3.9 排列数据
排列可以让我们在某种顺序下观察数据,以便更有效地分析数据。在数据库中,我们可以使用order by语句对指定的列进行数据排序。在R中,我们使用函数order和sort来对数据排序。
准备工作
按照3.3节“转换数据类型”教程,把导入数据的每个属性转换成合适的数据类型。同时按照3.2节“重命名数据变量”中的步骤,命名employees和salaries数据集的列名。
实现步骤

运行原理
R提供了两种排列数据的方法:一个是sort,另一个是order。函数sort返回排序好的向量作为输出。在第1步中,我们设置了一个含有7个整数的整数向量,然后使用函数sort对向量排序,生成一个排序好的输出。经过排序的向量默认是按升序排列的。但是,我们可以把decreasing指定为TRUE改变序列顺序。另外,函数order返回一个排序索引向量作为输出。我们依然可以指定返回的索引是按升序还是按降序排列。
为了在向量中按照升序或者降序排列元素,我们可以使用函数sort。但是,要对某一列的数据排序,我们应该使用函数order。在我们例子中,我们首先拿到了salary属性中各元素的降序索引,然后获取了按照一个排序索引的salaries数据记录。最后,我们找出了按照薪水排列的salaries记录。除了按照一个属性排列数据记录,我们还可以按照多个属性排序记录。我们只需要在函数order中依次放置salary和from_date属性。
更多技能
我们还可以使用plyr中的函数arrange,按照升序的salary和降序的from_date排列薪水数据: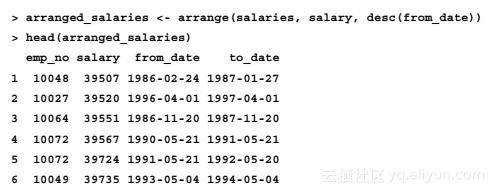
时间: 2025-01-24 07:28:44