Go的作者Ken Thompson是UTF-8的发明人(也是C,Unix,Plan9等的创始人),因此在关于字符编码上,Go有着独到而周全的设计。本文介绍了Go语言中的三种内置文本类型:string, byte,rune的内部表示与相互转换。
1. 概览
Go中,字符串string是内置类型,与文本处理相关的内置类型还有符文rune和字节byte。
UTF-8编码在Go语言中有着特殊的位置,无论是源代码的文本编码,还是字符串的内部编码都是UTF-8。Go绕开前辈语言们踩过的坑,使用了UTF8作为默认编码是一个非常明智的选择。相比之下,Java,Javascript都使用 UCS-2/UTF16作为内部编码,早期还有随机访问的优势,可当Unicode增长超出BMP之后,这一优势也荡然无存了。相比之下,字节序,Surrogate , 空间冗余带来的麻烦却仍让人头大无比。
标准库
与C语言类似,大多数关于字符串处理的函数都放在标准库里。Go将大部分字符串处理的函数放在了strings,bytes这两个包里。因为在字符串和整型间没有隐式类型转换,字符串和其他基本类型的转换的功能主要在标准库strconv中提供。unicode相关功能在unicode包中提供。encoding包提供了一系列其他的编码支持。
摘要
- Go语言源代码总是采用
UTF-8编码 - 字符串
string可以包含任意字节序列,通常是UTF-8编码的。 - 字符串字面值,在不带有字节转义的情况下一定是
UTF-8编码的。 - Go使用
rune代表Unicode**码位**。一个**字符**可能由一个或多个码位组成(复合字符) - Go string是建立在**字节数组**的基础上的,因此对string使用
[]索引会得到字节byte而不是字符rune。 - Go语言的字符串不是正规化(
normalized)的,因此同一个字符可能由不同的字节序列表示。使用unicode/norm解决此类问题。
基础数据结构
数组与切片
要讨论[]byte和[]rune,就必需先解释Go语言中的数组(Array)与切片(Slice),数组很好理解,和C语言中的数组概念一致,切片则是对数组的引用。
数组Array是固定长度的数据结构,不存放任何额外的信息。很少直接使用,往往用作切片的底层存储。
切片Slice描述了数组中一个连续的片段,Go语言的切片操作与Python较为类似。在底层实现中,切片可以看成一个由三个word组成的结构体,这里word是CPU的字长。这三个字分别是ptr,len,cap,分别代表数组首元素地址,切片的长度,当前切片头位置到底层数组尾部的距离。
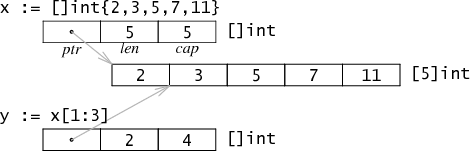
因此,在函数参数中传递十个元素的数组,那么就会在栈上复制这十个元素。而传递一个切片,则实际上传递的是这个3Word结构体。传递切片本身就是传递引用。
字节byte
字节byte实际上是uint8的别名,只是为了和其他8bit类型相区别才单独起了别名。通常出现的更多的是字节切片[]byte与字节数组[...]byte。
字面值
字节可以用单引号扩起的单个字符表示,不过这种字面值和rune的字面值很容易搞混。赋予字节变量一个超出范围的值,如果在编译期能检查出来就会报overflows byte编译错误。
底层结构
对于字节数组[]byte,实质上可以看做[]uint8,即一个整形切片,所以字节数组的本体结构定义如下:
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
字符串string
字符串通常是UTF8编码的文本,由一系列8bit字节组成。raw string literal和不含转义符号的string literal一定是UTF-8编码的,但string其实可以含有任意的字节序列。
字符串是不可变对象,可以空(s=""),但不会是nil。
底层结构
string在Go中的实现与Slice类似,但因为字符串是不可变类型,因此底层数组的长度就是字符串的长度,所以相比切片,string结构的本体少了一个Cap字段。只有一个指针和一个长度值,由两个Word组成。64位机器上占用16个字节。
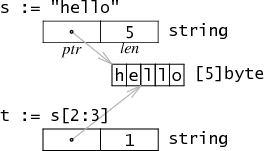
type StringHeader struct {
Data uintptr
Len int
}
虽然字符串是不可变类型,但通过指针和强制转换,还是可以进行一些危险但高效的操作的。不过要注意,编译器作为常量确定的string会写入只读段,是不可以修改的。相比之下,fmt.Sprintf生成的字符串分配在堆上,就可以通过黑魔法进行修改。
关于string,有这么几点需要注意。
string常量会在编译期分配到**只读段**,对应数据地址不可写入。- 相同的
string常量不会重复存储,但动态生成的字符串即使内容一样,数据也是在不同的空间。 - 常量空字符串有数据地址,动态生成的字符串没有设置数据地址 ,只有动态生成的string可以unsafe魔改。
- Golang string和[]byte转换,会将数据复制到堆上,返回数据指向复制的数据。所以string(bytes)存在开销
- string和[]byte通过复制转换,性能损失接近4倍
符文rune
符文rune其实是int32的别名,表示一个Unicode的码位。
注意一个字符(Character)可以由一个或多个码位(Code Point)构成。例如带音调的e,即é,既可以由\u00e9单个码位表示,也可以由e和口音符号\u0301复合而成。这涉及到normalization的问题。但通常情况下一个字符就是一个码位。
>>> print u'\u00e9', u'e\u0301',u'e\u0301\u0301\u0301'
é é é́́
符文的字面值是用单引号括起的一个或多个字符,例如a,啊,\a,\141,\x61,\u0061,\U00000061,都是合法的rune literal。其格式定义如下:
rune_lit = "'" ( unicode_value | byte_value ) "'" .
unicode_value = unicode_char | little_u_value | big_u_value | escaped_char .
byte_value = octal_byte_value | hex_byte_value .
octal_byte_value = `\` octal_digit octal_digit octal_digit .
hex_byte_value = `\` "x" hex_digit hex_digit .
little_u_value = `\` "u" hex_digit hex_digit hex_digit hex_digit .
big_u_value = `\` "U" hex_digit hex_digit hex_digit hex_digit
hex_digit hex_digit hex_digit hex_digit .
escaped_char = `\` ( "a" | "b" | "f" | "n" | "r" | "t" | "v" | `\` | "'" | `"` ) .
其中,八进制的数字范围是0~255,Unicode转义字符通常要排除0x10FFFF以上的字符和surrogate字符。
看上去这样用单引号括起来的字面值像是一个字符串,但当源代码转换为内部表示时,它其实就是一个int32。所以var b byte = '蛤',其实就是为uint8赋了一个int32的值,会导致溢出。相应的,一个rune也可以在不产生溢出的条件下赋值给byte。
文本类型转换
三种基本文本类型之间可以相互转换,当然,有常规的做法,也有指针黑魔法。
string与[]byte的转换
string和bytes的转换是最常见的,因为通常通过IO得到的都是[]byte,例如io.Reader接口的方法签名为:Read(p []byte) (n int, err error)。但日常字符串操作使用的都是string,这就需要在两者之间进行转换。
常规做法
通常[]byte和string可以直接通过类型名强制转化,但实质上执行了一次堆复制。理论上stringHeader只是比sliceHeader少一个cap字段,但因为string需要满足不可变的约束,而[]byte是可变的,因此在执行[]byte到string的操作时会进行一次复制,在堆上新分配一次内存。
// byte to string
s := string(b)
// string index -> byte
s[i] = b
// []byte to string
s := string(bytes)
// string to []byte
bytes := []byte(s)
黑魔法
利用unsafe.Pointer和reflect包可以实现很多禁忌的黑魔法,但这些操作对GC并不友好。最好不要尝试。
type Bytes []byte
// 将string转换为[]byte,'可以修改',很危险,因为[]byte结构要多一个cap字段。
func StringBytes(s string) Bytes {
return (Bytes)(unsafe.Pointer(&s))
}
// 不拷贝地将[]byte转换为string
func BytesString(b []byte) String {
// 因为[]byte的Header只比string的Header多一个Cap字段。可以直接强制成`*String`
return (String)(unsafe.Pointer(&b))
}
// 获取&s[0],即存储字符串的字节数组的地址指针,Go里不允许这种操作。
func StringPointer(s string) unsafe.Pointer {
p := (*reflect.StringHeader)(unsafe.Pointer(&s))
return unsafe.Pointer(p.Data)
}
// r获取&b[0],即[]byte底层数组的地址指针,Go里不允许这种操作
func BytesPointer(b []byte) unsafe.Pointer {
p := (*reflect.SliceHeader)(unsafe.Pointer(&b))
return unsafe.Pointer(p.Data)
}
string与rune的转换
string是UTF8编码的字符串,因此对于非含有ASCII字符的字符串,是没法简单的直接索引的。例如
fmt.Printf("%x","hello"[0]),会取出第一个字节h的相应字节表示uint8,值为:0x68。然而
fmt.Printf("%s","你好"[0]),也是同理,在UTF-8编码中,汉字"你"被编码为0xeE4BDA0由三个字节组成,因此使用下标0去索引字符串,并不会取出第一个汉字字符的int32码位值0x4f60来,而是这三个字节中的第一个0xE4。
没有办法随机访问一个中文汉字是一件很蛋疼的事情。曾经Java和Javascript之类的语言就出于性能考虑使用UCS2/UTF-16来平衡时间和空间开销。但现在Unicode字符远远超过65535个了,这点优势已经荡然无存,想要准确的索引一个字符(尤其是带Emoji的),也需要用特制的API从头解码啦,啪啪啪打脸苍天饶过谁……。
常规方式
string和rune之间也可以通过类型名直接转换,不过string不能直接转换成单个的rune。
// rune to string
str := string(r)
// range string -> rune
for i,r := range str
// string to []rune
runes := []rune(str)
// []rune to string
str := string(runes)
特殊支持
Go对于UTF-8有特殊的支持和处理(因为UTF-8和Go都是Ken发明的……。),这体现在对于string的range迭代上。
const nihongo = "日本語"
for index, runeValue := range nihongo {
fmt.Printf("%#U starts at byte position %d\n", runeValue, index)
}
U+65E5 '日' starts at byte position 0
U+672C '本' starts at byte position 3
U+8A9E '語' starts at byte position 6
直接索引string会得到字节序号和相应字节。而对string进行range迭代,获得的就是字符rune的索引与相应的rune。
byte与rune的转换
byte其实是uint8,而rune实际就是int32,所以uint8和int32两者之间的转换就是整数的转换。
但是[]uint8和[]int32是两个不同类型的整形数组,它们之间是没有直接强制转换的方法的,好在通过string来曲线救国:runes := []rune(string(bytes))