2.1 时间亚线性算法概述
本节我们通过两个简单的例子来介绍时间亚线性算法的基本概念。
2.1.1 平面图直径问题的亚线性算法
1.问题的定义
平面图直径问题
输入:有m个顶点的平面图(平面图可以放置在平面上而边不交叉),任意两点之间的距离存储在矩阵D中,即点i到点j的距离为Dij。输入满足如下条件:
1) 输入大小是D的大小n=m2。
2) 最大的Dij是图的直径。
3) 点之间的距离对称且满足三角不等式。距离对称意味着i到j的距离等于j到i的距离;满足三角不等式意味着对于i、j、k来说i到j的距离加上j到k的距离要大于i到k的距离。
输出:该图的直径和距离最大的Dij。
矩阵D可以通过基于动态规划的Floyd算法得到。本小节关心的不是计算D的算法,而是以这个D为输入,计算图的直径和距离最大的Dij。
计算这个问题一个直观的想法是把D遍历一次,从中选择最大的Dij。但是问题没那么简单,如果要求运行时间为o(n),也就是运行时间比输入规模n阶低,应如何处理?
是否能做到呢?想精确完成这个问题是不可能的,因为如果有一个“坏人”知道处理过程,由于时间复杂度为o(n)的算法不可能访问所有的数据,这个“坏人”就让输入中没有访问到的数据中包含最大的。这样处理就会令亚线性方法出错。因而,处理这个问题的时间复杂度应该是O(n)。
本小节将讨论一个亚线性的近似算法,这个算法的计算结果可能不是最好的,但是可以计算出一个和原来的结果相差不多的结果。近似算法的动机就是无法在要求的时间内得到精确解,就退而求其次,求出近似的解。
补充知识:近似算法
近似算法主要用来解决优化问题,它不一定能得到最优解但能够给出一个近似解,最优解和近似解相差很小。
对于一个近似算法来说,问题的每一个可行解都具有一个代价,最优解要求具有最大代价(最大化问题)或最小代价(最小化问题)。近似算法的目的是寻找问题的一个和精确解差距最小的近似解,因此,需要分析近似解代价与最优解代价的差距。通常衡量这种差距有三种测度:第一个测度是近似比,这是最常见的方法;第二个测度是相对误差;第三个测度是1+ε近似。
首先看近似比的定义,设A是一个优化问题的近似算法,设n是输入大小,C是A产生的解的代价,C是最优解的代价。如果maxCC,C*C≤p(n),则A具有近似比p(n)。
为了覆盖最大化问题和最小化问题,在近似比的定义中取C/C和C/C中较大者。如果是最大化问题,max{C/C,C/C}=C/C;如果是最小化问题,max{C/C,C/C}=C/C。由于C/C<1当且仅当C/C>1,所以近似比不会小于1,等于1就是精确解。近似比越大,近似解越坏,因此近似比越小越好,在算法里面如果能将近似比降低,那么就是算法上的一个贡献。
另一个常用的测度是相对误差。对于任意输入,近似算法的相对误差定义为C-C/C,其中C是近似解的代价,C是最优解的代价。相应的相对误差界指的是一个近似算法相对误差C-C/C*的上界。
对于一个近似算法,如果其相对误差界为ε(n),则称该算法为1+ε(n)近似算法。
2.平面图直径问题的近似亚线性算法
该算法仅有两步:第一步,随机选择k≤m。第二步,选择使得Dkl最大的l。也就是说,随机看算法的一行,在这行中找出最大的值作为直径。
下面进行算法的时间复杂度分析,对一个输入为m×m的矩阵,算法只需要访问其中的一行。也就是说输入是m的平方,而算法只需访问其中的m,因此时间复杂度是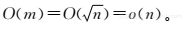
读者会想到上述算法未必得到最优解。确实不一定,但是有了几个输入性质的保证,可以证明该算法在最坏情况下与最优解相差很小,下面的定理说明了这个结论,这意味着即使最坏情况下近似解也不会小于精确解的1/2。
定理2-1 平面图直径问题的亚线性算法的近似比是2。
证明 假设算法的最优解是Dij,那么根据三角不等式,对于选出的k,有Dij≤Dik+Dkj。因为Dkl是所有Dki中的最大值,因此Dik是小于等于Dkl的,Dkj也是小于等于Dkl的。综上所述,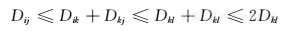 因此,Dij小于等于2Dkl,即近似比为2。■
因此,Dij小于等于2Dkl,即近似比为2。■
2.1.2 排序链表搜索的亚线性算法
排序链表搜索问题
输入:排序双向有序链表R(R中的元素存储在一个无序的队列中),元素x。
输出:如果x在R中,则返回“是”;如果x不在R中,则返回“否”。
问题的目标是确定x是否是输入中给定的n个元素之一。n个元素存储在一个双向链表中,意味着每一个链表中的元素都可以访问它的后一个以及前一个元素,但是链表不能随机访问。表中的元素存放在一个无序队列中,意味着可以根据元素的索引随机访问元素。显然,通过确定性算法不可能在o(n)时间内完成搜索,然而,如果允许随机选择,那么可以在O(n)时间内完成搜索。
因为R上仅支持顺序查找,因而该算法的基本思想是找出一个抽样,在抽样中顺序查找x所在的小范围,继而在R中的此范围内顺序查找x。从R中抽样S,在抽样S中找出和x最接近的点p和q,使得x在区间[p,q)之中,接下来仅在R中p和q之间搜索x。由于p和q是以R/n为概率在S中随机抽样的点且在S中是相邻的,因而S中的元素在区间[p,q)的数学期望是nS。从而算法的时间复杂度是O(R+n/R),为了满足时间复杂度要求,我们取R=Θ(n),则算法的时间复杂度可以达到O(n)。算法的伪代码如算法2-1所示。算法2-1 随机选择算法Random_search(R,x)
1 从输入R中等概率地随机选取Θ(n)个元素,构成集合S。
2 扫描S中所有元素,在O(n)时间内找到最大的p,q∈S,使得p≤x≤q,且满足S中在p和q之间没有任何元素。
3 在输入列表中从p元素开始搜索直到找到x(返回“是”)或者到达q元素(返回“否”)。
定理2-2证明了该算法执行时间的数学期望是O(n),从而说明了该算法是亚线性算法。
定理2-2 上述算法时间复杂度的数学期望是O(n)。
证明 从算法的过程可以看出,算法的运行时间等于O(n)+(p,q间元素个数)。由于S包含Θ(n)个元素,R中p,q间元素的个数的期望值为O(n/S)=O(n)。这表明算法的期望运行时间为O(n)。■
2.1.3 两个多边形交集问题的多项式时间算法
多边形交集问题
输入:二维空间中两个简单多边形A和B,每个都包含n个顶点。
输出:判断A和B是否相交。这个问题可以在O(n)时间内解决,例如,通过观察,这个问题可以被描述成一个二维线性规划实例,在同样的时间里,可以找到A,B交集中的一点或者找到一条将A,B分隔的直线,该直线包含A和B中各一个点,参见参考文献[1]。
下面我们讨论一个能够达到亚线性的随机算法。这个算法假设多边形A和B的顶点以双向链表的形式存储,每一个顶点都将下一个顶点作为后继,按照顺时针顺序排列。算法的伪代码如算法2-2所示。算法2-2 亚线性多边形交集算法Intersection(A,B)
1 分别从A,B中等概率随机选取Θ(n)个顶点的点集CA,CB。
2 在O(n)时间内检测CA,CB是否相交,如不相交则生成一条将CA和CB分隔的直线L。
3 if CA和CB相交then
4 返回“True”
5 else
6 根据L判断A和B是否相交
显然,算法中第1行的时间复杂度为Θ(n),第2行可以利用线性时间多项式相交判定算法实现。下面讨论第6行的实现方法和时间复杂度。
令a和b分别是L上A和B的点,a1和a2是A中和a相邻的两个点。我们现在用如下方法定义多边形PA。如果a1和a2中的点都与CA在L的同一侧,那么PA为空。否则,由于a在L上,a1和a2中只可能有一个在CA的另一侧。不失一般性,设此点为a1。沿着a到a1的方向遍历A中的点,直到再次通过L,如图2-1所示。用同样的方法可以生成PB。则PA和PB的大小为O(n),这个结论留给读者证明。
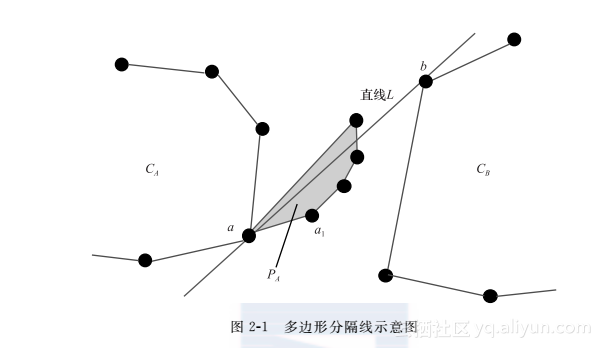
显然A和B相交当且仅当A和PB相交或者B和PA相交。我们仅考虑B和PA相交的判定,A和PB相交的判定方法类似。首先判定CB和PA是否相交,如果相交,则完成判定。否则,生成CB和PA的分隔线LB(通过上述线性算法完成)。接下来,用上述构造的算法递归判定B和PA在LB同一侧的子多边形QB是否和PA相关。于是,B和PA相交当且仅当QB和PA相交。因为QA和PB的期望规模都是O(n),这个判定可以在O(n)时间完成。根据上述构造,两个包含n个顶点的多边形相交性判定问题转化为常数个多边形判定问题,每一个的输入规模都是O(n),因而,我们有如下结论。
结论2-1 判断两个n度凸多边形的相交可以在O(n)时间内解决。