UDF全称User Defined Function,即用户自定义函数。MaxCompute提供了很多内建函数来满足用户的计算需求,同时用户还可以创建自定义函数来满足定制的计算需求。用户能扩展的UDF有三种:UDF(User Defined Scalar Function),UDTF(User Defined Table Valued Function)和UDAF(User Defined Aggregation Function)。
同时,MaxCompute也提供了MapReduce编程接口,用户可以使用MapReduce提供的接口(Java API)编写MapReduce程序处理MaxCompute中的数据。
通过MaxCompute Studio提供的端到端的支持,用户能快速开始和熟悉开发自己的UDF和MapReduce,提高效率。下面我们就以一个例子来介绍如何使用Studio来开发自己的UDF:
创建module
依次点击 File | new | module module类型为MaxCompute Java,配置Java JDK。点击next,输入module名,点击finish。studio会帮用户自动创建一个maven module,并引入MaxCompute相关依赖,具体请查看pom文件。
module结构说明
至此,一个能开发MaxCompute Java程序的module已建立,如下图的mDev。主要目录包括:
- src/main/java:用户开发java程序源码。
- examples:示例代码,包括单测示例,用户可参考这里的例子开发或编写UT。
- warehouse:本地运行时需要的schema和data。

创建UDF
假设我们要实现的UDF需求是将字符串转换为小写(内建函数TOLOWER已实现该逻辑,这里我们只是通过这个简单的需求来示例如何通过studio开发UDF)。studio提供了UDF|UDAF|UDTF|Mapper|Reducer|Driver的模板,这样用户只需要编写自己的业务代码,而框架代码会由模板自动填充。
- 1. 在src目录右键 new | MaxCompute Java
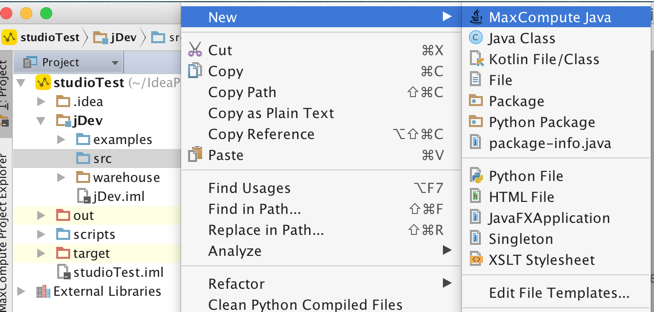
- 2. 输入类名,如myudf.MyLower,选择类型,这里我们选择UDF,点击OK。
![]()
- 3. 模板已自动填充框架代码,我们只需要编写将字符串转换成小写的函数代码即可。
![]()
测试UDF
UDF或MR开发好后,下一步就是要测试自己的代码,看是否符合预期。studio提供两种测试方式:
单元测试
依赖于MaxCompute提供的Local Run框架,您只需要像写普通的单测那样提供输入数据,断言输出就能方便的测试你自己的UDF或MR。在examples目录下会有各种类型的单测实例,可参考例子编写自己的unit test。这里我们新建一个MyLowerTest的测试类,用于测试我们的MyLower:
![]()
sample数据测试
很多用户的需求是能sample部分线上表的数据到本机来测试,而这studio也提供了支持。在editor中UDF类MyLower.java上右键,点击"运行"菜单,弹出run configuration对话框,配置MaxCompute project,table和column,这里我们想将hy_test表的name字段转换为小写:
![]()
点击OK后,studio会先通过tunnel自动下载表的sample数据到本地warehouse(如图中高亮的data文件),接着读取指定列的数据并本地运行UDF,用户可以在控制台看到日志输出和结果打印:
![]()
发布UDF
好了,我们的MyLower.java测试通过了,接下来我们要将其打包成jar资源(这一步可以通过IDE打包,参考用户手册)上传到MaxComptute服务端上:
- 1. 在MaxCompute菜单选择Add Resource菜单项:
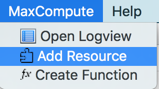
- 2. 选择要上传到哪个MaxCompute project上,jar包路径,要注册的资源名,以及当资源或函数已存在时是否强制更新,然后点击OK。
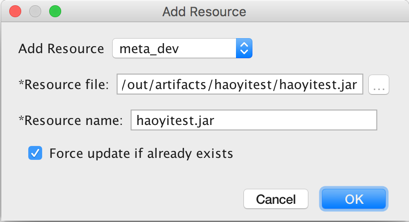
- 3. jar包上传成功后,接下来就可以注册UDF了,在MaxCompute菜单选择Create Function菜单项。
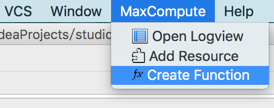
- 4. 选择需要使用的资源jar,选择主类(studio会自动解析资源jar中包含的主类供用户选择),输入函数名,然后点击OK。
![]()
生产使用
上传成功的jar资源和注册成功的function(在Project Explorer相应project下的Resources和Functions节点中就能及时看到,双击也能显示反编译的源码)就能够实际生产使用了。我们打开studio的sql editor,就能愉快的使用我们刚写好的mylower函数,语法高亮,函数签名显示都不在话下:
![]()
MapReduce
studio对MapReduce的开发流程支持与开发UDF基本类似,主要区别有:
- MapReduce程序是作用于整张表的,而且输入输出表在Driver中已指定,因此如果使用sample数据测试的话在run configuration里只需要指定project即可。
- MapReduce开发好后,只需要打包成jar上传资源即可,没有注册这一步。
- 对于MapReduce,如果想在生产实际运行,可以通过studio无缝集成的console来完成。具体的,在Project Explorer Window的project上右键,选择Open in Console,然后在console命令行中输入类似如下的命令:
jar -libjars wordcount.jar -classpath D:\odps\clt\wordcount.jar com.aliyun.odps.examples.mr.WordCount wc_in wc_out;
关于MaxCompute
欢迎加入MaxCompute钉钉群讨论![]()