1.5 Flume事件
Flume传输的基本的数据负载叫作事件。事件由0个或多个头与体组成。
头是一些键值对,可用于路由判定或是承载其他的结构化信息(比如说事件的时间戳或是发出事件的服务器主机名)。你可以将其看作是与HTTP头完成相同的功能——传递与体不同的额外信息的方式。
体是个字节数组,包含了实际的负载。如果输入由日志文件组成,那么该数组就非常类似于包含了单行文本的UTF-8编码的字符串。
Flume可能会自动添加头(比如,源添加了数据来自的主机名或是创建了事件时间戳),不过体基本上是不受影响的,除非你在中途使用拦截器对其进行了编辑。
1.5.1 拦截器、通道选择器与选择处理器
拦截器指的是数据流中的一个点,你可以在这里检查和修改Flume事件。你可以在源创建事件后或是接收器发送事件前链接0个或多个拦截器。如果熟悉AOP Spring框架,那么它非常类似于MethodInterceptor。在Java Servlets中,它类似于ServletFilter。在一个源上链接了4个拦截器,如下图所示。
通道选择器负责将数据从一个源转向一个或多个通道上。Flume自带了两个通道选择器,这涵盖了你可能会遇到的大多数场景。不过如果需要你也可以编写自己的选择器。复制通道选择器(默认的)只是将事件的副本放到每个通道中,前提是你已经配置好了多个通道。相反,多路通道选择器会根据某些头信息将事件写到不同的通道中。搭配上拦截器逻辑,这两种选择器构成了将输入路由到不同通道的基础。
最后,输入处理器指的是这样一种机制,你可以通过它为输入器创建故障恢复路径,或是跨越一个通道的多个输入器创建负载均衡事件。
1.5.2 分层数据收集(多数据流与代理)
你可以根据特定的需求链接Flume代理。比如,你可以以分层的方式插入代理来限制想要直接连接到Hadoop的客户端数量。很多时候,源机器没有足够的磁盘空间来处理长期停机或是维护窗口,这样就可以在源与Hadoop集群之间创建一个拥有大量磁盘空间的层次。
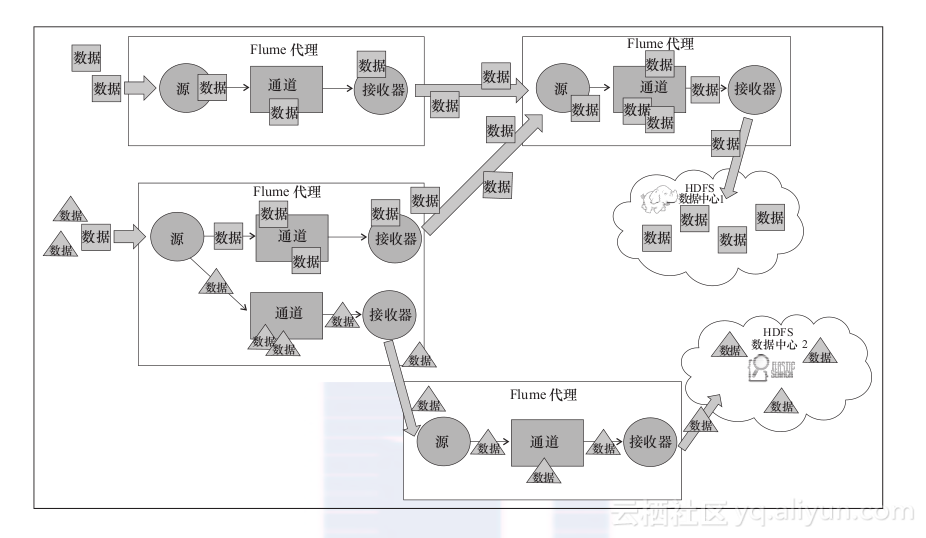
从下图中可以看到,数据在两个地方被创建(位于左侧),并且有两个最终目的地(位于右侧的HDFS与ElasticSearch云气泡)。下面增加点儿趣味性,假设有一台机器生成了两种数据(我们将其称作正方形数据与三角形数据)。我们在左下角的代理中使用了多路通道选择器将这两种数据划分到了不同的通道中。接下来,矩形通道被路由到了右上角的代理(以及来自于左上角的数据)。合并后的总数据被一同写到了数据中心1的HDFS中。与此同时,三角形数据被发送到了代理,该代理将其写到数据中心2的ElasticSearch中。请记住,数据转换可能发生在任何源之后以及任何接收器之前。随后将会介绍如何通过这些组件构建复杂的数据流。