1.2 波动率建模
金融时间序列的波动率会随着时间变化,这在实证金融中已经是广为熟悉和被接受的典型事实。但是,波动率的不可测性使得测量和预测它成为一项挑战性任务。通常,以下3种经验观察推动了波动率模型的演变。
波动性聚集:它指金融市场上的这样一种经验观察,平静期常常跟着平静期,而波动期常常跟着波动期。
资产收益率的非正态性:实证分析显示,相对于正态分布,资产收益率分布趋向于厚尾性。
杠杆效应:这会导致一种现象,波动率对正价格变动或负价格运动的反应往往不同。价格下降时波动率的增加幅度大于相似规模的价格上涨带来的波动率变动。
在下列代码中,我们演示了基于S&P资产价格的典型化事实。用我们已掌握的方法,从雅虎财经下载数据:
getSymbols("SNP", from="2004-01-01", to=Sys.Date())
chartSeries(Cl(SNP))
我们的兴趣目标是日收益率序列,因此从收盘价计算对数收益率。其实quantmod包提供了一种更简单的方法,收益率可以直接计算:
ret <- dailyReturn(Cl(SNP), type='log')
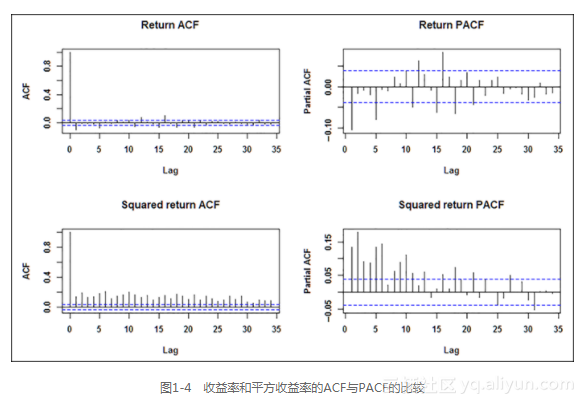
波动率分析始于观察自相关和偏自相关函数。我们希望对数收益率序列无关,但对数收益率的平方值或者绝对值都显示出了显著的自相关性。这意味着对数收益既不相关,也不独立。
注意下列代码中的par(mfrow=c(2,2))函数。通过它,可以重写R中默认的图形参数,把4张图形组织成方便的表格形式:
par(mfrow=c(2,2))
acf(ret, main="Return ACF");
pacf(ret, main="Return PACF");
acf(ret^2, main="Squared return ACF");
pacf(ret^2, main="Squared return PACF")
par(mfrow=c(1,1))
上述代码输出如图1-4所示。
接下来,我们来看S&P的日度对数收益率的直方图和(或)经验分布,并与同均值同标准差的正态分布进行比较。我们使用函数density(ret)计算正态分布的非参数经验分布函数。再使用带有附加参数add=TRUE的函数curve()在刚刚画好的图形上绘出第二条线,如图1-5所示。
m=mean(ret);s=sd(ret);
par(mfrow=c(1,2))
hist(ret, nclass=40, freq=FALSE, main='Return histogram');curve(dnorm(x,
mean=m,sd=s), from = -0.3, to = 0.2, add=TRUE, col="red")
plot(density(ret), main='Return empirical distribution');curve(dnorm(x,
mean=m,sd=s), from = -0.3, to = 0.2, add=TRUE, col="red")
par(mfrow=c(1,1))
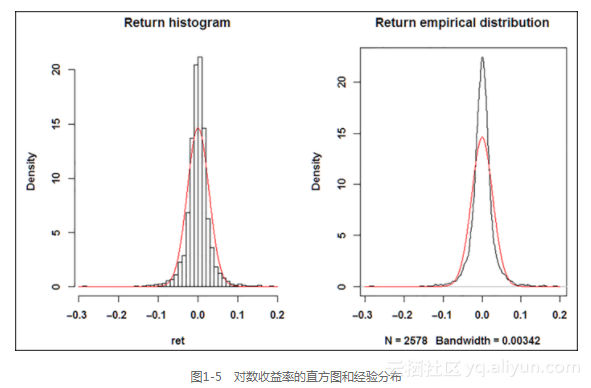
很明显可以看出尖峰厚尾性。但我们还得在数值上确认(使用moments包)样本经验分布的峰度超过正态分布的峰度(等于3)。和其他的软件包不同,R报告名义峰度,而非超额峰度,结果如下:
> kurtosis(ret)
daily.returns
12.64 959
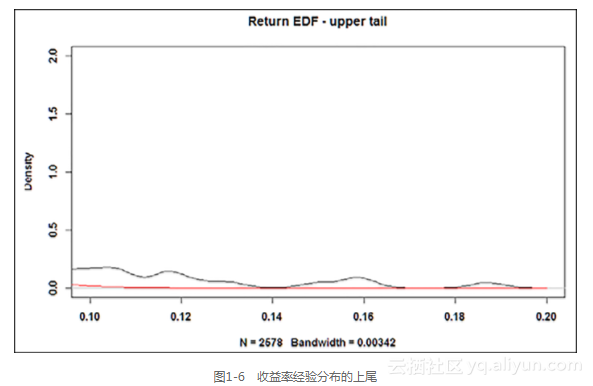
放大图形的上尾和下尾可能有用,仅改变图形比例就可以,效果如图1-6所示。
# 放大尾部
plot(density(ret), main='Return EDF - upper tail', xlim = c(0.1, 0.2),
ylim=c(0,2));
curve(dnorm(x, mean=m,sd=s), from = -0.3, to = 0.2, add=TRUE, col="red")
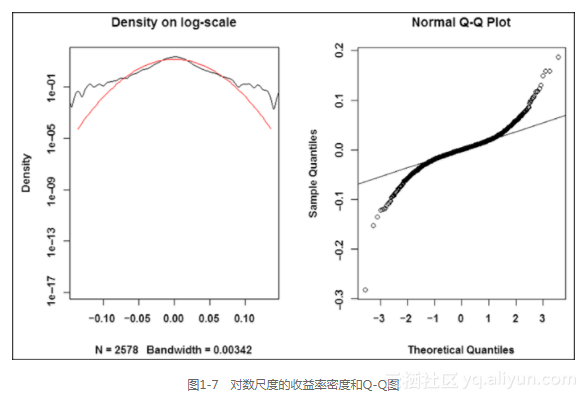
另一种有用的可视化练习是观看对数尺度上的密度(图1-7的左侧部分)或者Q-Q图(图1-7的右侧部分),它们是密度比较的常用工具。Q-Q图描绘了经验分位数对理论(正态)分布的图形。如果样本取自正态分布,它应该绘出一条直线。对这条直线的偏离表示存在厚尾性:
# 对数尺度上的密度图
plot(density(ret), xlim=c(-5s,5s),log='y', main='Density on log-scale')
curve(dnorm(x, mean=m,sd=s), from=-5s, to=5s, log="y", add=TRUE,
col="red")
# QQ-plot
qqnorm(ret);qqline(ret);
上述代码的输出如图1-7所示。
现在,我们可以把注意力转向波动率建模。
广义地说,金融计量经济学文献中有两类建模技术可以捕捉波动率的变化本质:GARCH族方法[Engle(1982);Bollerslev(1986)]和随机波动模型(Stochastic Volatility,SV)。GARCH类模型和(纯粹的)SV类建模技术的主要区别在于,给定历史观测后,前者的条件方差是可以找到,而在SV模型中,考虑所有可得信息后,波动率依然无法预测。因此,SV模型的波动率本质上是隐性的,必须由测量方程滤出[比如,见Andersen–Benzoni(2011)]。换句话说,GARCH类模型意味着,可以通过历史观测值估计波动率,而在SV模型中,波动率自身有隐性的随机过程,因此推断潜在的波动率过程需要已实现收益率作为观测方程。
在本章中,基于两种原因我们介绍GARCH方法的基本建模技术。首先,它在应用工作中有更广泛的使用。其次,由于方法背景上的多样性,SV模型还不能被R包本地支持,而经验分析的使用需要大量的定制。
1.2.1 通过rugarch包进行GARCH建模
R提供了多个包用于GARCH建模,其中最著名的包是rugarch包、rmgarch包(处理多变量模型)以及fGarch包。但是,基本的tseries包也包含了一些GARCH功能。在本章中,我们会展示rugarch包的建模能力。本章中的标记方法遵从rugarch包中各自的输出和文档惯例。
标准GARCH模型
GARCH(p,q)过程可以如下表示:
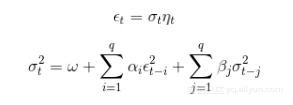

我们的实证案例是对苹果公司股票日收盘价收益率序列的分析,时间跨度从2006年1月1日开始,到2014年3月31日结束。在分析开始之前,作为一种有益的练习,我们建议你重复本章中的数据探索分析,以便确定苹果公司数据中的典型事实。
显然,第一步是安装包,如果它还未安装:
install.packages('rugarch');library('rugarch')
通常,为了获取数据,我们通过quantmod包和getSymbols()函数,基于收盘价计算收益率序列:
#载入苹果股票数据并计算对数收益率
getSymbols("AAPL", from="2006-01-01", to="2014-03-31")
ret.aapl <- dailyReturn(Cl(AAPL), type='log')
chartSeries(ret.aapl)
rugrach包的编程逻辑可以如下理解:无论你的目标是什么(拟合、滤波、预测还是模拟),你首先需要指定一个模型作为系统对象(变量),再依次将它插入各个函数。模型可以通过调用ugrachspec()函数设定。下文的代码设定了一个简单的GARCH(1,1)模型(sGARCH),均值方程中仅有一个常数\mu :
garch11.spec = ugarchspec(variance.model = list(model="sGARCH",
garchOrder=c(1,1)), mean.model = list(armaOrder=c(0,0)))
一种很自然的处理方法是用日收益率时间序列数据拟合模型,即通过极大似然方法估计未知参数。
aapl.garch11.fit = ugarchfit(spec=garch11.spec, data=ret.aapl)
这个函数在一系列输出中提供了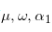 的参数估计:
的参数估计:
> coef(aapl.garch11.fit)
mu omega alpha1 beta1
1.923328e-03 1.027753e-05 8.191681e-02 8.987108e-01
我们可以通过生成对象(即仅仅通过键入这个变量名)的show()方法,获得估计和多种诊断检验。我们也可以通过键入适当的命令得到一大批的其他统计量、参数估计、标准误差和协方差矩阵估计。通过查阅ugarchfit对象类,可以得到完整的输出列表,下文代码展示了最重要的一部分:
coef(msft.garch11.fit) #估计的系数
vcov(msft.garch11.fit) #参数估计量的协方差矩阵
infocriteria(msft.garch11.fit) #常用信息量列表
newsimpact(msft.garch11.fit) #计算信息冲击曲线
signbias(msft.garch11.fit) #Engle - Ng符号偏差检验
fitted(msft.garch11.fit) #获得拟合的数据序列
residuals(msft.garch11.fit) #获得残差
uncvariance(msft.garch11.fit) #无条件的(长期)方差
uncmean(msft.garch11.fit) #无条件的(长期)均值
标准的GARCH模型可以捕捉厚尾性和波动聚集性。但是,要想解释杠杆效应引起的非对称性,我们还需要更高级的模型。为了图示非对称性问题,我们接下来描述信息冲击曲线的概念。
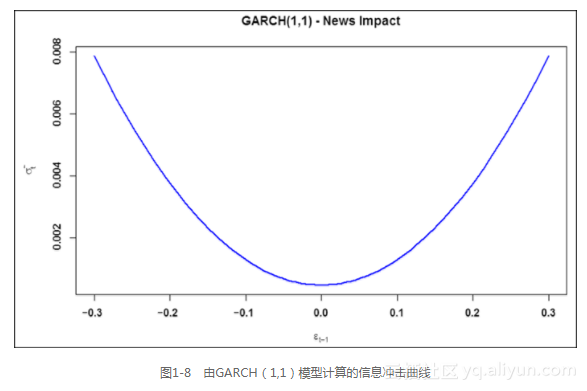
信息冲击曲线,这一概念由Pagan和Schwert(1990)以及Engle和Ng(1991)提出,是一种图示波动对冲击反应的变化度量的有用工具。这个名字源于把新信息影响市场运动看成冲击的通常解释。它们画出了在不同规模冲击下条件波动的变化,可以简明地表达出波动的非对称影响。在如下的代码中,第一行对应着之前GARCH(1,1)模型定义计算的数值化的信息冲击,第二行创建了图形:
ni.garch11 <- newsimpact(aapl.garch11.fit)
plot(ni.garch11$zx, ni.garch11$zy, type="l", lwd=2, col="blue",
main="GARCH(1,1) - News Impact", ylab=ni.garch11$yexpr, xlab=ni.
garch11$xexpr)
上述代码的输出截图如图1-8所示。
正如我们所料,无论对正冲击还是负冲击,波动的响应都不存在非对称性。现在,我们转向也能兼容非对称性的模型。
指数GARCH模型(EGARCH)
Nelson(1991)提出了指数GARCH模型。这种方法直接对条件波动率的对数进行建模:
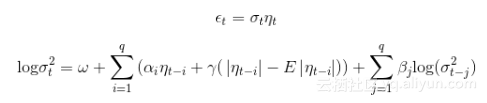
其中,E是期望算子。这个模型形式允许在变化的波动过程中存在乘法的动态。非对称性是由参数{{\alpha }_{i}} 刻画。负值表示过程对负冲击反应更大,正如在实际数据集的观察。
为了拟合EGARCH模型,模型设定中唯一需要改变的参数是设置EGARCH模型类型。通过运行fitting函数,可以估计出其他参数[见coef()]。
# 指定在均值方程中只带有一个常数的EGARCH(1,1) 模型
egarch11.spec = ugarchspec(variance.model = list(model="eGARCH",
garchOrder=c(1,1)), mean.model = list(armaOrder=c(0,0)))
aapl.egarch11.fit = ugarchfit(spec=egarch11.spec, data=ret.aapl)
> coef(aapl.egarch11.fit)
mu omega alpha1 beta1 gamma1
0.001446685 -0.291271433 -0.092855672 0.961968640 0.176796061
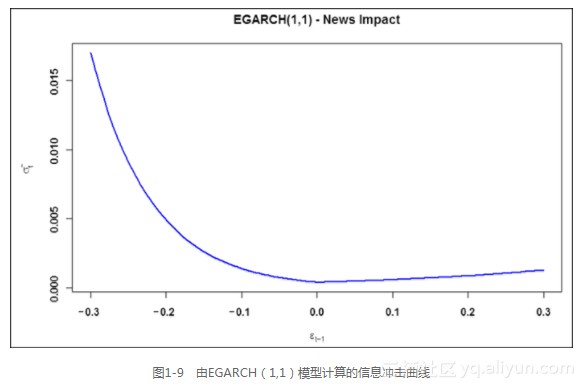
如图1-9所示,信息冲击曲线反映了条件波动对于冲击反应的强烈非对称性,并且证实了非对称性模型的必要性。
ni.egarch11 <- newsimpact(aapl.egarch11.fit)
plot(ni.egarch11$zx, ni.egarch11$zy, type="l", lwd=2, col="blue",
main="EGARCH(1,1) - News Impact",
ylab=ni.egarch11$yexpr, xlab=ni.egarch11$xexpr)
门限GARCH(TGARCH)
另一个著名的例子是TGARCH模型,解释更容易。TGARCH设定了模型参数在一个确定的门限之上和之下是不同的。TGARCH也是一种更一般的类(非对称的幂ARCH类)的子模型,因为它在应用金融计量经济学文献中的广泛深入的运用,我们单独地讨论它。
TGARCH模型的方程式如下:
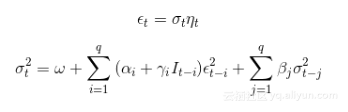
其中
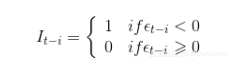
模型解释很直接。ARCH系数依赖于历史误差项的符号。如果{{\gamma }_{i}} 为正,负的误差项会对条件波动率有更高的影响,正如我们之前在杠杆效应所见。
在R的rugarch包中,门限GARCH模型在一类更一般的GARCH模型框架中应用,称为GARCH模型族[Ghalanos(2014)]。
# 指定在均值方程中只带有一个参数的TGARCH(1,1) 模型
tgarch11.spec = ugarchspec(variance.model = list(model="fGARCH",
submodel="TGARCH", garchOrder=c(1,1)),
mean.model = list(armaOrder=c(0,0)))
aapl.tgarch11.fit = ugarchfit(spec=tgarch11.spec, data=ret.aapl)
> coef(aapl.egarch11.fit)f
mu omega alpha1 beta1 gamma1
0.001446685 -0.291271433 -0.092855672 0.961968640 0.176796061
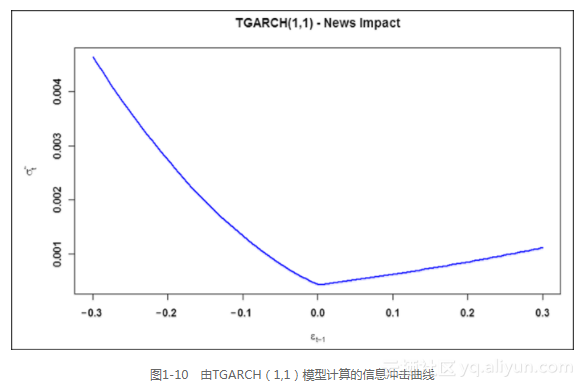
由于特定的函数形式,门限GARCH的信息冲击曲线在表示不同响应时变化更小。运行下列命令,会看到在零点处有一个扭结,如图1-10所示。
ni.tgarch11 <- newsimpact(aapl.tgarch11.fit)
plot(ni.tgarch11$zx, ni.tgarch11$zy, type="l", lwd=2, col="blue",
main="TGARCH(1,1) - News Impact",
ylab=ni.tgarch11$yexpr, xlab=ni.tgarch11$xexpr)
<span style='display:block;text-align:center'>
1.2.2 模拟和预测
rugarch包允许从指定的模型以一种简单的方式模拟。当然,为了模拟,我们还需指定ugarchspec()内的模型参数,这可以通过fixed.pars参数完成。指定GARCH模型和给定条件均值之后,仅用ugarchpath()函数,就可以模拟出一个相应的时间序列:
garch11.spec = ugarchspec(variance.model = list(garchOrder=c(1,1)),
mean.model = list(armaOrder=c(0,0)),
fixed.pars=list(mu = 0, omega=0.1, alpha1=0.1,
beta1 = 0.7))
garch11.sim = ugarchpath(garch11.spec, n.sim=1000)
一旦我们估计好严格拟合的模型,再来预测条件波动率只剩一步之遥:
aapl.garch11.fit = ugarchfit(spec=garch11.spec, data=ret.aapl, out.
sample=20)
aapl.garch11.fcst = ugarchforecast(aapl.garch11.fit, n.ahead=10,
n.roll=10)
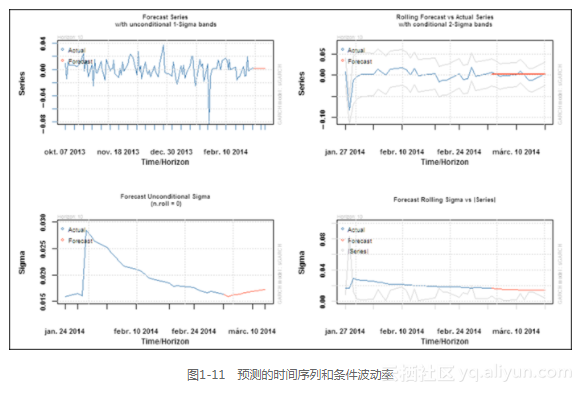
预测序列的绘图方法给用户提供了一个可选菜单,可以画出预测的时间序列或者预测的条件波动率,如图1-11所示。