Memory is stored within the cache system in units know as cache
lines. Cache lines are a power of 2 of contiguous bytes which are
typically 32-256 in size. The most common cache line size is 64
bytes. False sharing is a term which applies when threads unwittingly
impact the performance of each other while modifying independent
variables sharing the same cache line. Write contention on cache lines
is the single most limiting factor on achieving scalability for parallel
threads of execution in an SMP system. I’ve heard false sharing
described as the silent performance killer because it is far from
obvious when looking at code.
To achieve
linear scalability with number of threads, we must ensure no two threads
write to the same variable or cache line. Two threads writing to the
same variable can be tracked down at a code level. To be able to know
if independent variables share the same cache line we need to know the
memory layout, or we can get a tool to tell us. Intel VTune is such a
profiling tool. In this article I’ll explain how memory is laid out for
Java objects and how we can pad out our cache lines to avoid false
sharing.
 |
| Figure 1. |
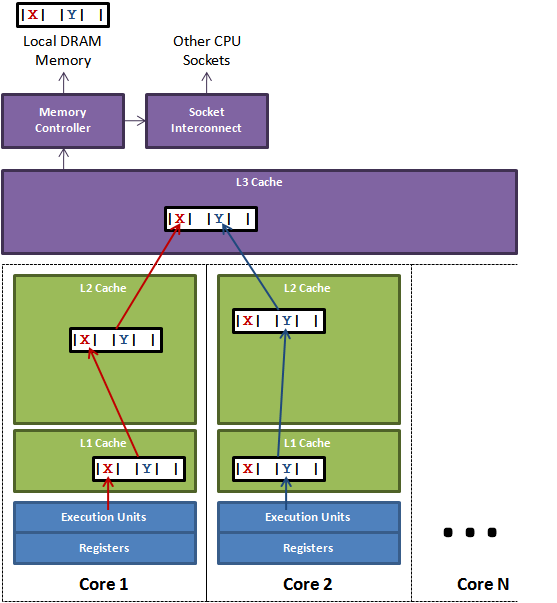
Figure 1. above illustrates the issue of false sharing. A thread
running on core 1 wants to update variable X while a thread on core 2
wants to update variable Y. Unfortunately these two hot variables
reside in the same cache line. Each thread will race for ownership of
the cache line so they can update it. If core 1 gets ownership then the
cache sub-system will need to invalidate the corresponding cache line
for core 2. When Core 2 gets ownership and performs its update, then
core 1 will be told to invalidate its copy of the cache line. This will
ping pong back and forth via the L3 cache greatly impacting
performance. The issue would be further exacerbated if competing cores
are on different sockets and additionally have to cross the socket
interconnect.Java Memory Layout
For the Hotspot JVM, all objects have a 2-word header. First is the
“mark” word which is made up of 24-bits for the hash code and 8-bits for
flags such as the lock state, or it can be swapped for lock objects.
The second is a reference to the class of the object. Arrays have an
additional word for the size of the array. Every object is aligned to
an 8-byte granularity boundary for performance. Therefore to be
efficient when packing, the object fields are re-ordered from
declaration order to the following order based on size in bytes:
- doubles (8) and longs (8)
- ints (4) and floats (4)
- shorts (2) and chars (2)
- booleans (1) and bytes (1)
- references (4/8)
- <repeat for sub-class fields>
With this knowledge we can pad a cache line between any fields with 7 longs. Within the Disruptor we pad cache lines around the RingBuffer cursor and BatchEventProcessor sequences.To
show the performance impact let’s take a few threads each updating
their own independent counters. These counters will be volatile longs so the world can see their progress.
public final class FalseSharing
implements Runnable
{
public final static int NUM_THREADS = 4; // change
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];
static
{
for (int i = 0; i < longs.length; i++)
{
longs[i] = new VolatileLong();
}
}
public FalseSharing(final int arrayIndex)
{
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception
{
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException
{
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++)
{
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads)
{
t.start();
}
for (Thread t : threads)
{
t.join();
}
}
public void run()
{
long i = ITERATIONS + 1;
while (0 != --i)
{
longs[arrayIndex].value = i;
}
}
public final static class VolatileLong
{
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6; // comment out
}
}Results
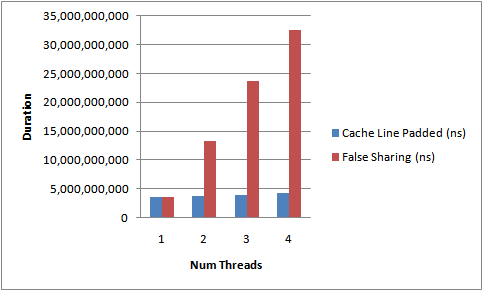
Running the above code while ramping the number of threads and
adding/removing the cache line padding, I get the results depicted in
Figure 2. below. This is measuring the duration of test runs on my
4-core Nehalem.
 |
| Figure 2. |
The impact of false sharing can clearly be seen by the increased
execution time required to complete the test. Without the cache line
contention we achieve near linear scale up with threads.
This is not a perfect test because we cannot be sure where the VolatileLongs will
be laid out in memory. They are independent objects. However
experience shows that objects allocated at the same time tend to be
co-located.
So there you have it. False sharing can be a silent performance killer.
Note: Please read my further adventures with false sharing in this follow on blog.
文章转自 并发编程网-ifeve.com