本文由北邮@爱可可-爱生活 老师推荐,阿里云组织翻译。
以下为译文
如今,微博已成为一种深受互联网用户欢迎的沟通工具。在那些提供微博服务的热门网站上,如Twitter、Tumblr和Facebook,每天都有数以百万的消息产生。这些消息的作者记录自己的生活,分享对不同话题的看法,并讨论当前的问题。由于消息格式不受限制以及微博平台易于访问,互联网用户倾向于从传统沟通工具(如传统的博客和邮件列表)转移到微博服务上来。随着越来越多的用户讨论自己使用的产品和服务,或表达自己的政治和宗教观点,微博网站已经成为人们评论与情感信息的宝贵来源。这样的数据能够有效地用于营销或社交研究[1]。

1 引言
1.1 情感分析的应用
情感分析可应用于众多领域。
A. 电子商务
情感分析最常用于电子商务活动。网站允许其用户发表他们关于购物与产品质量的体验。通过分配等级或分数,这些网站能够为产品和产品的不同功能提供简要的描述。客户可以清楚地查看关于整个产品以及特定产品功能的意见和建议。整个产品与其功能通过图形摘要的形式展示给用户。诸如amazon.com等热门商家网站还会提供来自编辑以及客户的评级信息。http://tripadvisor.in是一家深受欢迎的网站,提供关于旅游目的地酒店的点评。这家网站记录了来自世界各地7500万条的点评信息。通过分析这些海量的评论,情感分析能够帮助这样的网站将不满意的用户转化为其拥护者。
B. 市场呼声(Voice of the Market,VOM)
市场呼声是指消费者关于竞争对手提供的产品与服务的使用感受。及时准确的市场呼声有助于取得竞争优势,并促进新产品的开发。尽早检测这类信息有助于进行直接、关键的营销活动。情感分析能够为企业实时地获取消费者的意见。这种实时的信息帮助企业制定新的营销策略,改进产品功能,并预测产品故障的可能。Zhang等人基于情感分析提出了一种弱点搜索系统,借助中文评论帮助制造商发现他们产品的弱点。目前,有很多商业和免费的情感分析服务可供使用,Radiant6、Sysomos、Viralheat、Lexalytics都提供此类商业服务。www.tweettfeel.com和www.socialmention.com也提供了免费的情感分析工具。
C. 消费者呼声(Voice of the Customer,VOC)
消费者呼声是指个体消费者对产品与服务的评价。这就需要对消费者的评价和反馈进行分析。VOC是客户体验管理中的关键要素。VOC有助于企业抓住产品开发的新机会。提取客户意见同样也能帮助企业确定产品的功能需求和一些关于性能、成本的非功能需求。
D. 品牌声誉管理
品牌声誉管理注重于市场中自身品牌信誉的管理。来自消费者与任何第三方的意见都有可能损害或提升品牌的声誉。与消费者相比,公司更为看中品牌声誉管理(BRM)。如今,一对多式的对话在互联网中占据较大比例,这为机构管理和加强品牌声誉创造了机会。现在的声誉管理不仅由广告、公共关系和企业信息决定。如今,品牌是与上述因素相关的对话的总和。情感分析有助于明确网上社区对公司的品牌、产品以及服务的评价。
E. 政府
通过分析公众的评论,情感分析可以帮助政府评估自身的优势和不足。例如,"如果是这种状况,你还怎么能指望真相浮出水面呢?调查2G手机牌照案的MP自身就很腐败"。这条评论清楚地表达了对政府的负面情绪。无论是跟进公民对新108系统的看法,确定政府岗位在招聘活动中的优势和不足,评价提交电子版纳税申报表的成功与否,还是许多其他的领域,我们都能从中看到情感分析的用武之地。
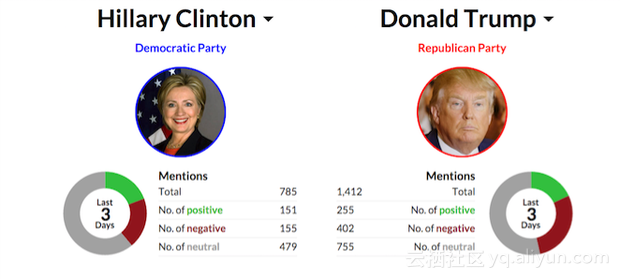
图1:情感分析有助于了解公众情绪是如何影响选举结果的。
1.2 推文的特症
从情感分析的角度,我们讨论Twitter的以下几点特征:
推文长度
一条Twitter消息的最大长度是140个字符。这意味着我们实际上可以将一条推文理解为一个独立的句子,不包含复杂的语法结构。这与情感分析在电影评论等传统主题上的应用有着巨大的差异。
使用的语言
Twitter可通过各种媒体使用,包括短信和手机应用程序。由于这一点和140字符的限制,推文中的语言往往更具口语化,而且含有很多俚语和拼写错误。话题标签在Twitter上也变得越来越流行,它是任何给定推文的重要特征。如图3所示,我们的分析表明,每条推文平均有1-2个话题标签。
数据可用性
另一个不同是可用数据的规模。使用Twitter API可以很轻松地收集到数百万条推文用于算法训练。同时,还有一些提供自动或手工标注推文的数据集可供使用。
话题范围
人们通常就他们喜欢和不喜欢的事物在社交媒体上发表评论。这些评论并不都是关于同一个话题的。基于这一点,使用Twitter数据的算法训练具备了一个得天独厚的优势,不同于那些使用电影影评或其他数据集构造的针对特定领域的分类器,我们可以构造出一个通用的分类器。
2 相关工作
2.1 Go, Bhayani and Huang (2009)
他们将符合检索词的推文划分为负面情绪和正面情绪。他们从Twitter中自动采集数据,以构建训练数据集。为了收集含正面情绪和负面情绪的推文,他们在Twitter中使用表示快乐和悲伤的表情符合进行检索。
- 表示快乐的表情对应不同的笑脸,比如":)"、":-)"、": )"、":D"、"=)"等。
- 表示悲伤的表情包括皱眉,比如":("、":-("、":("等。
他们尝试了各种特征——一元词串、二元词串、词性,使用了不同的机器学习算法训练分类器——朴素贝叶斯、最大熵模型、可伸缩向量机,并通过统计公共语料库中正面与负面词语的数量,和基准分类器的分类结果进行了比较。他们报告称,词性标注与仅使用二元词串对结果并没有帮助,朴素贝叶斯分类器的效果最好。
2.2 Pak and Paroubek (2010),Koulompis, Wilson and Moore (2011)
他们认为,推文中非正式且富有创造性的语言的使用,使面向推文的情感分析任务明显不同于其他情感分析。他们利用过去在话题标签和情感分析上的工作构建自己的分类器,通过爱丁堡的Twitter语料库找出最频繁使用的话题标签,人工地划分这些标签,并反过来使用这些标签对推文进行分类。除了使用n元词串特征和词性特征,他们还根据现有的MPQA主观词汇和网络俚语字典,创建了一个特征集。他们报告称,结合n元词串特征和词汇特征,模型能够取得最好的结果,然而使用词性特征则会导致模型准确率下降。
2.3 Saif, He and Alani (2012)
他们提出了一种基于语义的方法来确定推文中讨论的实体,例如,一个人或者一个组织等。他们也表明,删除停用词并不是一个必要的步骤,甚至可能对分类结果产生不良影响。
上述的所有技术均依赖于n元词串特征。词性标注对结果的改进效果尚不明确。为了提高准确率,一些研究团队采用了不同的特征选择方法和关于微博的杠杆知识。与此相反,我们通过应用情感分析中更加基础的技术,如词干提取、两步分类、否定检测和否定辖域来提高效果。
否定检测是情感分析领域广泛研究的一种技术。诸如"不"、"从不"、"没有"等否定词可以彻底地改变句子的含义以及句子中表达的情感。由于存在着这样的词,邻近词的含义也会变得相反。这些词应该包含在否定辖域内。许多研究都致力于检测否定辖域的范围。
否定词的否定辖域从该词的位置开始,直到下一个标点符号结束。Councill,McDonald和Velikovich (2010)讨论了一种用于识别句子中的否定词及其否定辖域的技术。他们检测文本和作用域中的每一个词,以识别否定词。然后,他们找到它与左右两侧最近的否定词的距离。
3 方法
我们使用了不同的特征集和机器学习分类器来确定适用于Twitter情感分析的最佳组合。 我们还尝试了各种预处理操作,处理文本中的标点符号、表情符号、Twitter特定术语以及词干。我们对以下特征进行了研究——一元词串、二元词串、三元词串、否定检测。最后,我们使用不同机器学习算法——朴素贝叶斯、决策树和最大熵模型,来训练我们的分类器。
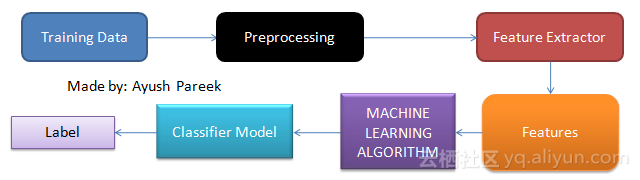
图2:本文方法的简要示意
我们采用了模块化的方法,将特征提取和分类算法组织为两个彼此独立的组件。这使得我们能够为每个组件尝试不同的配置。
3.1 数据集
Twitter情感分析面临的主要挑战之一便是标记数据的采集。研究者们公开了以下数据集用于分类器的训练和测试。
3.1.1 Twitter情感语料库
这个语料库收集了5513条推文,共涵盖四个不同话题,即Apple、Google、Microsoft和Twitter。它由Sanders Analytics LLC收集完成并进行手工分类。语料库中的每一个条目包含推文id、话题和一个情感标签。我们结合Twitter-Python工具库来丰富这份数据集,对于每个推文id,我们下载相应的推文内容、创建时间和创建者等推文数据。推文由一名美国男子手工分为以下四类。出于实验的考虑,我们将不相关和中性归为同一类。表1展示了这个语料库中的推文的示例。
- 正面 对话题表达了正面情绪
- 正面 对话题的看法没有流露出情绪,或表达了混合、较弱的情绪
- 负面 对话题表达了负面情绪
- 中性 非英文文本或与话题无关的评论
| 类别 | 计数 | 示例 |
| 负面 | 529 | #Skype经常崩溃#微软你在搞什么? |
| 中性 | 3770 | #谷歌风投是如何选择哪家初创公司获得它那2亿美金投资的 http://t.co/FCWXoUd8 via @mashbusiness @mashable |
| 正面 | 483 | 现在,@Apple所要做的就是为iPhone添加滑行输入法,这一定会很棒。iPhone就是这样。 |
表1:Twitter情感语料库
3.1.2 斯坦福Twitter语料库
这个推文语料库由斯坦福的自然语言处理研究团队公开提供。训练集通过Twitter API采集得到,使用Twitter API查找表示快乐的表情符号,如":)",和表示悲伤的表情符号,如":(",并将查询得到的推文标记为正面情绪和负面情绪。随后,去除表情符号并删除重复的推文。这个语料库还包含了500条人工采集、标注的推文,用于模型测试。我们从这个数据集中随机抽取了5000条推文用于后续实验。表2展示了这个语料库中的推文的示例。
| 类别 | 计数 | 示例 |
| 负面 | 2501 | 由于节目安排表的缘故,我们排在其他节目后表演,虽然我们可以知道都发生了什么,但是这让整个周六晚上变得好糟糕 |
| 正面 | 2499 | 哈哈!!!@francescazurlo 这首歌你现在唱了多久了?绝对至少一天了。我觉得你特别有趣! |
表2:斯坦福语料库
3.2 预处理
网络上用户产生的内容很少以一种适合算法学习的形式来组织。通过应用一系列预处理操作来规范文本因此变得格外重要。我们采取了一组预处理操作来降低特征集的大小,使其适合于算法训练。图3描述了微博中的各种特征。表3展示了数据集中每条推文各个特征的出现频率。我们也对采取的预处理操作进行了简要的描述。
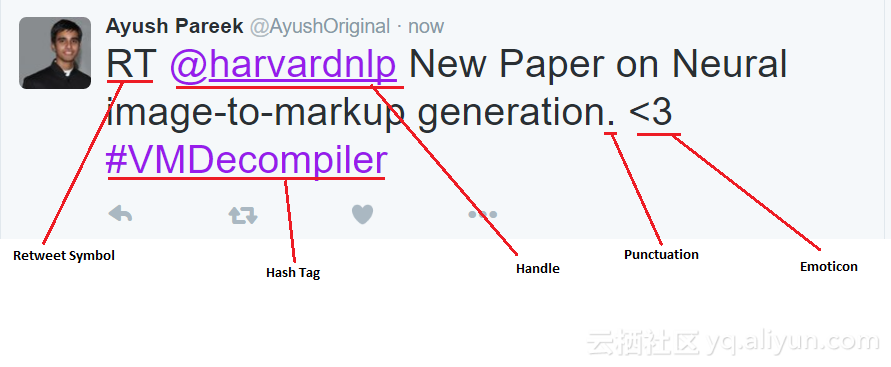
图3:推文中的各种特征
| Twitter情感语料库 | 斯坦福语料库 | 两个语料库 | ||||
| 特征 | 平均 | 最大 | 平均 | 最大 | 平均 | 最大 |
| 用户句柄 | 0.6761 | 8 | 0.4888 | 10 | 0.5804 | 10 |
| 话题标签 | 2.0276 | 13 | 0.0282 | 11 | 1.0056 | 13 |
| 链接 | 0.4431 | 4 | 0.0452 | 2 | 0.2397 | 4 |
| 表情符号 | 0.0550 | 3 | 0.0154 | 4 | 0.0348 | 4 |
| 单词 | 14.4084 | 31 | 13.2056 | 33 | 13.7936 | 33 |
表3:推文各个特征的出现频率
3.2.1 话题标签
话题标签是一个词或一个不含空格的短语,词或短语前面以井字符号(#)为前缀。这些话题标签用来定义当前热门话题的主题和短语。例如,#iPad,#新闻。
正则表达式:#(\w+)
替换表达式:HASH_\1
3.2.2 用户句柄
每一个Twitter用户都有一个唯一的用户名。通过在用户名前面加一个'@'符号,任何东西都可以指向该用户。因此,用户句柄类似于专有名词。例如,@Apple。
正则表达式:@(\w+)
替换表达式:HNDL_\1
3.2.3 链接
用户经常在自己的微博中分享超链接。Twitter使用内部的短链接服务来缩短超链接的长度,例如http://t.co/FCWXoUd8,同时,当这样的链接访问的内容超出本网站范围时,Twitter也可以向用户发出警告。从文本分类的角度来看,特定的超链接并不重要。然而,链接的存在可以作为一个重要的特征。由于推文中可能含有不同类型的链接,用来检测链接的正则表达式是相当复杂的,但是,有了Twitter的短链接服务,我们可以使用一个相对简单些的正则表达式。
正则表达式:(http|https|ftp)://[a-zA-Z0-9\\./]+
替换表达式:URL
3.2.4 表情符号
表情符号的使用在互联网中是非常普遍的,在微博网站上更是如此。我们识别以下表情符号,并将其替换为一个单词。表4列出了目前我们检测的表情符号,除此之外的所有表情符号在预处理过程中都会被忽略掉。
| 表情符号 | 示例 | |||||
| 微笑 | :-) | :) | (: | (-: | ||
| 大笑 | :-D | :D | X-D | XD | xD | |
| 亲亲 | <3 | :* | ||||
| 眨眼 | ;-) | ;) | ;-D | ;D | (; | (-; |
| 皱眉 | :-( | :( | (: | (-: | ||
| 大哭 | :,( | :'( | :"( | :(( | ||
表4:表情符号列表
3.2.5 标点符号
虽然从分类的角度来看,并不是所有的标点符号都是重要的,但其中的一些标点,如问号、感叹号,也能够提供关于文本情感的信息。我们使用一个相关标点列表替换每个单词边界。表5列出了目前我们识别的标点符号。此外,文本中可能存在的单引号也会被移除。
| 标点 | 示例 | |
| 句号 | . | |
| 感叹号 | ! | ¡ |
| 问号 | ? | ¿ |
| 省略号 | ... | … |
表5:标点符号列表
3.2.6 重复字符
人们在表达较口语化的语言时,经常使用重复的字符,例如,"I’m in a hurrryyyyy"、"We won, yaaayyyyy!"。作为我们预处理过程中的最后一步,我们将这些重复超过两次的字符替换为两个字符。
正则表达式:(.)\1{1,}
替换表达式:\1\1
特征空间的缩减
需要注意的是,通过应用这些预处理操作,我们可以降低特征集合的大小,不然,它可能会过于稀疏。表6列出了对各个特征预处理后,特征集大小的减少情况。
| Twitter情感语料库 | 斯坦福语料库 | 两个语料库 | ||||
| 预处理操作 | 单词 | 百分比 | 单词 | 百分比 | 单词 | 百分比 |
| 不作处理 | 19128 | 15910 | 31832 | |||
| 话题标签 | 18649 | 97.50% | 15550 | 97.74% | 31223 | 98.09% |
| 用户句柄 | 17118 | 89.49% | 13245 | 83.25% | 27383 | 86.02% |
| 链接 | 16723 | 87.43% | 15335 | 96.39% | 29083 | 91.36% |
| 表情符号 | 18631 | 97.40% | 15541 | 97.68% | 31197 | 98.01% |
| 标点 | 13724 | 71.75% | 11225 | 70.55% | 22095 | 69.41% |
| 重复字符 | 18540 | 96.93% | 15276 | 96.02% | 30818 | 96.81% |
| 所有预处理操作 | 11108 | 58.07% | 8646 | 54.34% | 16981 | 53.35% |
表6:预处理前后单词的数量
3.3 词干提取算法
所有的词干提取算法都属于以下几种主要类型——基于词缀去除的、基于统计的以及混合型的。第一种类型,即词缀去除算法,是最基本一种词干提取算法。这些词干提取算法应用一组转换规则,试图剥离每个词的前缀和/或后缀[8]。普通的词干提取算法在单词的第N个字符处进行截断。但这很明显在实际场景下并不适用。
J.B. Lovins在1968年提出了第一个词干提取算法。这个算法定义了294种单词后缀,每个词后缀对应29种去除条件中的一种以及35种词后缀转换规则。对于一个被分析的单词,满足某一种去除条件的后缀会被找到并去除。另一种广泛使用的著名词干分析器将在下一节介绍。
3.3.1 Porter词干提取算法
Martin Porter实现了一个词干分析器,并于1980年7月发布。这个词干分析器得到了广泛使用,并最终成为英文词干提取中的一个事实上的标准算法。它在速度、可读性与准确性三者间达到了极好的平衡。这个词干分析器在连续的六个步骤中,使用了约60条转换规则。需要注意的一个重要特征是,该词干分析器并不涉及递归的过程。表7介绍了算法中的各个步骤。
| 1. | 处理复数,以及ed和ing结束的单词 |
| 2. | 如果单词中包含元音,并且以y结尾,将y改为i |
| 3. | 将双后缀的单词映射为单后缀 |
| 4. | 处理-full,-ness等后缀 |
| 5. | 去除-ant,-ence等后缀 |
| 6. | 移除单词末尾的"e" |
表7:Porter词干分析器处理流程
3.3.2 词形还原算法
词形还原是将一个单词规范化的过程,而不仅仅是找到它的词干。在实际的处理过程中,词后缀不仅可以被去除,而且可以被不同的词后缀代替。此类算法可能也会首先检测单词的词性,然后应用规范化规则对单词进行转换。此外,它可能也涉及字典搜寻的过程。例如,动词'saw'会被还原至'see',而名词'saw'则会保持不变。对于我们文本分类的需求而言,词干提取算法就已经足够了。
3.4 特征
各种各样的特征都可以用来构建推文的情感分类器。其中,单词的n元词串是最广泛使用且最基本的特征集。然而,推文中含有很多领域特定信息,这些信息也能够帮助我们对推文进行分类。我们对两组特征进行了实验:
3.4.1 一元词串
一元词串是可用于文本分类的最简单的一组特征。一条推文可以表示成多组单词的形式。然而,我们将推文的一元词串作为一个特征集使用。单词的出现要比它重复的次数更加重要。Pang等人发现,相比词串的重复,一元词串的出现能够产生更好的效果[1]。这也有助于我们避免缩放数据,进而大大减少训练时间[2]。图4介绍了我们数据集中单词的累积分布。
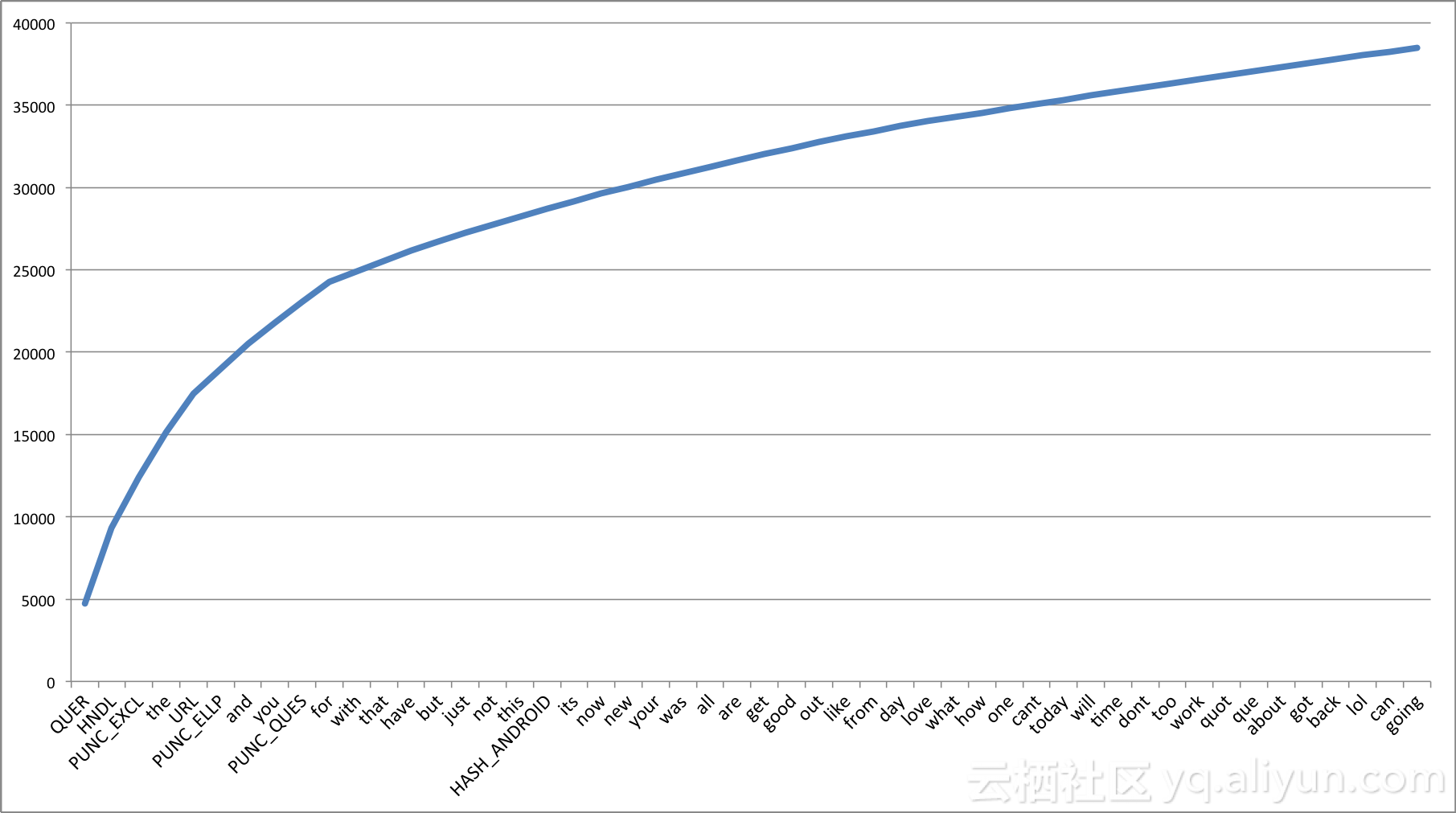
图4:50个最频繁出现的一元词串的累积频率图
我们还观察到,一元词串很好地遵循齐夫定律。这表明,在一个自然语言语料库中,任何单词出现的次数与它在频率表里的排名成反比。图5是我们数据集中单词频率与排名的对数图。数据与线性趋势线很好地吻合。
3.4.2 n元词串
n元词串是指长度为n的单词序列。给定上下文环境,基于一元词串、二元词串和三元词串的概率语言模型可以成功地预测出当前语境的下一个单词。在情感分析领域,多元词串的效果是不明确的。根据Pang等人的研究,一些研究人员报告称,在电影影评分类的应用场景下,单独使用一元词串的效果要优于二元词串,而另一些研究人员声称,二元词串和三元词串在产品评审分类中能够取得更好的效果[1]。
随着n元词串中阶的增长,它们变得越来越稀疏。基于我们的实验,我们发现随着推文数量的增长,二元词串和三元词串数量的增长速度要比一元词串快得多。图5显示了n元词串与推文数量的对比。我们可以注意到,二元词串和三元词串的数量几乎呈线性增长,而一元词串数量的增长趋势仅为对数增长。
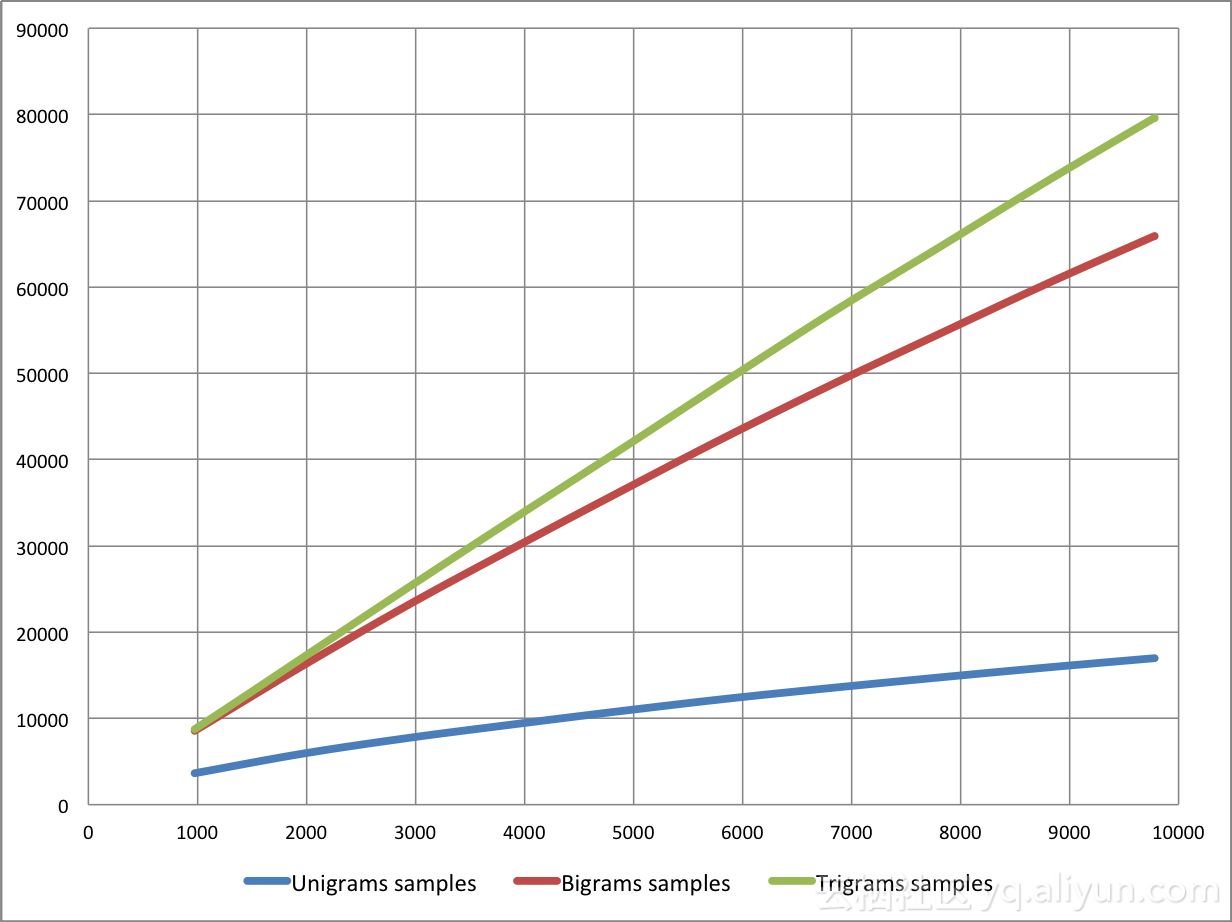
图5:n元词串与推文数量对比
由于高阶n元词串是稀疏的,我们决定去除那些在训练语料库中出现不超过一次的n元词串,因为这些n元词串很可能不是比较好的情绪指标。如图6所示,过滤掉不重复的n元词串后,n元词串的数量显著减少,并且与一元词串的数量级相同。
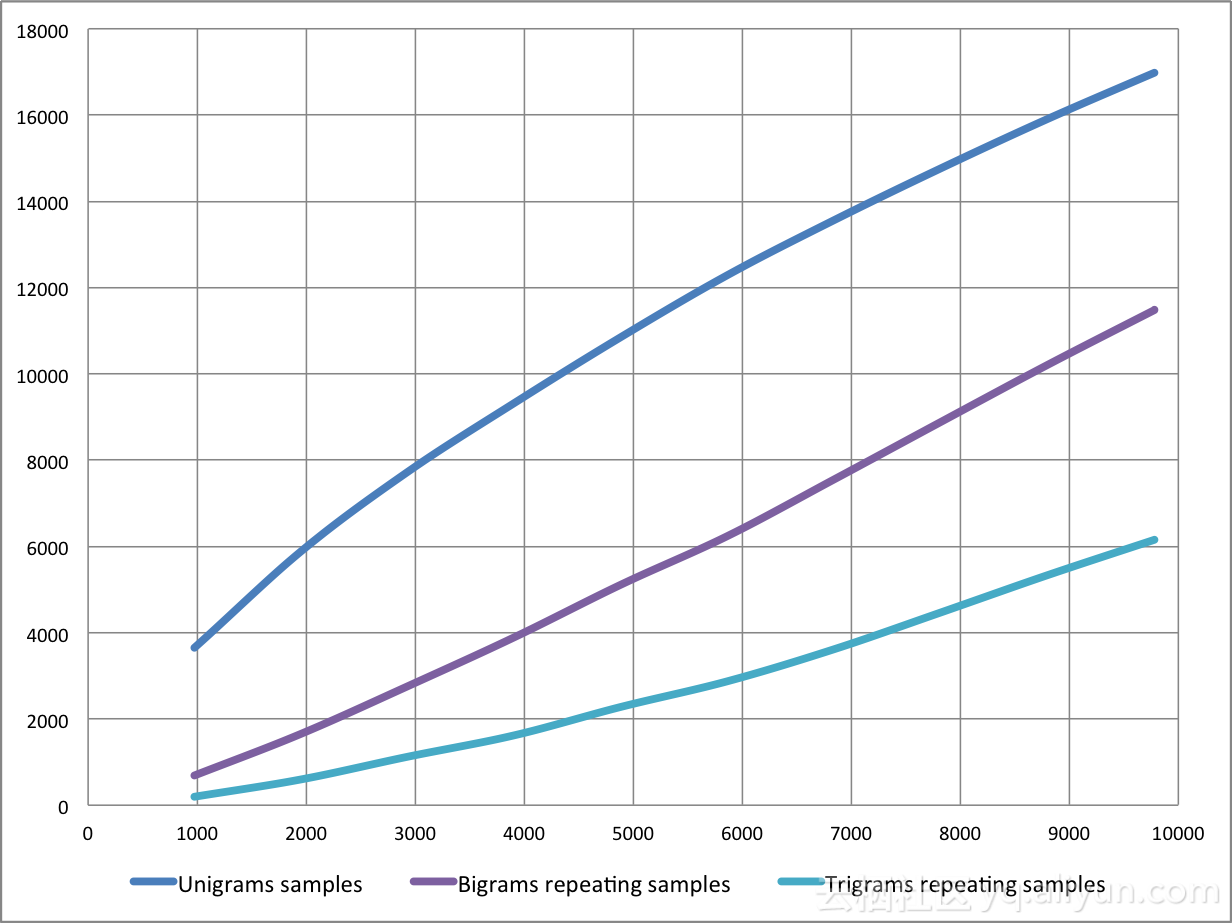
图6:n元重复词串与推文数量对比
3.4.3 否定处理
情感分析需要否定检测,这一点可以通过短语"这很好"与"这不好"在意义上的差异来说明。然而,自然语言中的否定很少会如此简单。否定处理包括两个任务:检测显式的否定词,检测否定词的否定辖域。
Council等人对否定检测是否对情感分析有用,以及达到什么程度的否定检测才可以准确确定文本中否定词的否定范围的问题进行了讨论[7]。他们介绍了一种否定检测方法,该方法通过标记到左右两侧最邻近的显式否定词的距离来实现。
显式否定词检测
为了检测显式的否定词,我们在文本中查找表8中出现的单词。否定词的搜索通过正则表达式进行。
| 搜索顺序 | 否定词 |
| 1. | never |
| 2. | no |
| 3. | nothing |
| 4. | nowhere |
| 5. | noone |
| 6. | none |
| 7. | not |
| 8. | havent |
| 9. | hasnt |
| 10. | hadnt |
| 11. | cant |
| 12. | couldnt |
| 13. | shouldnt |
| 14. | wont |
| 15. | wouldnt |
| 16. | dont |
| 17. | doesnt |
| 18. | didnt |
| 19. | isnt |
| 20. | arent |
| 21. | aint |
| 22. | 任何以"n't"结尾的单词 |
表8:显式的否定词
否定辖域
紧接着在否定词前后出现的单词是最具否定性的,而远离否定词的单词则不在其否定辖域之内。我们定义了左右否定性,表示当前单词取相反含义的可能性。左否定性取决于左侧最近的否定词,右否定性类似。图7给出了一条推文中各单词的左右否定性。

图7:否定辖域
4 实验
我们使用所有数据的90%以及不同的特征组合来训练算法,并在剩余10%的数据上测试效果。我们采用以下方式组合特征
- 仅使用一元词串、一元词串+筛选后的二元词串和三元词串、一元词串+否定检测、一元词串+筛选后的二元词串和三元词串+否定检测。随后,我们使用不同的分类算法训练分类器——朴素贝叶斯分类器和最大熵分类器。
推文的分类任务可分为两步——首先,将推文分类为"中性"(或"客观")推文和"主观"推文,之后,将主观推文分类为"正面"推文和"负面"推文。我们还训练了一个两步分类器。每一种训练配置的准确率如图8所示,接下来我们将详细讨论这些结果。
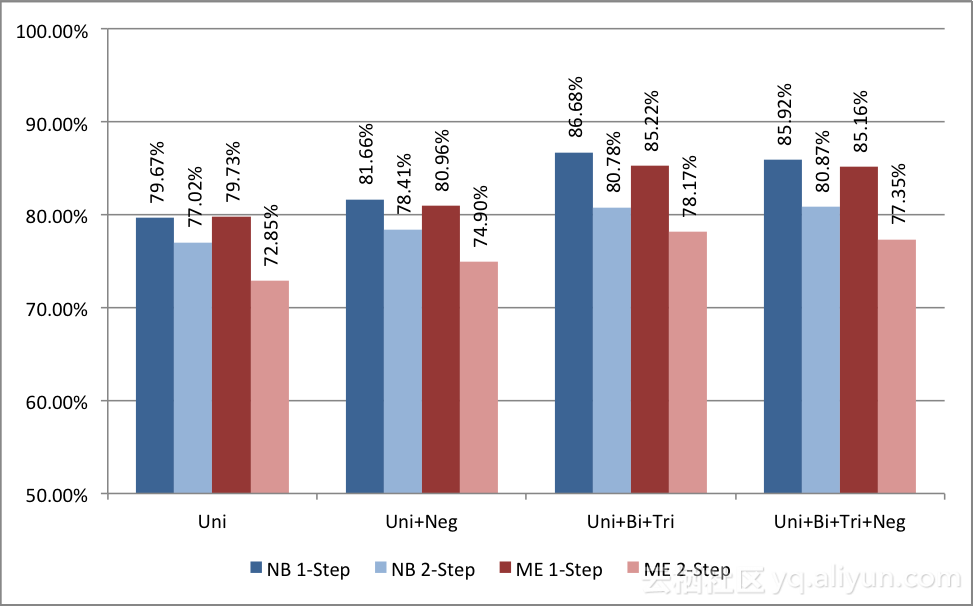
图8:朴素贝叶斯分类器准确率
4.1 朴素贝叶斯
朴素贝叶斯分类器是最简单且速度最快的分类器。许多研究人员[2][4]声称,他们使用这个分类器取得了最好的效果。
对于一条给定的推文,如果我们要找到它的标签,那么我们需要得到所有标签的概率,并根据推文的特征选择概率最大的标签。
使用朴素贝叶斯方法训练的分类器效果如图8所示。基于一元词串的分类器准确率最低,为79.67%。如果我们同时使用否定检测或更高阶的n元词串,准确率会有所提高,分别提高至81.66%和86.68%。我们发现,如果同时使用否定检测和高阶n元词串,准确率略低于仅使用高阶n元词串的结果(85.92%)。我们还可以注意到,两步分类的分类器效果低于对应的单步分类的分类器效果。
在图9中,我们还展示了朴素贝叶斯分类器对不同类别——负面、中性和正面的准确率和查全率。实心标记表示单步分类器的结果,空心标记表示两步分类器的结果。不同的标记对应不同的特征集。我们可以看出,单步分类的准确率和查全率均高于两步分类。
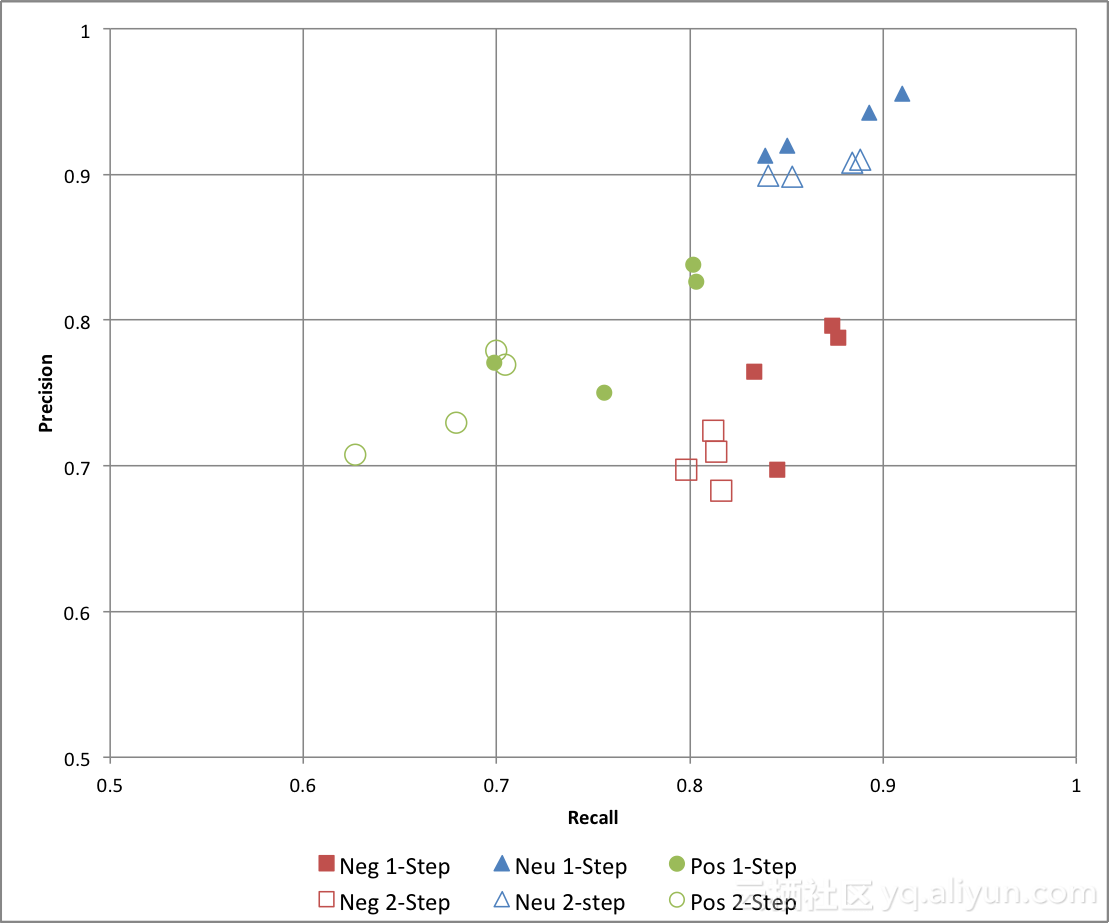
图9:朴素贝叶斯分类器的准确率与查全率
4.2 最大熵分类器
该分类器通过找到最大化测试数据的可能性的概率分布来进行分类。这个概率函数通过权重向量进行参数化。其最优值可使用拉格朗日乘子法找到。
使用最大熵模型训练的分类器效果如图10所示。其分类准确率与朴素贝叶斯分类器相似。基于一元词串的分类器准确率最低,为79.73%,而且,我们可以看到,引入否定检测后,准确率上升至80.96%。基于一元词串、二元词串与三元词串的分类器准确率最高,为85.22%,紧随其后的是使用n元词串与否定检测的方法,准确率为85.16%。再一次地,两步分类器准确率略低一些。
图10展示了最大熵分类器在不同配置下的准确率与查全率。在这里,我们看到,使用两步分类器可以提高"中性"类别的分类准确率,但与此同时,其查全率会大幅降低,"正面"与"负面"类别的准确率也会略微下降。
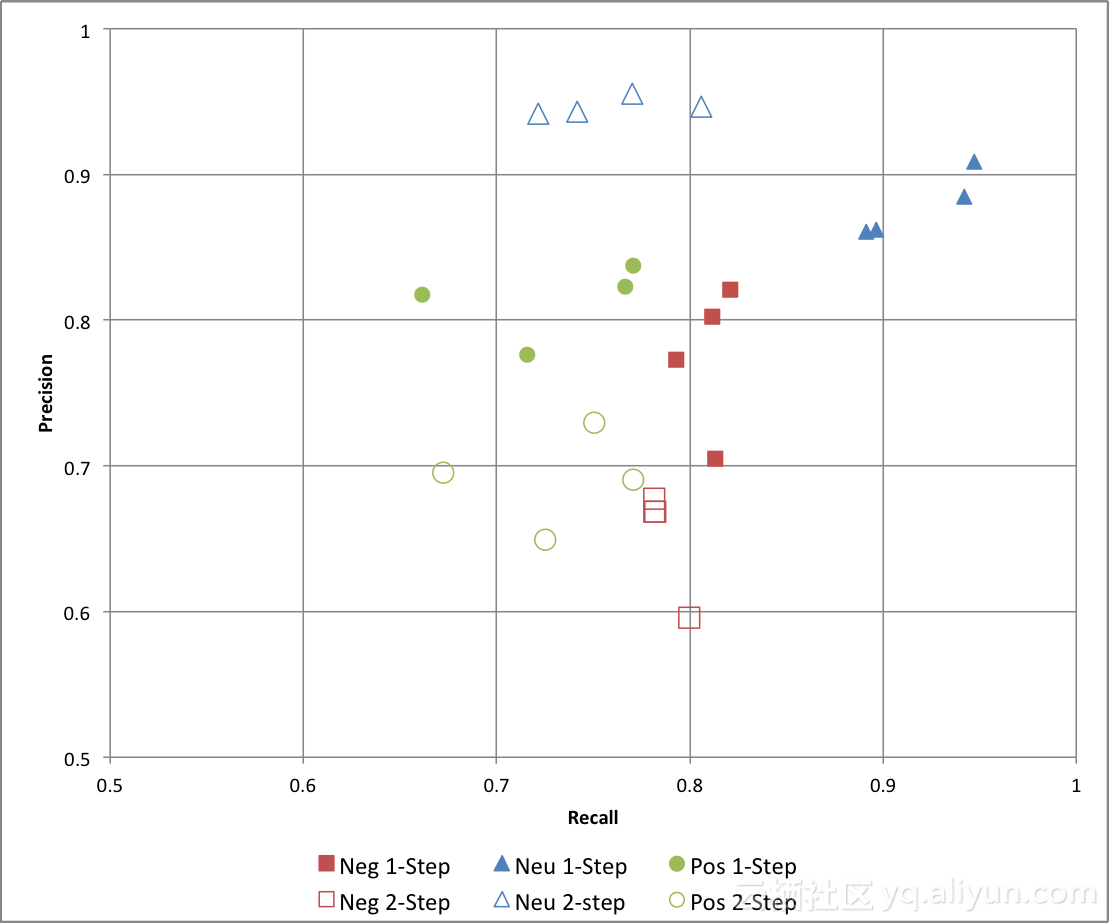
图10:最大熵分类器的准确率与查全率
5 未来展望
研究支持向量机
有几篇论文也讨论了使用支持向量机(SVM)的分类效果。接下来,我们将在支持向量机上测试我们的方法。然而,Go、Bhayani和Huang报告称,支持向量机并不会提高分类准确率[2]。
为印地语推文构造分类器
Twitter上有很多用户主要使用印地语。这里讨论的方法可以用于构建一个印地语情感分类器。
使用语义分析改进结果
了解被谈论的名词所扮演的角色可以帮助我们更好地对推文进行分类。比如说,"Skype经常崩溃:微软,你在搞什么?"。这里的Skype是一个产品,而微软是一家公司。 我们可以使用语义标记器来实现这一点。 Saif、He和Alani [6]介绍了这种方法。
6 结论
我们使用标注数据集,为Twitter构建了一个情感分类器。同时,为了进行情感分析,我们还探讨了使用两步分类器与否定检测间的相关性。
我们的基准分类器仅使用一元词串特征,达到了约80.00%的准确率。如果使用否定检测或引入二元词串和三元词串,准确率会有所增长。因此,我们可以得出结论,否定检测和高阶n元词串都可用于文本分类。然而,如果我们同时使用否定检测和n元词串,准确率会略微下降。我们还注意到,单步分类器相比两步分类器效果更为突出。而且,一般来说,朴素贝叶斯分类器的性能优于最大熵分类器。
以一元词串+二元词串+三元词串为特征并使用朴素贝叶斯分类器进行训练,我们达到了最佳的分类效果,准确率为86.68%。
References
[1] Pak, Alexander, and Patrick Paroubek. "Twitter as a Corpus for Sentiment Analysis and Opinion Mining." LREc. Vol. 10. 2010.
[2] Alec Go, Richa Bhayani, and Lei Huang. Twitter sentiment classification using distant supervision. Processing, pages 1-6, 2009.
[3] Niek Sanders. Twitter sentiment corpus. http://www.sananalytics.com/lab/twitter-sentiment/. Sanders Analytics.
[4] Alexander Pak and Patrick Paroubek. Twitter as a corpus for sentiment analysis and opinion mining. volume 2010, pages 1320-1326, 2010.
[5] Efthymios Kouloumpis, Theresa Wilson, and Johanna Moore. Twitter sentiment analysis: The good the bad and the omg! ICWSM, 11:pages 538-541, 2011.
[6] Hassan Saif, Yulan He, and Harith Alani. Semantic sentiment analysis of twitter. In The Semantic Web-ISWC 2012, pages 508-524. Springer, 2012.
[7] Isaac G Councill, Ryan McDonald, and Leonid Velikovich. What's great and what's not: learning to classify the scope of negation for improved sentiment analysis. In Proceedings of the workshop on negation and speculation in natural language processing, pages 51-59. Association for Computational Linguistics, 2010.
[8] Ilia Smirnov. Overview of stemming algorithms. Mechanical Translation, 2008.
[9] Martin F Porter. An algorithm for suffix stripping. Program: electronic library and information systems, 40(3):pages 211-218, 2006.
[10] Balakrishnan Gokulakrishnan, P Priyanthan, T Ragavan, N Prasath, and A Perera. Opinion mining and sentiment analysis on a twitter data stream. In Advances in ICT for Emerging Regions (ICTer), 2012 International Conference on. IEEE, 2012.
[11] John Ross Quinlan. C4. 5: programs for machine learning, volume 1. Morgan kaufmann, 1993.
[12] Steven Bird, Ewan Klein, and Edward Loper. Natural language processing with Python. " O'Reilly Media, Inc.", 2009.
文章原标题《Sentiment-Analysis-Twitter》,作者:Ayush Pareek,译者:6816816151
文章为简译,更为详细的内容,请查看原文