
下面我来介绍一下深度学习在自然语言处理(NLP)的最新进展。我主要想针对机器翻译、聊天机器人和阅读理解这三个最活跃的方向来探讨深度学习在NLP领域的发展到了什么水平,还存在什么问题,然后再引申出未来的研究方向。
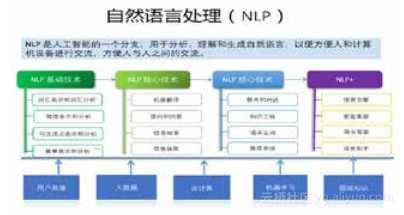
上图是自然语言处理主要技术的一览图。从左开始,第一列是自然语言的基本技术,包括词汇级、短语级、句子级和篇章级的表示,比如词的多维向量表示(word embedding)、句子的多维向量表示,还有就是分词、词性标记、句法分析和篇章分析。第二列和第三列是自然语言的核心技术,包括机器翻译、提问和问答、信息检索、信息抽取、聊天和对话、知识工程、自然语言生成和推荐系统等。最后一列是NLP+,就是NLP的应用,比如搜索引擎、智能客服、商业智能、语音助手等;也包括在很多垂直领域,比如银行、金融、交通、教育、医疗的应用(这里没有画出)。NLP技术及其应用是在相关技术或者大数据支持下进行的。用户画像、大数据、云计算平台、机器学习、深度学习,以及知识图谱等构成了NLP的支撑技术和平台。
自然语言处理开展很早,计算机刚刚发明之后,人们就开始了自然语言处理的研究。机器翻译是其中最早进行的NLP研究。那时的NLP研究都是基于规则的,或者基于专家知识的。在1990年之后,NLP技术的主流是统计自然语言处理。机器翻译、搜索引擎等都是采用统计自然语言处理技术来做的。而从2008年到现在,在不到十年的时间,在图像识别和语音识别领域的成果激励下,人们也逐渐开始引入深度学习来做NLP研究,并在机器翻译、问答系统、阅读理解等领域取得一定成功。深度学习是一个多层的神经网络,从输入层开始经过逐层非线性的变化得到输出。从输入到输出做端到端的训练。把输入-输出对的数据准备好,设计并训练一个神经网络,即可执行预想的任务。现在来看,深度学习之于NLP有两个重要进展,一个是表征词汇的语义的word embedding;另外一个就是用CNN计算句子的相似度,以及用RNN(包括LSTM和GRU)来做句子的编码和解码。
深度学习在NLP很多领域都取得了一些进展,比如机器翻译、问答系统、聊天机器人、阅读理解等。不过也面临很多挑战。具体来讲,就是如何跟知识学习有效地把知识,包括语言学知识、领域知识用起来;如何跟环境学习通过强化学习的方式提升系统的性能;如何跟上下文学习——利用上下文进一步增强对当前句子的处理能力;以及如何利用用户画像体现个性化的结果。
下面先介绍神经网络机器翻译(NMT)的进展。NMT就是编码和解码的过程。具体来讲,一个句子首先经过一个LSTM实现编码,得到N个隐状态序列。每一个隐状态代表从句首到当前词汇为止的信息的编码。句子最后的隐含状态可以看作是全句信息的编码。然后再通过一个LSTM进行解码。逐词进行解码。在某一个时刻,有三个信息起作用决定当前的隐状,即源语言句子的信息编码、上一个时刻目标语言的隐状态,以及上一个时刻的输出词汇。然后再用得到的隐状态通过Softmax计算目标语言词表中每一个词汇的输出概率。这个解码过程要通过一个Beam Search得到一个最优的输出序列,即目标语言的句子。后来进一步发展了注意力模型,通过计算上一个隐状态和源语言句子的隐状态的相似度来对源语言的隐状态加权,体现源语言句子编码的每一个隐状态的对解码的作用。
神经网络机器翻译最近三年里取得了很好的进展。这是我们的一个实验结果,可以看出NMT与经典的SMT相比,BLEU 值至少提升了4个点(BLEU是衡量机器翻译结果的一个常用指标)。这是一个很大的进步。要知道统计机器翻译在过去5年里都没有这么大的提升。NMT已被公认为机器翻译的主流技术,许多公司都已经大规模采用NMT作为上线的系统。
最近也有学者在考虑把一些知识加入到系统中。比如在源语言编码时考虑源语言的句法树(词汇之间的句法关系),或者在解码时考虑目标语言的句法树的信息。通过句法树来加强对目标语的词汇的预测能力。我们也在做一个工作,用领域知识图谱来强化编码和解码,得到了很好的结果。
但是NMT仍然存在很多挑战。首先,如何把单语语料用起来还没有一个定论。现在简单的做法是把通过一个翻译系统翻译单语语料所得到的双语对照的语料,以加权的形式加入到训练语料中。尽管这种反向翻译单语数据来获得更多双语数据,或者使用对偶学习的方法利用单语数据在一些数据集上有了一定的改进,然而如何使用单语数据改进NMT的性能还有很大的探索空间。第二,以前在统计机器翻译中语言模型作为重要的特征对翻译质量有重要作用,可是在NMT中语言模型到底怎么用才好,还有待深入探索。第三,OOV的问题,也没有解决的特别好。第四,如何融入语言知识和翻译知识。假设已经有一系列人工总结的语言词法分析、句法分析,以及两种语言之间的转换规则,如何把它融入到NMT中,还值得好好的探讨。最后,目前的翻译都是句子级进行翻译的,在翻译第N句时,没有考虑前N-1句的源语言和翻译的信息。比如“中巴友谊”,到底是中国-巴西,还是中国-巴基斯坦?如何利用上下文来推断翻译?这些都是很好的研究课题。
我要介绍的第二个工作是聊天机器人。为什么要做聊天机器人?因为它在人机对话中非常重要。比如说我们到一个小卖部买东西,开始要闲聊几句,然后表示购买的意图,然后通过一些对话和问答,最后完成交易。这里面有三个重要技术,一个是闲聊,它拉近人与人之间的关系;第二是获得信息,主要是通过搜索引擎或者通过QA系统来完成的;最后就是关于某一个特定任务的对话系统。今天由于时间限制,仅讲一讲聊天机器人目前的进展,以及遇到了哪些挑战。
聊天机器人需要根据用户的输入信息(Message),输出与其语义相关的回复(Response)。目前有基于检索的技术和基于生成的技术可以采用,各有千秋。无论哪种技术,都需要事先获取大量的Message-Response对,用来作为聊天知识用于检索,或者用于训练一个生成Response的模型。
基于检索的技术是针对一个Message,首先检索与Message相似的Message,则其对应的Response可以作为输出的候选。由于经常会有多个匹配的Message-Response对,则需要选择一个最优的Response作为最终的输出。因此需要计算输入Message和可能的Response的语义相关度。第一种算法,通过词的embedding,通过卷积或者LSTM可以得到句子级的embedding表示,然后再计算Message和Response句子embedding的相似度。
第二种算法是计算Message-Response的每一个词对的相关度得到一个相关度矩阵,再通过多次卷积、Pooling,最后经过多层感知机来计算相关度。由于Message有时是短文本,太干巴了,没有多少信息,所以会影响检索的结果。研究人员把与短文本相关的知识、主题词加进去来强化Message或者Response候选,然后再计算相关度,提升了Response的质量。第二种方法是用一种生成模型来得到回复。经典的方法可以是用AIML语言人工描写Message-Response对,或者通过统计机器翻译来做Message到Response的映射。现在神经网络LSTM编码-解码方法成为主流。如果把Message看作源语言句子,把Response看作目标语言句子,通过NMT方法就可以从Message翻译到Response。同样,跟检索式系统一样,也可通过外部知识或者主题词信息来增强。
多轮对话需考虑到以前的对话信息,在回复时 要用到前面若干个句子的信息。关于上下文建模目前并没有太好的方法。现在用word embedding或者LSTM表示前面每一个句子。在基于检索的方法中,计算候选的Response与以前若干句子的每一个句子计算一个相似度,最后通过一个多层感知机来算上下文与候选Response的匹配程度。在用基于生成的方法时,需对前面若干已出现的句子和词汇都进行建模。在预测输出句子中某一个词时,要用以前的所有词计算一个注意力,也要用所有句子计算一个注意力。所以,一个词汇的输出是词汇和句子两层注意力模型共同起作用的结果。
聊天系统存在很多问题。首先多轮对话的上下文建模目前采用的方法还比较粗糙,而且尚没有一个针对多轮聊天的有效的自动评测方法。由于需要人去看回复质量,导致评价的代价比较大。第二,如何计算Message的情感并生成与之对应的特定情感的句子,值得仔细研究。第三,记忆机制,需跟踪对话主题的变化,抽取重要的信息,及时侦测信息的变化。基于记忆机制的对话模型也需要进一步深化。最后,实现个性化的聊天,建立用户画像然后生成用户所关心的内容,并体现他所喜欢的风格。针对同一个内容,生成不同风格的回复也是一个有趣的研究问题。
最后再跟大家介绍一下现在热门的阅读理解。所谓阅读理解,就是给电脑一篇文章,让电脑来回答一些问题。阅读理解的难度是不一样的,有的阅读理解问题,其答案在文章之中,需要从文章中把答案抽取出来;有的阅读理解,答案并不一定出现在文章中,需要进行一些推理才能得到答案。斯坦福大学做了一个阅读理解测试题并于2016年9月上线。它提供了一定规模的训练集、开发集和测试集。该任务的答案基本都在文中出现过,需要找出答案候选,然后经排序输出一个最好的答案。参赛队伍把用训练集所训练的系统提交给斯坦福大学后,由它来运行你的系统,然后在其网站上发表测试结果。提交的结果包含单系统和多系统融合的结果。我们的工作比较幸运,无论是单系统还是多系统,都一直位居所有参赛队伍的第一名。我们的系统融合的结果目前能做到76左右,而斯坦福大学雇人做题的正确率可达81%,可见针对这个阅读理解任务,电脑和人还有5分的不小差距。
下面简单介绍我们用的方法,首先,第一层网络对文章和问题通过双向LSTM来建模;然后计算文章的每一个词和问题的每一个词的相关度。在此基础上,由第二层网络找出可能是答案的词汇;然后再经过一个Self-Matching网络把所有可能的候选排序;最后经过一个叫做Pointer的网络,推断出最有可能的答案候选的边界。
这样的技术未来有什么用?我觉得可以在问答系统、检索系统、智能客服、自动答题和阅卷都可以得到很好的应用。比如很多产品网页纷繁复杂,用户要把网页从头到尾看一遍才能找到答案。假如说有阅读理解的能力,电脑扫描这个网页,对一个问题,电脑直接定位网页中答案的位置。我们的基于阅读理解的客服机器人的工作将在ACL2017展示。
与神经机器翻译、聊天机器人一样,阅读理解也存在很多挑战。我们现在做的是比较简单的阅读理解,从文档中抽取答案就能解决大部分问题。然而更多情况下,是需要基于上下文的推理甚至基于常识的推理才可以得到答案的。这确实是一件很困难的事情。要推动这件事的发展,就得跟无人驾驶汽车分级测试一样需要设定问题的难度,逐级增加难度,对每一个级别建立训练和评测集合。然后进行逐级开发、逐级评测。最近微软发布了一个新的评测任务MARCO,就是在这个方面的一个尝试。
最后总结一下,自然语言过去60年的发展,从基于规则方法到基于统计方法,再到最近几年的基于深度学习的方法,技术越来越成熟了,而且很多领域都取得了巨大的进步。展望未来5~10年,随着深度神经网络技术、大数据还有云计算这三个主要因素的推动,自然语言处理必将越来越实用。首先,我认为手机语音翻译一定会普及,就跟打电话一样,拿起电话来说话,从中文翻译成英文,或者翻译成日文、法文,在常见的场景下基本可达实用。虽然手机语音翻译会实用化,但我认为同声翻译和专业领域的翻译由于难度更大尚不能彻底解决,需要更多的时间。第二,自然语言的会话技术(包括聊天、问答),会在单轮精度和多轮建模上进一步突破,并广泛地应用在重要的领域(包括智能家居和语音助手等)。第三,智能客服系统。我认为其中许多重复的工作,特别是单轮可以解决的工作,以及可明确定义对话状态的多轮交互,将被智能客服所取代。然而在需要多轮自由对话的场景,我们还是不能过高地估计自然语言对话系统的能力。但是智能客服加上人工客服完美的结合,将使客服的效率大幅度提高。第四,自然语言生成的各项任务,诸如写诗、写小说、写新闻稿件等在未来5~10年会得到实际应用。最后,自然语言技术配合其他AI的技术比如感知智能的技术,在教育、医疗、银行、法律、投融资、无人驾驶等垂直领域,会起到实实在在的应用。
虽然我们认为,NLP在未来5~10年将会有大的发展,但还需要清醒地看到,未来还是充满许多挑战,值得深入探讨。第一,现在深度学习都是端到端进行训练,而中间哪个环节起作用?哪个词起作用?哪个句型起作用?不是非常清晰。我们希望有一个可以解释的人工智能,展示所有的推理过程,告诉我是怎么做出来的;做不对的话,告诉我问题可能出在哪里。第二,现在大家都一窝蜂地使用深度学习来做几乎一切任务,但是我们也应该看到在很多任务上,知识(包括词典、规则、知识图谱)等是需要好好地利用起来的,否则仅凭深度学习面临很多局限性。而如何通过深度学习来无缝对接知识与数据,使两者巧妙融合,优势互补,还需要长期的探讨。第三,在面对某些任务或者一个新领域时,标注数据很少,这时如何起步?如何利用无标注数据(通过无监督学习)、领域知识(通过融合知识),或者其他领域的成熟系统(通过迁移学习)来提高学习效果,快速起步?第四,如何捕捉用户和环境的反馈信号利用强化学习不断提高系统。最后,如何融合用户画像体现个性化的服务。
(本报告根据速记整理)