首先申明
To www.med66.com网站设计师:我只是想批量下载已花钱购买的资源罢了,没有恶意。
12-18
今晚接到老姐的电话,说她已在“医学教育网”订购了不少视频,要我帮她将所有的视频都下载下来。
我看了一下,里面有24门科目,每门科目有40多节。要我手动一个一个下,还不如让我去死。
这种重复的事情还是让程序来做吧!这里开一篇博客直播编写的过程。
被爬网址:http://www.med66.com/
前几天我刚做完一个Qihuiwang的爬虫软件。这次我评估了一下,这次要做的视频下载爬虫程序比上次又有新的挑战:
(1)要处理登陆的过程,上一个不需要登陆就可以直接爬。这次必须要登陆才行。涉及到post数据表的过程
(2)要识别JavaScript程序。我看一下,在我获取网页的那个按钮上写的是 onclick="goDownload('700914', ' ')。这个要转换进行转换成url地址
(3)下载需要记载哪些文件已经下载了,以免每次启动程序都从头开始下载。这是不合理的。
(4)下载的文件要以课程进行目录组织。
网站路径如下:
登陆页面 -(登陆)-> 学员课程页面 -(进入课程)-> 目录页面 -(下载中心)-> 下载页面 --> 小节视频
好,明天开搞,尽情关注!
12-19
今晚加了个班,很累了,况且容忍我好好休息一晚。明日再整!
12-22
周末跟一位做数据挖掘的朋友聊起这事儿。我那朋友说,验证码这事真不好越过。每个网站的验证码都千奇百怪的,现在没有一个统一的识别程序。不过有另一个方法,反正我有帐号密码,那么人工来识别。登陆成功之后,就以登陆后的cookie与网站进行交互。
怎么实现模拟登陆?我查了一下,网上有很多范例:
http://blog.csdn.net/lmh12506/article/details/7818306
http://www.jbxue.com/article/python/22981.html
http://www.oschina.net/code/snippet_16840_2003
12-23
今天研究了一下 www.med66.com这个网站。我用的是firefox浏览器,安装了firebug插件的。
打开该网页,找到登陆模块所对应的网页源码:
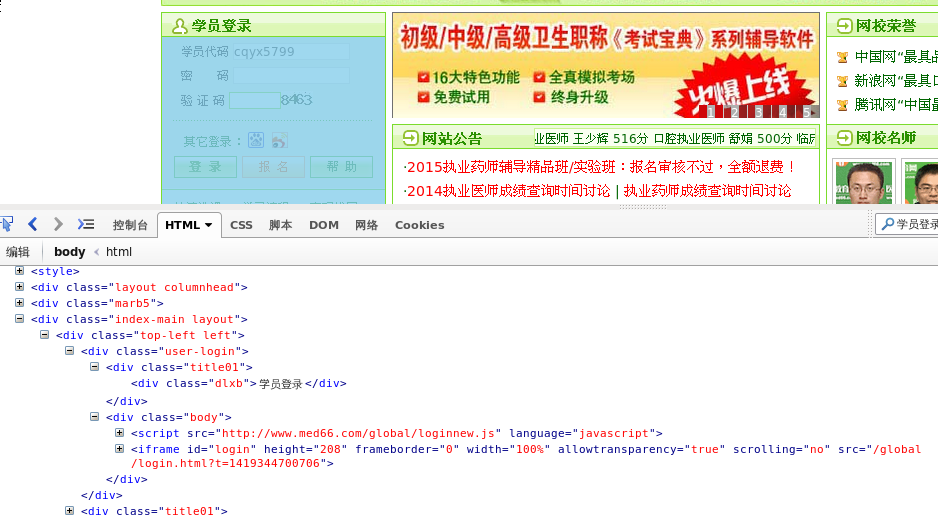
发现 src="/global/login.html?t=1419344700706",除了这个就没有别的了。这说明登陆那边的代码应该是在 /global/login.html 中描述的。
于是,我访问 http://www.med66.com/global/login.html,我们可以看到这就是登陆窗口。

想必这就是所谓的登陆页面了。详细看一下这个表单,它分三个部分:学员代码、密码、验证码。
在验证码那里,还隐藏了不少的隐性表单数据: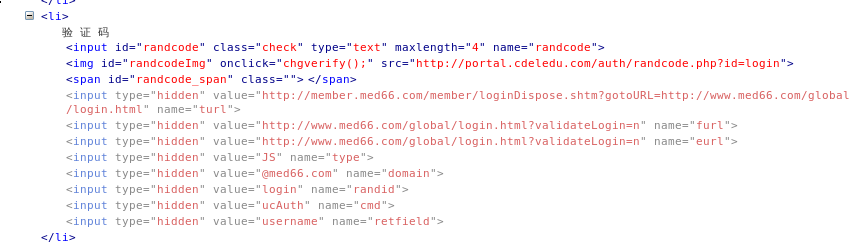
这些数据在提交表单的时候也必须一同提交。
登陆按钮:
12-26
昨天去了趟香港,太累了,休息一晚接着整。网络这方面,我是一个菜鸟,有大鸟漂过,不防指导指导。
上次找到了登陆界面,并得到了源码。我们需要从form中提取出表单。

表单内容:
username=用户名
passwd=密码
randcode=验证码
turl=http://member.med66.com/member/loginDispose.shtm?gotoURL=http://www.med66.com/global/login.html
furl=http://www.med66.com/global/login.html?validateLogin=n
type=JS
domain=@med66.com
randid=login
cmd=ucAuth
retfield=username
发送方式:post,发送到:http://portal.cdeledu.com/auth/index.php
登陆触发:
我查找了“登陆”按钮执行函数"loginSm()"函数,如下为该函数的主体内容:
function loginSm(){
var flag = checkdata();
if(flag == false){
return;
}
var v_username = $.trim($("#username").val());
var v_passwd = $.trim($("#passwd").val());
var v_randcode = $.trim($("#randcode").val());
$("#username").val(v_username);
$("#passwd").val(v_passwd);
$("#randcode").val(v_randcode);
$.getJSON("http://"+portal+"/auth/index.php?cmd=ucAuth&type=JSON&randid=login&username="+v_username+"&passwd="+v_passwd+"&domain=@med66.com&randcode="+v_randcode+"&jsonpCallback=?",
function(json){
var code = json.code;
var sid = json.sid;
if(code == 0){
document.getElementById("passwd_span").className="r";
document.getElementById("username_span").className="r";
document.getElementById("randcode_span").className="r";
$("#submit_code").val(code);
$("#submit_sid").val(sid);
$("#submit_form").submit();
}else{
chgverify();
document.getElementById("username_span").className="w";
document.getElementById("passwd_span").className="w";
document.getElementById("randcode_span").className="";
document.getElementById("username").focus();
document.getElementById("randcode").value="";
}
});
}我不会javascript,但看到上面的代码也能猜到点意思:
(1)从网页中获取"username", "passwd", "randcode"的值,并去除前后空格后赋值给javascript变量v_username, v_passwd, v_randcode。
var v_username = $.trim($("#username").val());
var v_passwd = $.trim($("#passwd").val());
var v_randcode = $.trim($("#randcode").val());
$("#username").val(v_username);
$("#passwd").val(v_passwd);
$("#randcode").val(v_randcode);(2)用.getJSON()函数访问网址,得到json数据。这个网址是由变量拼接出来的。
$.getJSON("http://"+portal+"/auth/index.php?cmd=ucAuth& ... &jsonpCallback=?", function(json){ ... } )
那么问题来了:portal的值是多少?

上面的代码,先得到流览器的类型到ua,
如果是safari浏览器,那么portal="portal.med66.com",并修改autoSubmitForm与login_form表单的action属性为"http://portal.cdeledu.com/auto/index.php"
我的浏览器不是safari,那么portal就应该是:portal.cdeledu.com
如果用户名为:cqy,密码为:123,验证码为:4996,那么要访问的网址为:
http://portal.cdeledu.com/auth/index.php?cmd=ucAuth&type=JSON&randid=login&username=cqy&passwd=123&domain=@med66.com&randcode=4996&jsonpCallback=?
我在浏览器的地址栏输入上述地址,进入。得到的返回是:
说是验证码不对。我这个验证码是从另一个页面得到了。
是不是必须得在验证码作在同一个页面提交才行?我试一下在刚刚验证码作在的页面进行访问上述网址。
果然是这样的。大家看,返回的code为0,说明成功了。而且还有sid数据。
这是为啥呢?难不成,在提交的时候,不同的页面还有一个id码?
于是我想研究一下验证码,看到网页:http://www.cnd8.com/news/news/13778.htm
说验证码都是存放在cookie里面的。于是我打开 http://www.med66.com/global/login.html 并复制一个同样的页面。这两个页网除了验证码不一样,其它都一样。然后我打开firebug,查看它们之间的cookie的差别。我反复比较,没有发现有任何的区别。得出的结论那就是验证码相关的信息并没有存放在cookie里。
那除了cookie外,那就是别的什么识别码了。
后来经反复验证,原来是之前我网址写错了或是验证码失效了。其实没有限制,只要是用firefox打开的登陆界面,但用firefox去访问那个网址,都能成功,不管是不是同个页面,或同个窗口。同一种浏览器是可以的,但不同的不行。比如说:我从firefox上得到的验证码,把网址放在konqueror中去访问,就会报验证码错误。反之在firefox上去访问就OK。konqueror得验证码,firefox访问也不行。(好像是cookie引起的问题)
既然这样,那就没什么大的问题。
(3)将json数据交给最后的回调函数进行分析处理。
var code = json.code;
var sid = json.sid;
if(code == 0){
document.getElementById("passwd_span").className="r";
document.getElementById("username_span").className="r";
document.getElementById("randcode_span").className="r";
$("#submit_code").val(code);
$("#submit_sid").val(sid);
$("#submit_form").submit();如果成功,json.code应该为0。然后将code, sid填写到网页的submit_code, 与submit_sid元素的value中去。并触发表单的提交事件。

如上就是第二次要提交的表单,看起来非常简单。用python很好模拟的。
好家伙!原来提交过程还要与网站进行了次交互才行。
12-29
验证码是怎么得到了?
每次访问 http://portal.cdeledu.com/auth/randcode.php?id=login 都能得到一个新的码证码图片。而这个验证码可以用来获取json上面数据的(这个我验证过)。可以通过wget获取这个图片。
好,既然了解得差不多了。下面我们就来用python开始模拟这个登陆过程。
import urllib
import urllib2
import cookielib#登陆网站,并返回登陆后的页面
def login():
username = 'hevake'
password = 'abc123'
#配置opener,要使用到cookie
install_opener()
#获取验证码图片,展示并让用户输入验证码
randcode = get_randcode()
if randcode != None:
#获取json数据,提取code, sid
json_data = get_json(username, password, randcode)
if json_data != None:
if json_data['code'] == '0':
#用code, sid提交submit_form表单,返回登陆后的页面
page = submit_form(json_data['code'], json_data['sid'])
print('登陆成功')
return page
else:
print(json_data['msg'])
else:
print('获取json失败')
else:
print('获取验证码失败')
pass
if __name__ == '__main__':
page = login()
if page != None:
f = open('login.html', 'w')
f.write(page)
f.close()不多解释,上面只是粗略的登陆步骤,每步还需要实现。
第一步:install_opener()
由于登陆需要用到cookie,所以要使用带cookie的opener,如下为 install_opener()函数的实现:
#配置urllib2的opener
def install_opener():
cj = cookielib.CookieJar()
processor = urllib2.HTTPCookieProcessor(cj)
opener = urllib2.build_opener(processor)
urllib2.install_opener(opener)
pass配置了opener之后,后面用urllib2.urlopen()就是用的新设置的opener进行操作了。
相关文章:urllib2,cookielib
第二步:get_randcode()
前面提到了,获取验证码其实就是访问网址 http://portal.cdeledu.com/auth/randcode.php?id=login,那么现在要做的是用python从这个url上获取图片,并展示出来。
相关的文章:python批量下载图片,python下载网页图片
今天太晚了,明日接着搞!
2015 1-3
获取验证码流程大概如下:
def get_randcode():
#TODO
# 获取随机验证码
# http://portal.cdeledu.com/auth/randcode.php?id=login
# 将验证码展现出来,让用户输入
randcode = raw_input('请输入验证码:')
return randcode
pass本人现在还不知道怎么让计算机自动识别验证码,那就人工输入吧!反正又不是抢火车票。
用一个专门的函数专门用于下载验证码图片:
def get_randcode_jpeg():
randcode_url = 'http://portal.cdeledu.com/auth/randcode.php?id=login'
respond = urllib2.urlopen(randcode)
return respond.read()
pass这个函数的功能就是访问验证码的url,获取图片。
然后,该怎么显示出来呢?
(1)保存到本地图片文件,然后调用系统应用打开。
(2)用什么别的图形组件打开。
python的GUI界面,我知道的有PyQt4, Tkinter。PyQt4功能是强大,但是安装很糟心!Tkinter相对比较简单。那就选用Tkinter吧。
验证码的文件是jpeg,而Tkinter显不出来,而网上相关的资源不多。那还是用别的看看,wxPython。
算了,蛮拆腾的,就为了显示个图片还得去学wxPython,Tkinter。还是采用方案(2)吧!查了一下,centos的图片浏览器命令是 eog,那就用它算了。
def show_randcode_jpeg():
jpeg_context = get_randcode_jpeg()
jpeg_file = 'randcode.jpeg'
f = open(jpeg_file, 'w')
f.write(jpeg_context)
f.close()
os.system('eog "%s"' % jpeg_file)上面这个函数能用图片浏览器达到显示验证码的效果。就这样吧!以后有时间再研究wxPython。
那么对于的 get_randcode() 函数要写成这样:
def get_randcode():
#TODO
# 获取随机验证码
# http://portal.cdeledu.com/auth/randcode.php?id=login
# 将验证码展现出来,让用户输入
show_randcode_jpeg()
randcode = raw_input('请输入验证码:')
return randcode
pass好了!现在验证码有了。下一步就是:get_json()
第三步:get_json()
上面,我们研究过,get_json()这个过程其实是合成一个url,并从这个url获取json数据。
#合成网址,获取json数据并提取sid码
def get_json(username, password, randcode):
url_template = 'http://portal.cdeledu.com/auth/index.php?cmd=ucAuth&type=JSON&randid=login&username=%s&passwd=%s&domain=@med66.com&randcode=%s&jsonpCallback=?'
#合成完整的url
url_full = url_template % (username, password, randcode)
respond = urllib2.urlopen(url_full)
context = respond.read()
print(context[2:-1])
json_data = json.loads(context)
code = json_data.code
sid = json_data.sid
return code, sid上面的代码能够成功获取json数据,并能成功获得sid码。但是在用json提取数据的时候出错。
查得原因是 python json 库不支持json中的key没有双引号括起的情况。如:{aa:123},必须得是:{"aa":123}。还有,python json不能处理单引号。
解决办法之一就是用正则式re中的sub进行替换。
>>> print ss
{code:'0',sid:'vfuuf6emf80gpoet52k23pigm6'}
>>> sd = regex.sub(r'(\w+):', r'"\1":', ss)
>>> print sd
{"code":'0',"sid":'vfuuf6emf80gpoet52k23pigm6'}那再修改一下 get_json() 函数:
def parser_json(json_context):
#给json的key加双引号,不然python json解释会报错
json_context = re.sub(r'(\w+):', r'"\1":', json_context)
#将单引号转换成双引号
json_context = re.sub(r"\'", r'"', json_context)
json_data = json.loads(json_context)
return json_data
#合成网址,获取json数据并提取sid码
def get_json(username, password, randcode):
url_template = 'http://portal.cdeledu.com/auth/index.php?cmd=ucAuth&type=JSON&randid=login&username=%s&passwd=%s&domain=@med66.com&randcode=%s&jsonpCallback=?'
#合成完整的url
url_full = url_template % (username, password, randcode)
respond = urllib2.urlopen(url_full)
context = respond.read()[2:-1] #去除开头的?(与后面的)
json_data = parser_json(context)
return json_data好了,通过多次调试,通过了登陆这个过程。
第四步:提交 submit_form表单
前面研究了,submit_form表单的提交就是:
将 code, sid 数据 POST 到 http://member.med66.com/member/loginDispose.shtm
关于表单的提交网上有太多博文了,如: http://developer.51cto.com/art/201003/186364.htm
OK,let us go !
#提交submit_form表单到 http://member.med66.com/member/loginDispose.shtm
def submit_form(code, sid):
url = 'http://member.med66.com/member/loginDispose.shtm'
url_data = urllib.urlencode({'code':code, 'sid':sid})
print(url_data)
request = urllib2.Request(url, data=url_data)
respond = urllib2.urlopen(request)
page = respond.read()
return page第五步:测试
上面,我们将各个步骤都一一实现了。现在我们来验证一下是否成功登陆。测试结果是将最后提交 submit_form 得到的页面保存在 login.html 文件中。
我们用firefox打开这个文件:

这说明,登陆已经成功了!
完整的代码已提交到 osc 代码库了:http://git.oschina.net/hevake_lcj/Med66VideoDownloader