问题引入
“鸟儿啊,听说微软至SQL Server 2012以来,推出了一种全新的基于列式存储的索引,你去研究看看SQL Server on Linux对这个功能的支持度如何,效率有多大的提升?”。老鸟又迫不及待的开始给菜鸟分配任务。
分析问题
的确如老鸟所说,从SQL Server 2012开始推出了列存储索引,这个版本限制颇多,但是它对统计查询的效率提升又是实实在在的。所以,让我们来看看SQL Server on Linux列存储索引对统计查询的效率提升情况如何。
这里也顺便提一下SQL Server 2012 列存储索引的限制,比如:
非聚集列存储索引是只读的,换句话说,基表会变成Read-Only
仅支持非聚集列存储索引
只能通过删除及创建索引的方式重建索引,而不可使用ALTER INDEX命令
对应的表不可包含唯一性约束、主键约束或外键约束
......
解决问题
这一小节,我们以一组对比测试来看看列存储索引相对于B-Tree索引对统计查询的效率提升,真正是强大到没有敌人。
创建测试对象
测试之前,我们需要创建测试表对象,B-Tree索引和列存储索引,并且初始化500万条记录数据,做为测试的基础数据。
use tempdb
GO
IF OBJECT_ID('dbo.Table_with_5M_rows','U') IS NOT NULL
DROP TABLE dbo.Table_with_5M_rows
GO
CREATE TABLE [dbo].[Table_with_5M_rows](
[OrderItemId] [bigint] NULL,
[OrderId] [int] NULL,
[Price] [int] NULL,
[ProductName] [varchar](240) NULL
) ON [PRIMARY]
GO
;WITH a
AS (
SELECT *
FROM (VALUES(1),(2),(3),(4),(5),(6),(7),(8),(9),(10)) AS a(a)
)
INSERT INTO Table_with_5M_rows
SELECT TOP(5000000)
OrderItemId = ROW_NUMBER() OVER (ORDER BY a.a)
,OrderId = a.a + b.a + c.a + d.a + e.a + f.a + g.a + h.a
,Price = a.a * 10
,ProductName = cast(a.a as varchar) + cast(b.a as varchar) + cast(c.a as varchar) + cast(d.a as varchar) + cast(e.a as varchar) + cast(f.a as varchar) + cast(g.a as varchar) + cast(h.a as varchar)
FROM a, a AS b, a AS c, a AS d, a AS e, a AS f, a AS g, a AS h;
GO
--Create regular index
CREATE NONCLUSTERED INDEX IX_OrderId_@price
ON dbo.Table_with_5M_rows(OrderId)
INCLUDE(price) WITH(ONLINE =ON)
GO
--create columnstore index
CREATE CLUSTERED COLUMNSTORE INDEX CSIX_Table_with_5M_rows ON dbo.Table_with_5M_rows;
GO
对象创建完毕后,截图如下: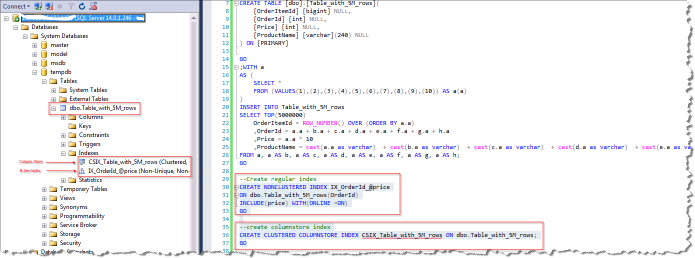
执行测试查询
首先,我们来测试使用B-Tree常规索引的查询效率,业务场景是统计每一个订单的消费总额和平均每单价格。这里,我们强制查询语句使用索引IX_OrderId_@price,需要注意的地方是,在执行查询语句之前,我们需要清空缓存来避免缓存对执行结果的影响。查询语句如下:
--clear data cache
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
GO
--open statistics
SET STATISTICS IO ON
SET STATISTICS TIME ON
GO
--Testing using B-tree index
SELECT
OrderId
,totalAmount = sum(price)
,avgPrice = avg(price)
FROM Table_with_5M_rows WITH(NOLOCK, INDEX=IX_OrderId_@price)
GROUP BY OrderId
GO
同样的道理,在对比组查询测试最开始,我们需要清空SQL Server缓存,然后强制使用列存储索引CSIX_Table_with_5M_rows,语句如下:
--clear data cache
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
GO
--Testing using Column store index
SELECT
OrderId
,totalAmount = sum(price)
,avgPrice = avg(price)
FROM Table_with_5M_rows WITH(NOLOCK, INDEX=CSIX_Table_with_5M_rows)
GROUP BY OrderId
GO
对比测试结果
两组查询测试语句执行完毕,以下我通过统计信息和执行计划两个方面来对比测试结果。
B-Tree索引查询统计信息:
Table 'Table_with_5M_rows'. Scan count 1, logical reads 16136, physical reads 0, read-ahead reads 7, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1295 ms, elapsed time = 1313 ms.
列存储索引查询统计信息:
Table 'Table_with_5M_rows'. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 73, lob physical reads 7, lob read-ahead reads 0.
Table 'Table_with_5M_rows'. Segment reads 6, segment skipped 0.
SQL Server Execution Times:
CPU time = 5 ms, elapsed time = 15 ms.
从查询执行的统计信息输出来看,基于B-Tree索引的查询逻辑读IO为16136,CPU消耗为1295毫秒,执行时间为1313毫秒,而基于列存储索引的查询逻辑读IO为0,CPU消耗为5毫秒,执行时间15毫秒。CPU和执行时间上有259倍和87倍的性能提升。
B-Tree索引查询执行计划截图: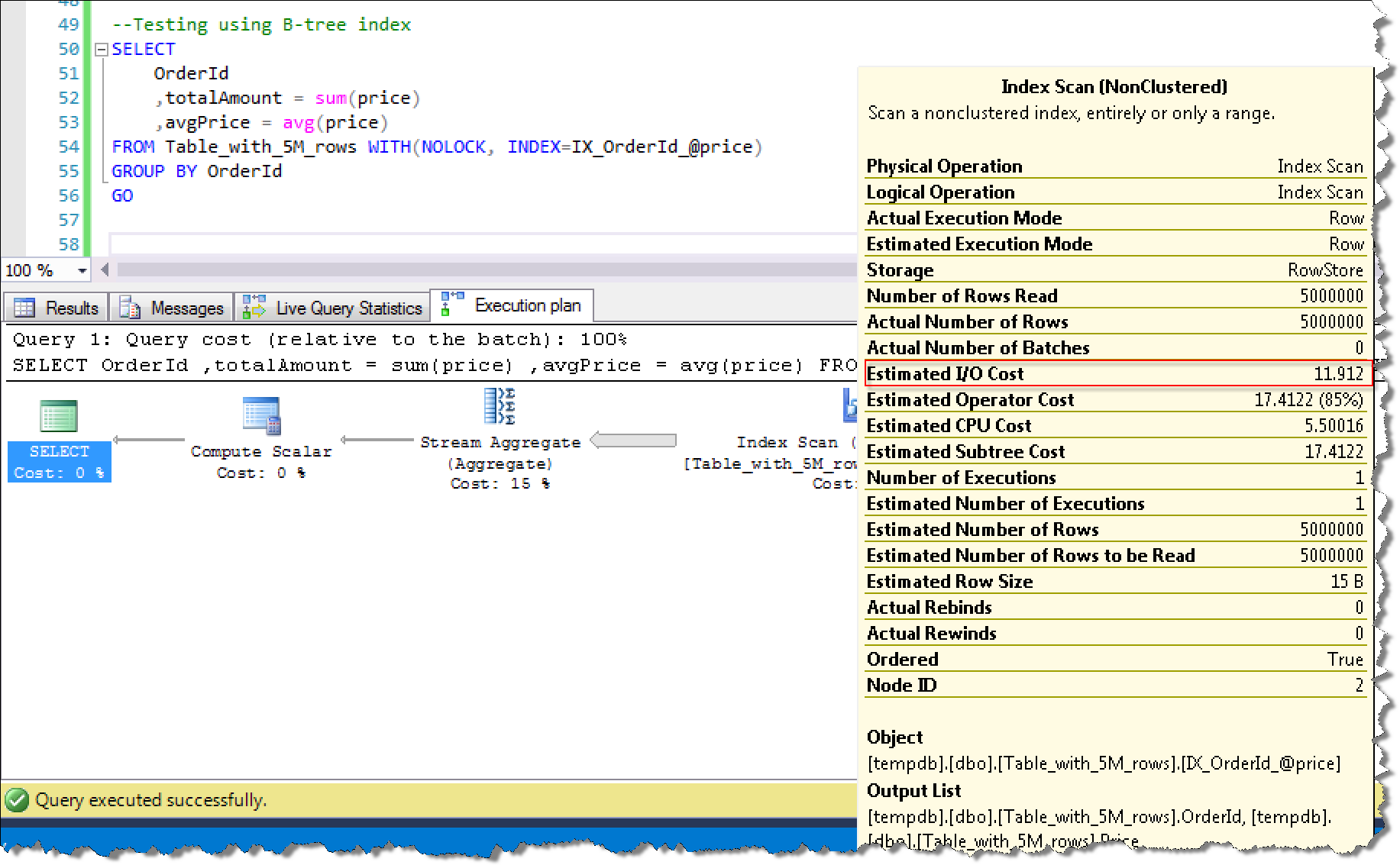
列存储索引查询执行计划截图: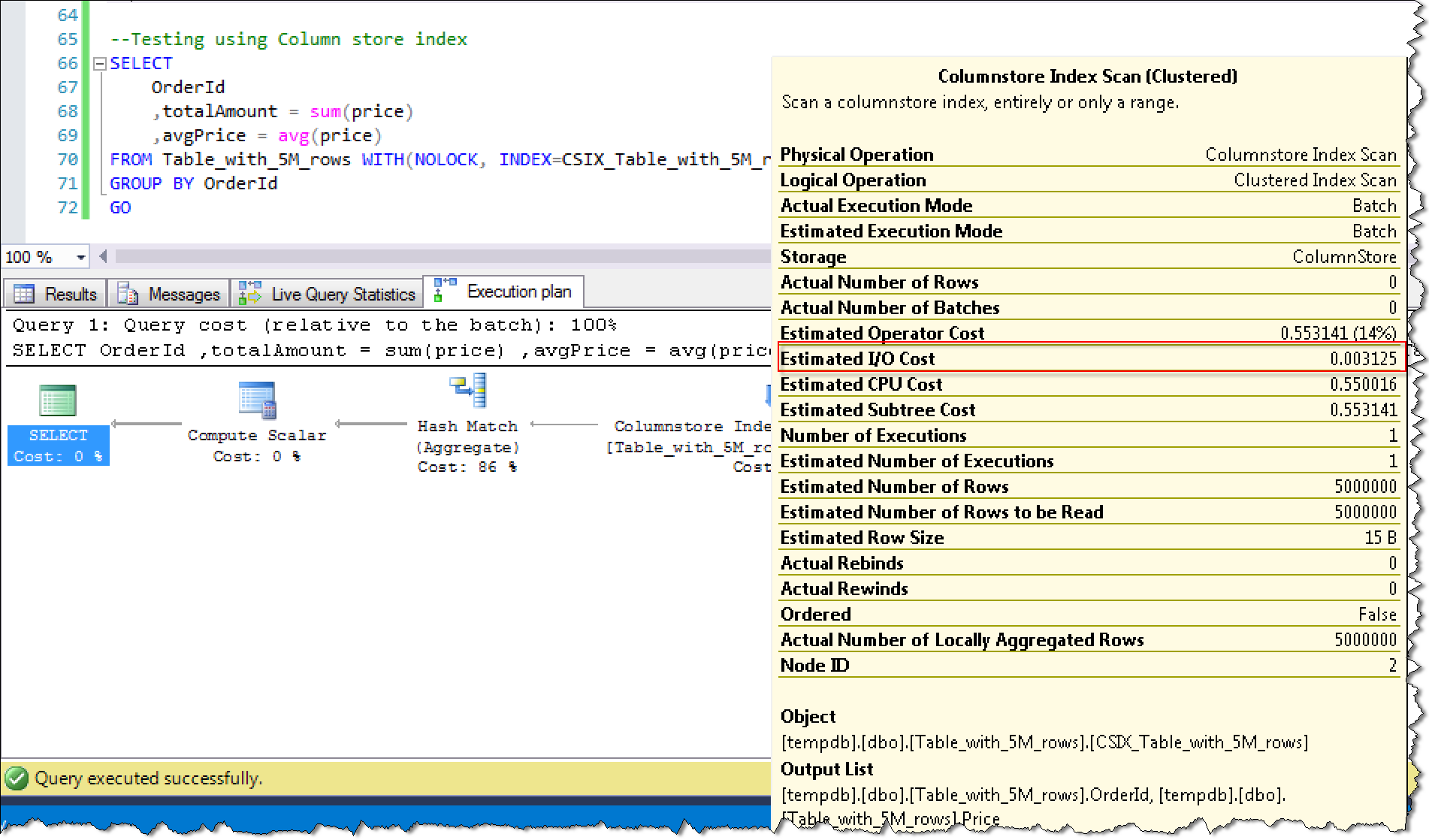
从实际的执行计划对比来看,IO消耗从11.912降低到0.003125,大大节约了IO的性能开销,这也是为什么性能提升非常显著的原因。
写在最后
SQL Server on Linux对列存储索引的支持这点非常强大,对于统计查询效率的提升尤其是IO的提升相当明显。