近期,comSysto公司分享了该公司研发团队利用Spark平台解决Kaggle竞赛问题的经历,为Spark等平台应用于数据科学领域提供了借鉴。
主办方提供了一个包含5万个匿名驾驶员线路的数据集,竞赛的目的是根据路线研发出一个驾驶类型的算法类签名,来表征驾驶员的特征。例如,驾驶员是否长距离驾驶?短距离驾驶?高速驾驶?回头路?是否从某些站点急剧加速?是否高速转弯?所有这些问题的答案形成了表征驾驶员特征的独特标签。
面对此挑战,comSysto公司的团队想到了涵盖批处理、流数据、机器学习、图处理、SQL查询以及交互式定制分析等多种处理模型的Spark平台。他们正好以此挑战赛为契机来增强Spark方面的经验。接下来,本文就从数据分析、机器学习和结果等三个方面介绍comSysto团队解决以上问题的过程。
数据分析
作为解决问题的第一个步骤,数据分析起着非常关键的作用。然而,出乎comSysto公司团队意料的是,竞赛提供的原始数据非常简单。该数据集只包含了线路的若干匿名坐标对(x,y),如(1.3,4.4)、(2.1,4.8)和(2.9,5.2)等。如下图所示,驾驶员会在每条线路中出发并返回到原点 (0,0),然后从原点挑选随机方向再出发,形成多个折返的路线。
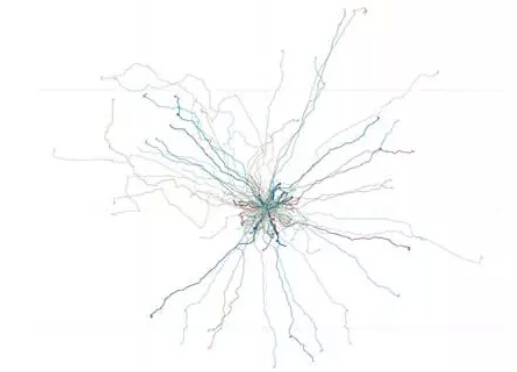
拿到数据后,comSysto公司的团队有些气馁:只看坐标很难表征一个驾驶员吧?!
信息指纹的定义
因此,在原始数据如此简单的情况,该团队面临的一个问题就是如何将坐标信息转换为有用的机器学习数据。经过认证思考,其采用了建立信息指纹库的方法,来搜集每一个驾驶员有意义和特殊的特征。为了获得信息指纹,团队首先定义了一系列特征:
- 距离:所有相邻两个坐标欧氏距离的总和。
- 绝对距离:起点和终点的欧氏距离。
- 线路中停顿的总时间:驾驶员停顿的总时间。
- 线路总时间:某个特定线路的表项个数(如果假设线路的坐标值为每秒钟记录的数值,路线中表项的个数就是线路的总秒数)。
- 速度:某个点的速度定义为该点和前一个点之间的欧氏距离。假设坐标单位为米、坐标之间的记录时间间隔为1秒,该定义所给出的速度单位就为m/s。然而,本次分析中,速度主要用于对比不同点或者不同驾驶员。只要速度的单位相同即可,并不追求其绝对值。对于加速、减速和向心加速度,该说明同样成立。
- 加速度:加速时,该点和前一点速度的差值
- 减速度:减速时,该点和前一点速度的差值
- 向心加速度:
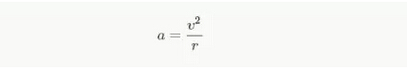
其中,v为速度、r为曲线路径所形成圆的半径。半径计算需要用到当前点、之前和之后的若干个点的坐标信息。而,向心加速度是对驾驶员高速驾驶风格的体现:该值越大表明转弯的速度越快。
一个驾驶员所有线路的上述特征组成了其简历(信息指纹)。根据经验,城市道路和高速道路上的平均速度是不同的。因此,一个驾驶员在所有线路上的平均速度并没有很多意义。ecoSysto选择了城市道路、长距离高速道路和乡村道路等不同路线类型的平均速度和最大速度作为了研究对象。
数据统计:根据统计,本次竞赛的数据集中共包含了2700个驾驶员,共54000个线路的信息。所有的线路共包含3.6亿个X/Y坐标——以每秒记录一个坐标来算,共包含10万个小时的线路数据。
机器学习
在初步的数据准备和特征提取后,ecoSysto团队开始选择和测试用于预测驾驶员行为的机器学习模型。
聚类
机器学习的第一步就是把路线进行分类——ecoSysto团队选择k-means算法来对路线类型进行自动分类。这些类别根据所有驾驶员的所有路线推导得到,并不针对单个驾驶员。在拿到聚类结果后,ecoSysto团队的第一感觉就是,提取出的特征和计算得到的分类与路线长度相关。这表明,他们能够作为路线类型的一个指针。最终,根据交叉验证结果,他们选择了8种类型——每条路线指定了一种类型的ID,用于进一步分析。
预测
对于驾驶员行为预测,ecoSysto团队选择一个随机森林(random forest)算法来训练预测模型。该模型用于计算某个特定驾驶员完成给定路线的概率。首先,团队采用下述方法建立了一个训练集:选择一个驾驶员的约 200条路线(标为“1”——匹配),再加随机选择的其他驾驶员的约200条路线(标为“0”——不匹配)。然后,这些数据集放入到随机森林训练算法中,产生每个驾驶员的随机森林模型。之后,该模型进行交叉验证,并最终产生Kaggle竞赛的提交数据。根据交叉验证的结果,ecoSysto团队选择了10 棵树和最大深度12作为随机森林模型的参数。有关更多Spark机器学习库(MLib)中用于预测的集成学习算法的对比可参考Databrick的博客。
流水线
ecoSysto团队的工作流划分为了若干用Java应用实现的独立步骤。这些步骤可以通过“spark-submit”命令字节提交给Spark执行。流水线以Hadoop SequenceFile作为输入,以CSV文件作为输出。流水线主要包含下列步骤:

- 转换原始输入文件:将原有的55万个小的CSV文件转换为一个单独的Hadoop SequenceFile。
- 提取特征并计算统计数字:利用以上描述的定义计算特征值,并利用Spark RDD变换API计算平均值和方差等统计数字,写入到一个CSV文件中。
- 计算聚类结果:利用以上特征和统计值以及Spark MLlib的API来对路线进行分类。
- 随机森林训练:选取maxDepth和crossValidation等配置参数,结合每条线路的特征,开始随机森林模型的训练。对于实际Kaggle提交的数据,ecoSysto团队只是加载了串行化的模型,并预测每条线路属于驾驶员的概率,并将其以CSV格式保存在文件中。
结果
最终,ecoSysto团队的预测模型以74%的精度位列Kaggle排行榜的670位。该团队表示,对于只花2天之间就完成的模型而言,其精度尚在可接受范围内。如果再花费一定的时间,模型精度肯定可以有所改进。但是,该过程证明了高性能分布式计算平台可用于解决实际的机器学习问题。
本文作者:张天雷
来源:51CTO