE('JSS','TMP1','GETJSSWEB');
PL/SQL 过程已成功完成。
JSSLDG2> select *from jss.tmp1;
AA
--------------------
a
b
c
d
e
f
g
h
i
已选择9行。
数据已重建,下面测试一下该表的redo应用是否恢复了。
JSSWEB> insert into jss.tmp1 values ('j');
已创建 1 行。
JSSWEB> insert into jss.tmp1 values ('k');
已创建 1 行。
JSSWEB> commit;
提交完成。
JSSWEB> alter system switch logfile;
系统已更改。
JSSWEB> select max(sequence#) from v$archived_log;
MAX(SEQUENCE#)
--------------
877
启动逻辑standby端的redo应用,看看对象的应用情况:
JSSLDG2> alter database start logical standby apply immediate;
数据库已更改。
JSSLDG2> select sequence#,applied from dba_logstdby_log;
SEQUENCE# APPLIED
---------- --------
875 YES
876 YES
877 YES
JSSLDG2> select *from jss.tmp1;
AA
--------------------
a
b
c
d
e
f
g
h
i
j
k
已选择11行。
OK,恢复正常啦!
注意哟,此处我们清楚明白的知道我们之前只操作了tmp1一张表,如果是正式应用的话,那你恐怕有必要将所有tmp开头的表都同步一下,不然有可能会造成数据丢失的哟。
特殊事件的控制
时间紧任务急,呵呵,这里三思就只描述流程,过程就不做演示了,相信你的智力,你一定能看懂。
1、 导入传输表空间
v 第一步:屏蔽guard保护,逻辑standby端操作
SQL> ALTER SESSION DISABLE GUARD;
v 第二步:导入传输表空间,逻辑standby端操作
具体操作步骤可参考三思之前的笔记:使用可传输表空间的特性复制数据!
v 第三步:恢复guard保护(或者直接退出本session也成),逻辑standby端操作
SQL> ALTER SESSION ENABLE GUARD;
v 第四步:导入传输表空间,primary端操作
同第二步。
2、 使用物化视图
SQL应用不支持下列对物化视图的ddl操作:
v create/alter/drop materialized view
v create/alter/drop materialized view log
因此,对于现有逻辑standby,primary端对物化视图的操作不会传播到standby端。不过,对于primary创建物化视图之后创建逻辑standby,则物理视图也会存在于逻辑standby端。
v 对于同时存在于primary和逻辑standby的ON-COMMIT物化视图,逻辑standby会在事务提交时自动刷新,而对于ON-DEMAND的物化视图不会自动刷新,需要手动调用dbms_mview.refresh过程刷新。
v 对于逻辑standby端建立的ON-COMMIT物化视图会自动维护,ON-DEMAND物化视图也还是需要手工调用dbms_mview.refresh过程刷新。
3、 触发器及约束的运作方式
默认情况下,约束和触发器同样会在逻辑standby端正常工作。
对于有sql应用维护的约束和触发器:
v 约束:由于约束在primary已经检查过,因此standby端不需要再次检查
v 触发器:primary端操作时结果被记录,在standby端直接被应用。
没有sql应用维护的约束和触发器:
v 约束有效
v 触发器有效
优化逻辑standby
1、 创建Primary Key RELY 约束
某些情况下能够有效提高sql应用效率,具体可参见第三部分第一章。
2、 生成统计信息
这个很容易理解嘛,因为cbo要用,生成方式即可用analyze,也可以用dbms_stats包。看你个人喜好了。
3、 调整进程数
A) .调整APPLIER进程数
首先查看当前空闲的applier进程数:
JSSLDG2> SELECT COUNT(*) AS IDLE_APPLIER FROM V$LOGSTDBY_PROCESS
2 WHERE TYPE = 'APPLIER' and status_code = 16166;
IDLE_APPLIER
------------
0
提示:
status_code = 16166 表示进程是空闲状态,可以看到"STATS"为"ORA-16116: no work available",当然空闲的applier进程数为0不一定代表应用应用非常繁忙,也有可能是因为当前没什么需要应用的日志,因此甚至应用进程都没启动:)
检查事务的应用情况:
JSSLDG2> select name,value from v$logstdby_stats where name like 'TRANSACTION%';
NAME VALUE
--------------------- -------
transactions ready 896
transactions applied 871
如果ready-applied的值比applier进程数的两倍还要大,则说明你有必要考虑增加applier进程的数目了,反之如果applied与ready的值差不多大,或者其差比applier进程数还小,则说明applier进程数偏多,你有必要考虑适当减小进程的数目。
如果确认当前applier进程都非常繁忙,要增加applier进程,可按如下步骤操作:
停止sql应用
ALTER DATABASE STOP LOGICAL STANDBY APPLY;
调整applier进程数为20,默认是5个
EXECUTE DBMS_LOGSTDBY.APPLY_SET('APPLY_SERVERS', 20);
重启sql应用
ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
B) .调整PREPARER进程数
需要调整preparer进程数的机会不多,通常只有一种情况:applier进程有空闲,transactions ready还很多,但没有空闲的preparer进程,这时候你可能需要增加一些preparer进程。
要检查系统是否存在这种情况,可以通过下列的sql语句:
首先检查空闲preparer进程数量:
SELECT COUNT(*) AS IDLE_PREPARER FROM V$LOGSTDBY_PROCESS WHERE TYPE = 'PREPARER' and status_code = 16166;
检查事务的应用情况:
select name,value from v$logstdby_stats where name like 'TRANSACTION%';
查看当前空闲的applier进程数:
SELECT COUNT(*) AS IDLE_APPLIER FROM V$LOGSTDBY_PROCESS WHERE TYPE = 'APPLIER' and status_code = 16166;
如果确实需要调整preparer进程数量,可以按照下列步骤,例如:
停止sql应用
ALTER DATABASE STOP LOGICAL STANDBY APPLY;
调整preparer进程数量为4(默认只有1个preparer进程)
EXECUTE DBMS_LOGSTDBY.APPLY_SET('PREPARE_SERVERS', 4);
重启sql应用
ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
4、 调整LCR使用的内存
执行下列语句,查询当前LCR可用的最大内存:
JSSLDG2> select * from v$logstdby_stats where name='maximum SGA for LCR cache';
NAME VALUE
------------------------------------ --------------------
maximum SGA for LCR cache 30
要增加LCR可用的内存,按照下列步骤操作:
停止sql应用:
JSSLDG2> alter database stop logical standby apply;
数据库已更改。
调整内存大小,注意默认单位是M:
JSSLDG2> execute dbms_logstdby.apply_set('MAX_SGA',100);
PL/SQL 过程已成功完成。
重启sql应用
JSSLDG2> alter database start logical standby apply immediate;
数据库已更改。
5、 调整事务应用方式
默认情况下逻辑standby端事务应用顺序与primary端提交顺序相同。
如果你希望逻辑standby端的事务应用不要按照顺序的话,可以按照下列的步骤操作:
① 停止sql应用:
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
② 允许事务不按照primary的提交顺序应用
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET('PRESERVE_COMMIT_ORDER', 'FALSE');
③ 重新启动sql应用
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
恢复逻辑standby按照事务提交顺序应用的话,按照下列步骤:
① 还是先停止sql应用:
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
② 重置参数PRESERVE_COMMIT_ORDER的初始值:
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_UNSET('PRESERVE_COMMIT_ORDER');
③ 重新启动sql应用:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
于data guard的数据应用而言,幕后的导演是LOG_ARCHIVE_DEST_n。本章节我们要学习的内容会很多,这一次,希望你能理清要学习的重点。
关于redo传输服务(Redo Transport Services),它不仅控制着传输redo数据到其它数据库,同时还管理着解决由于网络中断造成的归档文件未接收的过程。
一、如何发送数据
在primary数据库,DataGuard可以使用归档进程(ARCn)或者日志写进程(LGWR)收集redo数据并传输到standby,不过不管你选择归档进程也好,日志写进程也好,都由一个核心参数来控制,它就是:LOG_ARCHIVE_DEST_n,所以,我们先来:
1、认识LOG_ARCHIVE_DEST_n参数
LOG_ARCHIVE_DEST_n(n从1到10)定义redo文件路径。该参数定义必须通过location或service指明归档文件路径。location表示本地路径,service通常是net service name,即接收redo数据的standby数据库。
提示:
对于每一个LOG_ARCHIVE_DEST_n参数,还有一个对应的LOG_ARCHIVE_DEST_STATE_n参数。LOG_ARCHIVE_DEST_STATE_n参数用来指定对应的LOG_ARCHIVE_DEST_n参数是否生效,拥有4个属性值:
l ENABLE:默认值,表示允许传输服务。
l DEFER:该属性指定对应的log_archive_dest_n参数有效,但暂不使用。
l ALTERNATE:禁止传输,但是如果其它相关的目的地的连接通通失败,则它将变成enable。
l RESET:功能与DEFER属性类似,不过如果传输目的地之前有过错误,它会清除其所有错误信息。
例如:指定本地归档路径
LOG_ARCHIVE_DEST_1='LOCATION=/arch1/chicago/'
LOG_ARCHIVE_DEST_STATE_1=ENABLE
又比如,指定redo传输服务
LOG_ARCHIVE_DEST_2='SERVICE=jsspdg'
LOG_ARCHIVE_DEST_STATE_2=ENABLE
当然,LOG_ARCHIVE_DEST_n参数的属性远不止这些。
这些参数都可以通过alter system set语句直接联机修改,修改会在primary下次日志切换时生效,当然你直接shutdown再重启数据库的话也会即时生效:)比如:
SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_2='SERVICE=jsspdg VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE)';
除show parameter log_archive_dest外,还可以通过查询V$ARCHIVE_DEST视图的方式查看参数配置,并且V$ARCHIVE_DEST视图还可以看到更详细的同步信息。
2、使用ARCn归档redo数据
默认情况下,redo传输服务使用ARCn进程归档redo日志。不过ARCn归档进程只支持最高性能的保护模式。如果standby数据库处于其它类型的保护模式,那你必须使用LGWR传输redo数据(为什么会这样呢,三思再来白话几句,我们知道对于最大保护和最高可用性两种模式而言,其实强调的都是一点,redo数据必须实时应用于standby数据库,我们再看来归档,归档是做什么呢?是备份已完成切换的redolog,完成切换的redolog代表着什么呢?说明该redo中所有数据均已提交至数据文件,那好我们再回过头来看,数据已完成提交的redo并且完成了切换还被复制了一份做为归档,这个时候才准备开始传输到standby数据库,这与最大保护和最高可用所要求的实时应用差的简直不是一点半点,现在,你是不是明白了为什么ARCn归档进程只能支持最高性能的保护模式)。
1).初始化参数控制ARCn归档行为
影响ARCn进程的初始化参数有:
LOG_ARCHIVE_DEST_n及LOG_ARCHIVE_MAX_PROCESSES。
关于LOG_ARCHIVE_DEST_n参数的配置前面介绍了一些,我们知道该参数的部分属性与ARCn进程相关,而LOG_ARCHIVE_MAX_PROCESSES初始化参数则可看做是专为ARCn进程量身打造,该参数用来指定最大可被调用的ARCn进程的数量,注意我们指定的是最大值,也就是说数据库在运行过程中是会根据归档的任务繁重程度自动调节归档进程数量的。当然如果说你觉着你的系统归档任务比较繁重,可以通过设置较多的归档进程数量提高归档并发度,但是这个数字也不是越高越好,过高的归档进程数量有可能反而影响系统性能(所谓物极必反就是这个意思,所以这中间是需要你来把握平衡的,当然这方面更多涉及到调优了,非本章所要讲解之重点,就不多说了)。调整该参数可以通过下列语句:
ALTER SYSTEM SET LOG_ARCHIVE_MAX_PROCESSES = n;
注:n>0 and n<=30
2).ARCn的归档过程
primary数据库日志发生切换时就会启动归档:
l 在primary数据库(假设有2个归档进程),一旦ARC0进程完成redolog的归档,ARC1进程即开始传输该归档到standby数据库的指定路径。
l 在standby数据库,RFS进程轮流将redo数据写入standby redo log,再由standby数据库中的ARCn进程将其写入归档,然后通过REDO应用或SQL应用将数据应用到standby数据库。
如图:[024_1.gif]

另外,因为本地的归档进程与远程归档进程间并无联系,注意如果本地存在删除完成备份的归档的策略,需要在删除之前首先确认这些归档已经被传输到standby数据库。
3、使用LGWR归档redo数据
使用LGWR进程与使用ARCn进程有明显不同,LGWR无须等待日志切换及完成归档。
Standby数据库的LGWR进程会先选择一个standby redo log文件映射primary数据库当前redolog的sequence(以及文件大小),一旦primary数据库有redo数据产生,视LOG_ARCHIVE_DEST_n初始化参数中sync或async属性设置,以同步或非同步方式传输到standby数据库。
要继续下面的内容,我们必须先了解与LGWR归档进程密切相关的几个LOG_ARCHIVE_DEST_n参数的属性,如果选择LGWR归档redo数据,那么在LOG_ARCHIVE_DEST_n中必须指定SERVICE和LGWR属性以允许日志传输服务使用LGWR 进程来传送redo数据到远程归档目的地。我们还需要指定SYNC(同步)还是ASYNC(异步)的传输方式,如果指定SYNC属性(如果不明确指定的话,默认是SYNC),则primary数据库任何会产生redo操作都会同步触发网络I/O,并且等到网络I/O全部完成才会继续下面的提交,而如果指定了ASYNC属性,则会primary数据库的操作会先记录online redologs,然后再传输到standby。下面详细看看其流程:
1).LGWR同步归档的流程
例如初始化参数中有如下设置:
LOG_ARCHIVE_DEST_1='LOCATION=E:ora10goradatajssweb '
LOG_ARCHIVE_DEST_2='SERVICE=jsspdg LGWR SYNC NET_TIMEOUT=30'
LOG_ARCHIVE_DEST_STATE_1=ENABLE
LOG_ARCHIVE_DEST_STATE_2=ENABLE
如果设置LOG_ARCHIVE_DEST_n初始化参数SYNC属性,建议同时设置NET_TIMEOUT属性,该属性控制网络连接的超时时间,如果超时仍无响应,则会返回错误信息。
图:[024_2.gif]
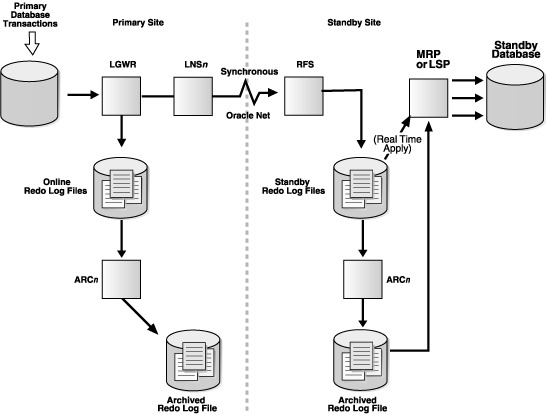
展示了primary数据库LGWR写online redologs的同时,同步传输redo数据到standby数据库的过程。
我们仍然分两部分来解读:
l 在primary数据库,LGWR提交redo数据到LNSn(LGWR Network Server process)进程(n>0),LNSn启动网络传输。
l standby数据库的RFS(Remote File Server)将接收到的redo数据写入standby redolog。特别注意,在此期间,primary数据库的事务会一直保持,直到所有所有含LGWR SYNC属性的LOG_ARCHIVE_DEST_n指定路径均已完成接收。
一旦primary数据库执行日志切换,就会级联触发standby的ARCn将standby redo写入归档,然后通过redo应用(MRP进程)或sql应用(LSP进程)读取归档文件将数据应用至standby数据库。(如果启用了实时应用的话,MRP/LSP会直接读取standby redolog并应用到standby数据库,无须再等待归档)。
2).LGWR不同步归档的流程
例如初始化参数中有如下设置:
LOG_ARCHIVE_DEST_1='LOCATION=E:ora10goradatajssweb '
LOG_ARCHIVE_DEST_2='SERVICE=jsspdg LGWR ASYNC'
LOG_ARCHIVE_DEST_STATE_1=ENABLE
LOG_ARCHIVE_DEST_STATE_2=ENABLE
ASYNC方式归档就不需要再指定NET_TIMEOUT了,因为LGWR与LNSn之间已无关联,所以指定不指定NET_TIMEOUT就都没任何影响了,因此对于异步传输而言,即使网络出现故障造成primary与standby之间通信中断,也并不会影响到primary数据库的提交。
图:[024_3.gif]
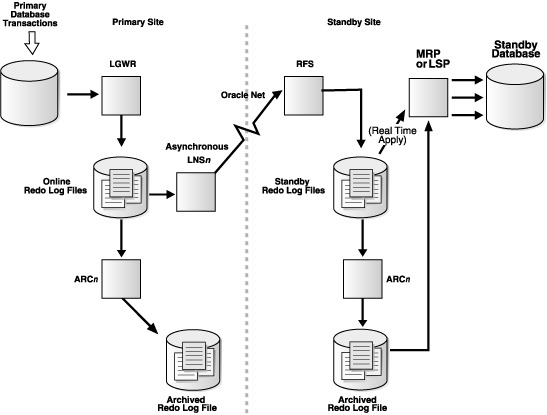
展示了LNSn进程异步传输redo数据到standby数据库RFS进程的过程。
大致步骤与同步传输相同,差别只在LNSn进程这里,LGWR写数据到online redolog,LNSn进程访问online redolog并传输数据到远程standby的RFS而不再与本地LGWR之间有联系。standby数据库方面的处理逻辑仍然不变。
什么时候发送
这小节包含两个内容,发送什么,以及发送给谁:
1、 通过VALID_FOR属性指定传输及接收对象
valid_for,字面理解就是基于xx有效,再配合其redo_log_type,database_role属性,我们基本上可以将其理解为:为指定角色设置日志文件的归档路径,主要目的是为了辅助一旦发生角色切换操作后数据库的正常运转。
redo_log_type可设置为:ONLINE_LOGFILE,STANDBY_LOGFILE,ALL_LOGFILES
database_role可设置为:PRIMARY_ROLE,STANDBY_ROLE,ALL_ROLES
注意valid_for参数是有默认值的,如果不设置的话,其默认值等同于:
valid_for=(ALL_LOGFILES,ALL_ROLES)
推荐主动设置该参数而不要使用默认值,某些情况下默认的参数值不一定合适,比如逻辑standby就不像物理standby,逻辑standby处于open模式,不仅有redo数据而且还包含多种日志文件(online redologs,archived redologs以及standby redologs)。多数情况下,逻辑standby生成的online redologs与standby redologs生成在相同的目录内。因此,推荐你对每个*dest设置合适的valid_for属性。
2、 通过DB_UNIQUE_NAME属性指定数据库
DB_UNIQUE_NAME属性主要是为某个数据库指定唯一的数据库名称,这就使得动态添加standby到包含RAC结构的primary数据库的dg配置成为可能,并且对于log_archive_dest_n中的service属性,其属性值对应的也必然是db_unique_name,也正因有了db_unique_name,redo数据在传输过程中才能确认传输到你希望被传输到的数据库上。当然要保障传输redo数据到指定服务器,除了db_unique_name,log_archive_dest_n之外,还有一个初始化参数:log_archive_config。
关于log_archive_config呢,我们前面有过一些接触,在第二部分第1节中也有一些简单的介绍,log_archive_config初始化参数还包括几个属性,可以用过控制数据库的传输和接收,SEND,NOSEND,RECEIVE,NORECEIVE:
l SEND允许数据库发送数据到远端
l RECEIVE则允许standby接收来自其它数据库的数据
l NOSEND,NORECEIVE自然就是禁止喽。
例如,设置primary数据库不接收任何归档数据,可以做如下的设置:
LOG_ARCHIVE_CONFIG='NORECEIVE,DG_CONFIG=(jssweb,jsspdg)'
当然,你同样也需要注意,一旦做了如上的设置,那么假设该服务器发生了角色切换,那它仍然也没有接收redo数据的能力哟。
出错了咋整
对于归档失败的处理,LOG_ARCHIVE_DEST_n参数有几个属性可以用来控制一旦向归档过程中出现故障时应该采取什么措施,它们是:
1、REOPEN 指定时间后再次尝试归档
使用REOPEN=seconds(默认=300)属性,在指定时间重复尝试向归档目的地进行归档操作,如果该参数值设置为0,则一旦失败就不会再尝试重新连接并发送,直到下次redo数据再被归档时会重新尝试,不过并不会归档到已经失败的归档目的地,而是向替补的归档目的地发送。
2、ALTERNATE 指定替补的归档目的地
alternate属性定义一个替补的归档目的地,所谓替补就是一旦主归档目的地因各种原因无法使用,则临时向alternate属性中指定的路径写。
需要注意一点,reopen的属性会比alternate属性优先级要高,如果你指定reopen属性的值>0,则lgwr/arch会首先尝试向主归档目的地写入,直到达到最大重试次数,如果仍然写入失败,才会向alternate属性指定的路径写。
3、MAX_FAILURE 控制失败尝试次数
max_failure属性指定一个最大失败尝试次数,大家应该能够联想到reopen,没错两者通常是应该配合使用,reopen指定失败后重新尝试的时间周期,max_failure则控制失败尝试的次数,如例:
LOG_ARCHIVE_DEST_1='LOCATION=E:ora10goradatajsspdg REOPEN=60 MAX_FAILURE=3'
管理归档中断
如果primary数据库中的归档日志没能成功发送至standby数据库,就会出现归档中断。当然通常情况下你不需要担心这一点,因为dg会自动检测并尝试复制丢失的归档以解决中断问题,通过什么解决呢?FAL(Fetch Archive Log)。
FAL分server和client,前面创建步骤中讲初始化参数时想必大家也注意到了。FAL client自动主动要求传输归档文件,FAL server则响应FAL client发送的请求。多好的两口子啊。
FAL机制会自动处理下列类似的归档中断问题:
l 当创建物理或逻辑的standby数据库,FAL机制会自动获取primary数据库热备时产生的归档文件。
l 当接收的归档文件出现下列的问题时,FAL机会会自动获取归档文件解决:
? 当接收到的归档在应用之后被删除时;
? 当接收到的归档所在磁盘损坏时;
l 当存在多个物理standby时,FAL机制会自动尝试从其它standby服务器获取丢失的归档文件。
让大家了解这个东西不是为了让你做什么,而是希望你放心,oracle会管理好这些,如果它没有管理好,你明白这个原理,你也能分析一下它为什么没能管理好,通过什么方式能够促使它恢复有效管理的能力,当然你一定要自己动手,也可以,下面通过示例来说明手工处理归档中断(注意,俺只描述步骤,演示俺就不做了。因为三思现在用地最大保护模式,不会丢失归档地说,哇哈哈哈:))
1、 首先你要确认一下standby是否存在归档中断
可以通过查询v$archive_gap视图来确定,如果有记录就表示有中断。
SQL> select *from v$archive_gap;
这一步的目的是为了取出对应的LOW_SEQUENCE#和HIGH_SEQUENCE#,如果有RAC的话,还需要注意一下THREAD#。
2、 查找sequence对应的归档文件
SQL> SELECT NAME FROM V$ARCHIVED_LOG WHERE THREAD#=1 AND DEST_ID=1 AND SEQUENCE# BETWEEN 7 AND 10;
3、 复制对应的归档文件到standby
注意,如果是RAC的话,要找对机器哟:)
然后通过alter database register logfile命令将这些文件重新注册一下,例如:
SQL> ALTER DATABASE REGISTER LOGFILE 'e:ora10gjsspdgxxxx.arc';
然后重启redo应用即可。
对于逻辑standby的丢失归档处理稍微复杂一点点,因为逻辑standby没有提供类型v$archive_gap;之类的视图,因此我们需要自己想办法来识别是否存在丢失的情况,具体可以通过下列的语句:
SQL> select thread#,sequence#,file_name from dba_logstdby_log l
2 where next_change# not in (
3 select first_change# from dba_logstdby_log where l.thread# = thread#)
4 order by thread#,sequence#;
找出丢失的归档文件后,接着的处理方式与物理standby相同。
关于有三模同学的光荣事迹大家应该都听说了,有不认识的请自觉重温"名词先混个脸熟"篇,下面让三思就有三模同学的高超本领为大家做个展示。
为了便于大家更好的理解,我们先画一个表,表中描述了不同保护模式下LOG_ARCHIVE_DEST_n参数 应该设置 的 属性 :
|
|
最大保护 |
最高可能用 |
最高性能 |
|
REDO写进程 |
LGWR |
LGWR |
LGWR或ARCH |
|
网络传输模式 |
SYNC |
SYNC |
LGWR进程时SYNC或ASYNC,ARCH进程时SYNC |
|
磁盘写操作 |
AFFIRM |
AFFIRM |
AFFIRM或NOAFFIRM |
|
是否需要standby redologs |
YES |
YES |
可没有但推荐有 |
提示:
上面中的各项需求都是满足该保护模式的最低需求,这些需求都是据其特性而定的,同时你也一定要理解,这些需求仅只是保证你完成data guard保护模式的设置,如果你真正理解其特性的需求所希望满足的原因,你还需要做不少其它必要的工作。比如对于最高可用性而言,其根本目地是为了在某一台甚至多台主或备库瘫痪时,数据库仍能够在极短时间内恢复服务,这就不仅需要你将最高可用性保护模式的参数配置正确,还需要你拥有足够多的standby数据库。听明白了没?啥,木有?555555555,你在打击俺语言描述的能力~~~
另外再强调一遍:最大保护和最高可用性都要求standby数据库配置standby redo logs(当然如果考虑角色切换的话,主库肯定也是需要配置的),关于standby redo logs的故事你可以参考第二部分的第一章1.3。
下面我们进入实践将一个data guard配置从最高性能模式改为最高可用性模式:
1、 首先查看当前的保护模式 ---primary数据库操作
SQL> select protection_mode,protection_level from v$database;
PROTECTION_MODE PROTECTION_LEVEL
-------------------- --------------------
MAXIMUM PERFORMANCE MAXIMUM PERFORMANCE
2、 修改初始化参数 --primary数据库操作
SQL> alter system set log_archive_dest_2='SERVICE=jsspdg
2 OPTIONAL LGWR SYNC AFFIRM VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE)
3 DB_UNIQUE_NAME=jsspdg';
系统已更改。
3、 设置新的数据保护模式并重启数据库 --primary数据库操作
语句非常简单,如下:
SQL> alter database set standby database to maximize availability;
数据库已更改。
提示:maximize后可跟{PROTECTION | AVAILABILITY | PERFORMANCE},分别对应最大保护,最高可用性及最高性能。
Down掉数据库,重新启动
SQL> shutdown immediate
数据库已经关闭。
已经卸载数据库。
ORACLE 例程已经关闭。
SQL> startup
ORACLE 例程已经启动。
Total System Global Area 167772160 bytes
Fixed Size 1289484 bytes
Variable Size 121635572 bytes
Database Buffers 37748736 bytes
Redo Buffers 7098368 bytes
数据库装载完毕。
数据库已经打开。
4、 看一下当前的保护模式 --primary数据库操作
SQL> select protection_mode,protection_level from v$database;
PROTECTION_MODE PROTECTION_LEVEL
-------------------- --------------------
MAXIMUM AVAILABILITY MAXIMUM AVAILABILITY
5、 修改standby初始化参数设置(主要考虑角色切换,如果只测试的话本步可跳过) ---standby数据库操作
SQL> alter system set log_archive_dest_2='SERVICE=jssweb OPTIONAL LGWR SYNC AFFIR M
2 VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=jssweb';
系统已更改。
查看当前的保护模式
SQL> select instance_name from v$instance;
INSTANCE_NAME
----------------
jsspdg
SQL> select protection_mode,protection_level from v$database;
PROTECTION_MODE PROTECTION_LEVEL
-------------------- --------------------
MAXIMUM AVAILABILITY MAXIMUM AVAILABILITY
配置成功,正面顺便再测试一下。
6、 停掉standby数据库,再查看primary数据库状态
SQL> select protection_mode,protection_level from v$database;
PROTECTION_MODE PROTECTION_LEVEL
-------------------- --------------------
MAXIMUM AVAILABILITY RESYNCHRONIZATION
Standby数据库shutdown后,primary数据库保护级别切换为待同步。
前面我们已经接触了很多相关的概念,我们都知道DataGuard通过应用redo维持primary与各standby之间的一致性,在后台默默无闻支撑着的就是传说中的Log应用服务。Log应用服务呢,又分两种方式,一种是redo应用(物理standby使用,即介质恢复的形式),另一种是sql应用(逻辑standby使用,通过LogMiner分析出sql语句在standby端执行)。
一、 Log应用服务配置选项
1、 REDO数据实时应用
默认情况下,log应用服务会等待单个归档文件全部接收之后再启动应用(在前面redo传输服务中我们介绍了不同形式的传输方式),如果standby端使用了standby redologs,就可以打开实时应用(real-time apply),这样dg就不需要再等待接收完归档文件,只要rfs将redo数据写入standby redologs,即可通过MRP/LSP实时写向standby。
物理standby启用实时应用通过下列语句:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE ;
逻辑standby启用实时应用通过下列语句:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
2、 REDO数据延迟应用
有实时就有延迟,某些情况下你可能不希望standby与primary太过同步:),那就可以在log_archive_dest_n参数中指定delay属性(单位为分钟,如果指定了delay属性,但没有指定值,则默认是30分钟)。注意,该属性并不是说延迟发送redo数据到standby,而是指明归档到standby后,开始应用的时候。
不过,即使在log_archive_dest_n中指定了delay属性,但如果你应用数据时指定了实时应用,则standby会忽略delay属性。另外,standby端还可以通过下列的语句取消延迟应用。
物理standby取消延迟应用可以通过下列语句:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE NODELAY;
逻辑standby取消延迟应用可以通过下列语句:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY NODELAY;
提示:flashback database也可视为延迟应用的一种方式。
二、 应用redo数据到物理standby
注意: 启动redo应用,物理standby需要首先启动到mount状态,然后再执行下列语句启动,或者停止redo应用。
1、 启动redo应用
v 前台应用
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE;
v 后台应用
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT;
v 启动实时应用,附加USING CURRENT LOGFILE子句即可
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE;
2、 停止redo应用
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;
三、 应用redo数据到逻辑standby
注意: 启用sql应用,逻辑standby需要启动至open状态。
1、 启动sql应用
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY;
如果要启动实时应用,附加immediate子句即可:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
2、 停止sql应用
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
=============================================
如果你看过三思之前的几个笔记系列,那么对于rman想必已经非常熟悉,操作这个必然也不成问题,如果你还没有看过,建议你先回去看看,然后再回来操作必然也没有问题,如果你一定不准备看,没关系,只要你严格按照实践部分的步骤操作,我相信你一定也可以创建成功,操作应该也没有问题,不过如果这样你也觉着没有问题,那么我要告诉你,可能就这是最大的问题:不知道做过什么,不知道该做什么,不知道为什么要做,一旦需求稍变,你甚至什么都不敢做。
你什么都不用说,我知道,你还有问题,下面,我们先来看你下意识的第一个问题,为什么要用rman创建物理standby?Oracle告诉我们,有三点:
l RMAN创建standby是通过primary的备份,因此不会对primary有任何的影响
l RMAN自动重命名OMF的文件及路径结构。
l RMAN修复归档日志文件并执行恢复以尽可能保证standby与primary数据一致相同。
当然,我们也应该知道,上述这些都是形容词,它只是为了强化意识,说到这里再多白话几句,第一条呢还说的过去(虽然你不用rman备份,使用其它方式的备份创建standby也不会对primary造成影响),第二条第三条就完全不靠谱了,并不是说它实现不了,恰恰相反,是它描述的太基础了,形容手法有问题,我举个例子,比如你在鱼缸里看到一条鱼,你会不会形容说哇这条鱼能够在水里游耶(死鱼才不会在水里游呢)~~所以鉴别能力很重要,虽然这点我做的还很不够,但是请首长们放心,我一定会努力的,我一定会加强的,我一定会坚持的!!!
回到这个问题上来,为什么要用rman来创建物理standby呢,在我看来如果说有优势那么就一点:简单!
另外在这里三思更明确的指出,使用RMAN的duplicate命令只能直接创建物理standby,幸还是不幸?
一、 准备工作
注意,在做任何操作之前,需要确认以下几点:
l 拥有至少一份通过rman创建的备份;
l 已经在primary数据库设置了所有相关的初始化参数;
l 已经创建了standby的初始化参数文件并配置了所有相关的初始化参数;
l 已经配置了实例,NetService,Listener等;
l 启动standby实例到nomount状态;
然后:
1、 通过rman创建standby的控制文件
创建standby的控制文件前面我们提到通过sql命令,使用非常简单,使用rman命令创建与之同理,并且有两种方式创建演示如下:
1).
RMAN> backup current controlfile for standby;
2).
RMAN> copy current controlfile for standby to 'e:ora10goradatajssrmanJSSRMAN01.CTL';
2、 定制standby数据(日志)文件重命名策略
为什么oracle要提供重命名策略呢?因为dg配置非常灵活,standby甚至可以与primary在同一个数据库。
什么时候需要应用重命名策略呢?如果standby与primary在同一台服务器,或虽然不在同一台服务器,但standby的目录结构与primary不同,这两种情况下,都必须应用重命名策略。如果standby与primary不在同一台服务器,并且目录结构相同,那就不需要应用重命名策略。
如何应用重命名策略呢?多种方式,比如我们的老朋友初始化参数:db_file_name_convert,log_file_name_convert。还有rman命令 SET NEWNAME 或CONFIGURE AUXNAME等等 ,这些相关参数、命令的应用我们都在"Duplicate复制数据库"系列中介绍并应用过,后面还会再次提及。
二、 大致流程
通常情况下,rman创建完standby之后不会自动执行recover。
如果你执行duplicate命令时没有指定dorecover参数,则rman自动按照下面的步骤操作:
1、 RMAN连接standby与primary,及catalog(如果使用了的话);
2、 检索catalog(nocatalog的话是primary数据库的控制文件),确定primary的备份以及standby控制文件;
3、 如果使用介质恢复,RMAN需要连接介质管理器以获取所需备份数据;
4、 恢复standby控制文件到standby服务器;
5、 恢复primary数据库备份集中相应数据文件到standby服务器;
6、 rman自动将standby数据库打开到mount状态,不过不会自动打开redo应用。
如果执行duplicate命令时指定了dorecover参数,则rman会在执行完第5步后,接着执行下列的操作:
7、 在所有数据都restored之后,rman自动执行recovery,如果recovery过程需要归档文件,但是这些文件又不在本地盘,则rman会尝试从备份中获取。
8、 rman执行recovery之前,你可以通过指定time,scn,logfile sequence来确定recovery的内容,如果什么都不指定,则rman一直recover到最后一个归档文件。
9、 rman自动将standby数据库打开到mount状态,同样也不会自动打开redo应用。
三、 方法及步骤
基本上,可以分成二类:
1、 相同目录结构的创建
duplicate不同服务器相同目录结构创建standby的操作极为简单,你即不需要动用DB_FILE_NAME_CONVER/LOG_FILE_NAME_CONVERT之类参数,也不需要通过set newname之类命令,基本步骤如下:
1) 确保已设置standby服务器中所有相关的初始化参数。
2) 确认备份集中文件scn大于或等于控制文件中的scn。
3) 如果需要,可以通过set命令指定time,scn或log序号以执行不完全恢复。
例如:set until scn 152;
提示:注意如果有set,则set与duplicate必须在同一个run命令块中。
4) 如果没有配置自动分配通道的话,需要手工指定至少一条辅助通道。
5) 务必指定nofilenamecheck参数,我们之前"duplicate复制数据库"系列中就曾提到过,异机操作路径相同还必需指定NOFILENAMECHECK。因为此处oracle表现的很傻,它不知道你要恢复的路径是在另一台机器上,它只是认为要恢复到的路径怎么跟目标数据库表现的一样呢?会不会是要覆盖目标数据库啊,为了避免这种情形,于是它就报错。所以一旦异机恢复,并且路径相同,那么你必须通过指定NOFILENAMECHECK来避免oracle的自动识别。
例如脚本如下:
sql> duplicate target database for standby nofilenamecheck dorecover;
注意,dorecover并非是必须参数,如果你不指定的话,则duplicate修复数据文件到服务器,并自动将standby启动到mount状态,不过并不会执行恢复操作。
2、 不同目录结构的创建
对于不同目录结构创建standby(与是否同一台服务器就基本无关了),你需要对数据文件和日志文件路径重新定义,那你的选择可就多多了哟:
a. 使用初始化参数重定义数据文件及日志文件
关于db_file_name_convert和log_file_name_convert两个初始化参数的本领和套路大家已经都很熟悉了,所以呢这里就不多做介绍。duplicate命令在此处执行的时候与相同目录结构执行也没什么不同,所以,你可以认为,这是不同路径下创建standby中,最简单的方式。
b. SET NEWNAME命令重定义数据文件
步骤如下:
l 确保已设置standby服务器中所有相关的初始化参数。
l 确认备份集中文件scn大于或等于控制文件中的scn。
l 如果需要,可以通过set命令指定time,scn或log序号以执行不完全恢复。
l 如果没有配置自动分配通道的话,需要手工指定至少一条辅助通道。
l 通过set newname命令为standby数据文件指定新路径
l 执行duplicate命令。
例如,脚本如下:
RUN
{
# Set new file names for the datafiles
SET NEWNAME FOR DATAFILE 1 TO '?/dbs/standby_data_01.f';
SET NEWNAME FOR DATAFILE 2 TO '?/dbs/standby_data_02.f';
. . .
DUPLICATE TARGET DATABASE FOR STANDBY DORECOVER;
}
c. CONFIGURE AUXNAME命令重定义数据文件
操作步骤皆与上同,不再详述,不过需要注意的是CONFIGURE AUXNAME命令的格式,并且configure命令不能在run块中执行,例如脚本如下:
# set auxiliary names for the datafiles
CONFIGURE AUXNAME FOR DATAFILE 1 TO '/oracle/auxfiles/aux_1.f';
CONFIGURE AUXNAME FOR DATAFILE 2 TO '/oracle/auxfiles/aux_2.f';
. . .
CONFIGURE AUXNAME FOR DATAFILE n TO '/oracle/auxfiles/aux_n.f';
DUPLICATE TARGET DATABASE FOR STANDBY;
最后,务必注意,configure auxname命令执行是一直生效的,因此duplicate执行完之后,推荐清除CONFIGURE AUXNAME。这样就不会对未来的类似操作造成影响。
例如:
CONFIGURE AUXNAME FOR DATAFILE 1 CLEAR;
CONFIGURE AUXNAME FOR DATAFILE 2 CLEAR;
. . .
CONFIGURE AUXNAME FOR DATAFILE n CLEAR;
步骤和方法介绍完了,下面实际操作一把~~~~~~~~~~~~~
目标:通过rman备份,在同一台服务器创建standby,primary数据库名为jssweb,要创建的standby,db_unique_name命名为jssrman,因为是在同一台服务器,所以需要对standby的数据文件和日志文件路径做下重定义,这里我们选择通过初始化参数的形式重定义文件路径。
一、 做好准备工作
1、 创建standby实例
需要首先通过ORADIM命令创建一个新的OracleService,非windows环境可以跳过这一步。
E:ora10g>oradim -new -sid jssrman
实例已创建。
E:ora10g>set oracle_sid=jssrman
E:ora10g>sqlplus "/ as sysdba"
.............
顺手配置一下监听,修改tnsname.ora之类,此处不做演示。
2、 创建standby的初始化参数文件
没必要完全重建,首先根据primary的spfile生成一个pfile出来,然后比着改改就是了。例如:
在primary数据库执行,注意是primary数据库:
SQL> create pfile='E:ora10gproduct10.2.0db_1databaseINITjssrman.ora' from spfile;
用任意文本编辑器打开INITjssrman.ora,注意修改相关的化参数,此例中主要修改下列属性:
*.audit_file_dest='e:ora10gproduct10.2.0adminjssrmanadump'
*.background_dump_dest='e:ora10gproduct10.2.0adminjssrmanbdump'
*.control_files='E:ora10goradatajssrmancontrol01.ctl','E:ora10goradatajssrmancontrol02.ctl','E:ora10goradatajssrmancontrol03.ctl'
*.core_dump_dest='e:ora10gproduct10.2.0adminjssrmancdump'
*.DB_FILE_NAME_CONVERT='oradatajssweb','oradatajssrman'
*.db_name='jssweb'
*.DB_UNIQUE_NAME='jssrman'
*.LOG_ARCHIVE_CONFIG='DG_CONFIG=(jssweb,jsspdg,jssrman)'
*.LOG_ARCHIVE_DEST_1='LOCATION=E:ora10goradatajssrman VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=jssrman'
*.LOG_ARCHIVE_DEST_STATE_1='ENABLE'
*.LOG_FILE_NAME_CONVERT='oradatajssweb','oradatajssrman'
*.standby_file_management='AUTO'
*.user_dump_dest='e:ora10gproduct10.2.0adminjssrmanudump'
注意,由于此standby数据库不考虑切换,因为不再配置fal_*,等相关初始化参数。
然后通过该pfile创建standby的spfile,注意是在standby数据库执行:
SQL> create spfile from pfile='E:ora10gproduct10.2.0db_1databaseinitjssrman.ora';
3、 启动standby到nomount状态
SQL> startup nomount
ORACLE 例程已经启动。
Total System Global Area 167772160 bytes
.....................
4、 创建standby的密码文件
注意保持密码与primary数据库相同,非常重要。
E:ora10g>orapwd file=e:ora10gproduct10.2.0db_1databasePWDjssrman.ora password=verysafe entries=30
二、 进行创建工作
1、 连接primary和standby
注意连接standby的时候前面指定auxiliary
E:ora10g>set oracle_sid=jssweb
E:ora10g> rman target / auxiliary sys/tfad04@jssrman
恢复管理器: Release 10.2.0.3.0 - Production on 星期三 1月 30 13:53:13 2008
Copyright (c) 1982, 2005, Oracle. All rights reserved.
已连接到目标数据库: JSSWEB (DBID=3408827880, 未打开)
已连接到辅助数据库: JSSWEB (未装载)
2、 创建standby的控制文件。
我们之前都操作过通过sql命令创建standby的控制文件,这次换一换,在rman中创建standby的控制文件。
RMAN> copy current controlfile for standby to 'e:ora10goradatajssrmancontrol01.ctl';
启动 backup 于 29-1月 -08
使用目标数据库控制文件替代恢复目录
分配的通道: ORA_DISK_1
通道 ORA_DISK_1: sid=157 devtype=DISK
通道 ORA_DISK_1: 启动数据文件副本
复制备用控制文件
输出文件名 = E:ORA10GORADATAJSSRMANCONTROL01.CTL 标记 = TAG20080129T150422 recid = 6 时间戳 = 645289463
通道 ORA_DISK_1: 数据文件复制完毕, 经过时间: 00:00:03
完成 backup 于 29-1月 -08
启动 Control File and SPFILE Autobackup 于 29-1月 -08
段 handle=D:BACKUPC-3408827880-20080129-00 comment=NONE
完成 Control File and SPFILE Autobackup 于 29-1月 -08
3、 生成standby数据库
由于我们此时的备份集是刚刚的,所以在执行duplicate命令时并不需要指定dorecover子句,而且我们采用了通过db_file_name_convert等初始化参数的方式重定义数据文件和日志文件路径,因为执行的命令就非常简单,就这是我们前面说的,不同路径下创建standby中,最简单的方式:
RMAN> duplicate target database for standby;
启动 Duplicate Db 于 30-1月 -08
使用目标数据库控制文件替代恢复目录
分配的通道: ORA_AUX_DISK_1
通道 ORA_AUX_DISK_1: sid=155 devtype=DISK
内存脚本的内容:
{
restore clone standby controlfile;
sql clone 'alter database mount standby database';
}
正在执行内存脚本
启动 restore 于 30-1月 -08
使用通道 ORA_AUX_DISK_1
通道 ORA_AUX_DISK_1: 正在复原控制文件
通道 ORA_AUX_DISK_1: 已复制控制文件副本
输出文件名=E:ORA10GORADATAJSSRMANCONTROL01.CTL
输出文件名=E:ORA10GORADATAJSSRMANCONTROL01.CTL
输出文件名=E:ORA10GORADATAJSSRMANCONTROL02.CTL
输出文件名=E:ORA10GORADATAJSSRMANCONTROL03.CTL
完成 restore 于 30-1月 -08
sql 语句: alter database mount standby database
释放的通道: ORA_AUX_DISK_1
内存脚本的内容:
{
set newname for tempfile 1 to
"E:ORA10GORADATAJSSRMANTEMP01.DBF";
switch clone tempfile all;
set newname for datafile 1 to
"E:ORA10GORADATAJSSRMANSYSTEM01.DBF";
set newname for datafile 2 to
"E:ORA10GORADATAJSSRMANUNDOTBS01.DBF";
set newname for datafile 3 to
"E:ORA10GORADATAJSSRMANSYSAUX01.DBF";
set newname for datafile 4 to
"E:ORA10GORADATAJSSRMANUSERS01.DBF";
set newname for datafile 5 to
"E:ORA10GORADATAJSSRMANTBSWEB01.DBF";
restore
check readonly
clone database
;
}
正在执行内存脚本
正在执行命令: SET NEWNAME
临时文件 1 在控制文件中已重命名为 E:ORA10GORADATAJSSRMANTEMP01.DBF
正在执行命令: SET NEWNAME
正在执行命令: SET NEWNAME
正在执行命令: SET NEWNAME
正在执行命令: SET NEWNAME
正在执行命令: SET NEWNAME
启动 restore 于 30-1月 -08
分配的通道: ORA_AUX_DISK_1
通道 ORA_AUX_DISK_1: sid=155 devtype=DISK
通道 ORA_AUX_DISK_1: 正在开始恢复数据文件备份集
通道 ORA_AUX_DISK_1: 正在指定从备份集恢复的数据文件
正将数据文件00001恢复到E:ORA10GORADATAJSSRMANSYSTEM01.DBF
正将数据文件00002恢复到E:ORA10GORADATAJSSRMANUNDOTBS01.DBF
正将数据文件00003恢复到E:ORA10GORADATAJSSRMANSYSAUX01.DBF
正将数据文件00004恢复到E:ORA10GORADATAJSSRMANUSERS01.DBF
正将数据文件00005恢复到E:ORA10GORADATAJSSRMANTBSWEB01.DBF
通道 ORA_AUX_DISK_1: 正在读取备份段 D:BACKUP4J6V1SJ_1_1
通道 ORA_AUX_DISK_1: 已恢复备份段 1
段句柄 = D:BACKUP4J6V1SJ_1_1 标记 = TAG20080124T111011
通道 ORA_AUX_DISK_1: 恢复完成, 用时: 00:00:57
完成 restore 于 30-1月 -08
内存脚本的内容:
{
switch clone datafile all;
}
正在执行内存脚本
数据文件 1 已转换成数据文件副本
输入数据文件副本 recid=11 stamp=645372185 文件名=E:ORA10GORADATAJSSRMANSYSTEM01.DBF
数据文件 2 已转换成数据文件副本
输入数据文件副本 recid=12 stamp=645372185 文件名=E:ORA10GORADATAJSSRMANUNDOTBS01.DBF
数据文件 3 已转换成数据文件副本
输入数据文件副本 recid=13 stamp=645372186 文件名=E:ORA10GORADATAJSSRMANSYSAUX01.DBF
数据文件 4 已转换成数据文件副本
输入数据文件副本 recid=14 stamp=645372186 文件名=E:ORA10GORADATAJSSRMANUSERS01.DBF
数据文件 5 已转换成数据文件副本
输入数据文件副本 recid=15 stamp=645372186 文件名=E:ORA10GORADATAJSSRMANTBSWEB01.DBF
完成 Duplicate Db 于 30-1月 -08
4、 重建standby临时表空间数据文件
提示:本步非必须,如果该standby不会切换为primary并且也不会有查询需求,就不必创建!
三、 完成善后工作
善后工作通常很不起眼但是很重要,
1、 修改primary数据库中的相关参数
SQL> show parameter db_unique
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_unique_name string jssweb
SQL> set sqlprompt Jssweb>
Jssweb> alter system set log_archive_config='DG_CONFIG=(jssweb,jsspdg,jssrman)';
系统已更改。
Jssweb> alter system set log_archive_dest_3='SERVICE=jssrman lgwr async valid_for=(online_logfiles,primary_role) db_unique_name=jssrman';
系统已更改。
Jssweb> alter system set log_archive_dest_state_3=enable;
系统已更改。
2、 考虑到为保证切换后,dg仍能正常运转,同时修改待切换的standby数据库初始化参数
SQL> show parameter db_unique
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_unique_name string jsspdg
SQL> set sqlprompt Jsspdg>
Jsspdg> alter system set log_archive_config='DG_CONFIG=(jssweb,jsspdg,jssrman)';
系统已更改。
Jsspdg> alter system set log_archive_dest_3='SERVICE=jssweb lgwr async valid_for=(online_logfiles,primary_role) db_unique_name=jssweb';
系统已更改。
Jsspdg> alter system set log_archive_dest_state_3=enable;
系统已更改。
3、 打开standby的redo应用
SQL> show parameter db_unique
NAME TYPE VALUE
------------------------------------ ---------------------- ------------------------------
db_unique_name string jssrman
SQL> set sqlprompt Jssrman>
Jssrman> alter database recover managed standby database disconnect from session;
数据库已更改。
4、 Primary切换日志,验证同步效果
Jssweb> alter system switch logfile;
系统已更改。
Jssweb>select max(sequence#) from v$archived_log;
MAX(SEQUENCE#)
--------------
787
Jsspdg>select max(sequence#) from v$archived_log;
MAX(SEQUENCE#)
--------------
787
Jssrman>select max(sequence#) from v$archived_log;
MAX(SEQUENCE#)
--------------
787
与之前通过primary物理备份相比,通过rman的duplicate命令创建standby,实际执行的步骤是不是更简单一些了呢,基本上你只需要记住duplicate的用法就好了,其它工作rman都自动帮你干。正象开篇中我说过的那样,为什么要选择通过rman来创建standby呢,因为简单:)
About Me
...............................................................................................................................● 本文来自于三思笔记
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-06-02 09:00 ~ 2017-06-30 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
...............................................................................................................................
拿起手机使用微信客户端扫描下边的左边图片来关注小麦苗的微信公众号:xiaomaimiaolhr,扫描右边的二维码加入小麦苗的QQ群,学习最实用的数据库技术。
