本节主要介绍NBody算法的OpenCL性能优化。
1、NBody
NBody系统主要用来通过粒子之间的物理作用力来模拟星系系统。每个粒子表示一个星星,多个粒子之间的相互作用,就呈现出星系的效果。
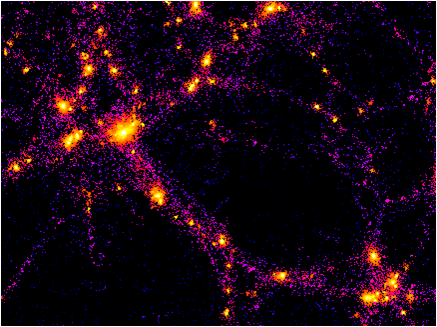
上图为一个粒子模拟星系的图片:Source: THE GALAXY-CLUSTER-SUPERCLUSTER CONNECTION,http://www.casca.ca/ecass/issues/1997-DS/West/west-bil.html
由于每个粒子之间都有相互作用的引力,所以这个算法的复杂度是N2的。下面我们主要探讨如何优化算法以及在OpenCL基础上优化算法。
2、NBody算法
假设两个粒子之间通过万有引力相互作用,则任意两个粒子之间的相互作用力F公式如下:

最笨的方法就是计算每个粒子和其它粒子的作用力之和,这个方法通常称作N-Pair的NBody模拟。
粒子之间的万有引力和它们之间的距离成反比,对于一个粒子而言(假设粒子质量都一样),远距离粒子的作用力有时候很小,甚至可以忽略。Barnes Hut 把3D空间按八叉树进行分割,只有在相邻cell的粒子才直接计算它们之间的引力,远距离cell中的粒子当作一个整体来计算引力。
3、OpenCL优化Nbody
在本节中,我们不考虑算法本身的优化,只是通过OpenCL机制来优化N-Pair的NBody模拟。
最简单的实施方法就是每个例子的作用力相加,代码如下:
for(i=0; i<n; i++){ ax = ay = az = 0;// Loop over all particles "j” for (j=0; j<n; j++) {
//Calculate Displacementdx=x[j]-x[i];dy=y[j]-y[i];dz=z[j]-z[i];
// small eps is delta added for dx,dy,dz = 0invr= 1.0/sqrt(dx*dx+dy*dy+dz*dz +eps);invr3 = invr*invr*invr;f=m[ j ]*invr3;
// Accumulate acceleration ax += f*dx; ay += f*dy;az += f*dx;}// Use ax, ay, az to update particle positions}
我们对每个粒子计算作用在它上面的合力,然后求在合力作用下,delta时间内粒子的新位置,并把这个新位置当作下次计算的输入参数。
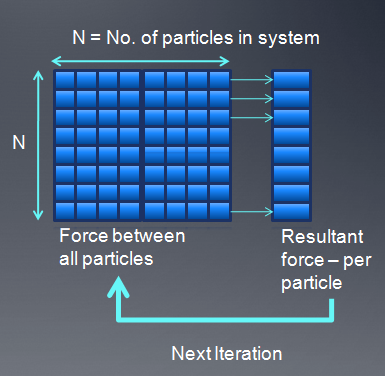
没有优化的OpenCL kernel代码如下:
__kernel void nbody_sim_notile(__global float4* pos ,__global float4* vel,int numBodies,float deltaTime,float epsSqr,__local float4* localPos,__global float4* newPosition,__global float4* newVelocity)
{unsigned int tid = get_local_id(0);unsigned int gid = get_global_id(0);unsigned int localSize = get_local_size(0);
// position of this work-itemfloat4 myPos = pos[gid];float4 acc = (float4)(0.0f, 0.0f, 0.0f, 0.0f);
// load one tile into local memoryint idx = tid * localSize + tid;localPos[tid] = pos[idx];
// calculate acceleration effect due to each body// a[i->j] = m[j] * r[i->j] / (r^2 + epsSqr)^(3/2)for(int j = 0; j < numBodies; ++j){// Calculate acceleartion caused by particle j on particle ilocalPos[tid] = pos[j];float4 r = localPos[j] - myPos;float distSqr = r.x * r.x + r.y * r.y + r.z * r.z;float invDist = 1.0f / sqrt(distSqr + epsSqr);float invDistCube = invDist * invDist * invDist;float s = localPos[j].w * invDistCube;
// accumulate effect of all particlesacc += s * r;}
float4 oldVel = vel[gid];
// updated position and velocityfloat4 newPos = myPos + oldVel * deltaTime + acc * 0.5f * deltaTime * deltaTime;newPos.w = myPos.w;
float4 newVel = oldVel + acc * deltaTime;
// write to global memorynewPosition[gid] = newPos;newVelocity[gid] = newVel;}
在这种实现中,每次都要从global memory中读取其它粒子的位置,速度,内存访问= N reads*N threads= N2
我们可以通过local memory进行优化,一个粒子数据读进来以后,可以被p*p个线程共用,p*p即为workgroup的大小,对于每个粒子,我们通过迭代p*p的tile,累积得到最终结果。
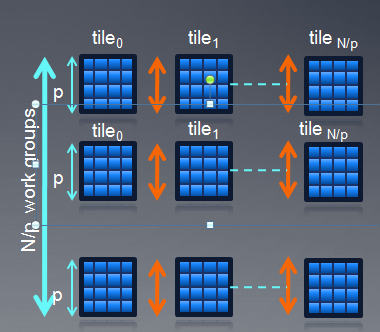
优化后的kernel代码如下:
__kernel void nbody_sim(
__global float4* pos ,
__global float4* vel,
int numBodies,
float deltaTime,
float epsSqr,
__local float4* localPos,__global float4* newPosition,__global float4* newVelocity)
{unsigned int tid = get_local_id(0);
unsigned int gid = get_global_id(0);
unsigned int localSize = get_local_size(0);
// Number of tiles we need to iterate
unsigned int numTiles = numBodies / localSize;
// position of this work-item
float4 myPos = pos[gid];
float4 acc = (float4)(0.0f, 0.0f, 0.0f, 0.0f);
for(int i = 0; i < numTiles; ++i)
{
// load one tile into local memory
int idx = i * localSize + tid;
localPos[tid] = pos[idx];
// Synchronize to make sure data is available for processing
barrier(CLK_LOCAL_MEM_FENCE);
// calculate acceleration effect due to each body
// a[i->j] = m[j] * r[i->j] / (r^2 + epsSqr)^(3/2)
for(int j = 0; j < localSize; ++j)
{
// Calculate acceleartion caused by particle j on particle i
float4 r = localPos[j] - myPos;
float distSqr = r.x * r.x + r.y * r.y + r.z * r.z;
float invDist = 1.0f / sqrt(distSqr + epsSqr);
float invDistCube = invDist * invDist * invDist;
float s = localPos[j].w * invDistCube;
// accumulate effect of all particles
acc += s * r;
}
// Synchronize so that next tile can be loaded
barrier(CLK_LOCAL_MEM_FENCE);
}
float4 oldVel = vel[gid];
// updated position and velocity
float4 newPos = myPos + oldVel * deltaTime + acc * 0.5f * deltaTime * deltaTime;
newPos.w = myPos.w;
float4 newVel = oldVel + acc * deltaTime;
// write to global memory
newPosition[gid] = newPos;
newVelocity[gid] = newVel;}
下面是在AMD, NV两个平台上性能测试结果:
AMD GPU = 5870 Stream SDK 2.2
Nvidia GPU = GTX 480 with CUDA 3.1
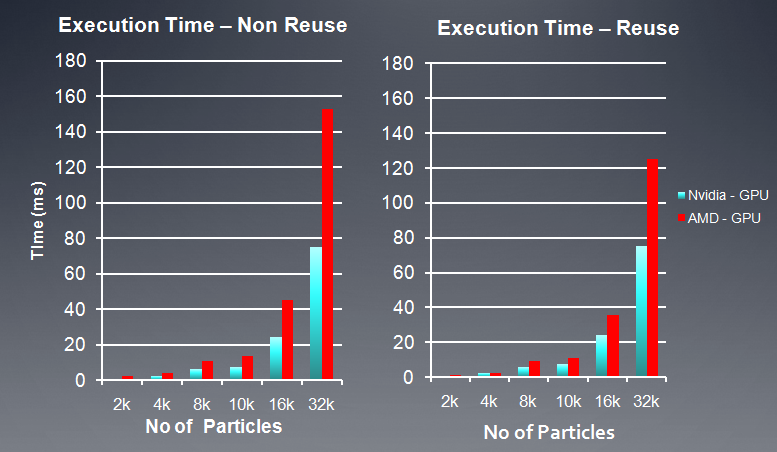
另外,在程序中,也尝试了循环展开,通过展开内循环,从而减少GPU执行分支指令,我的测试中,使用展开四次,得到的FPS比没展开前快了30%。(AMD 5670显卡)。具体实现可以看kernel代码中的__kernel void nbody_sim_unroll函数。在AMD平台上,使用向量化也可以提高10%左右的性能。
最后提供2篇NBody优化的文章:
—Nvidia GPU Gems
—http://http.developer.nvidia.com/GPUGems3/gpugems3_ch31.html
—Brown Deer Technology
—http://www.browndeertechnology.com/docs/BDT_OpenCL_Tutorial_NBody.html
完整的代码可从:http://code.google.com/p/imagefilter-opencl/downloads/detail?name=amduniCourseCode7.zip&can=2&q=#makechanges 下载。