如今Bigtable型(列族)数据库应用越来越广,功能也很强大。但是很多人还是把它当做关系型数据库在使用,用原来关系型数据库的思维建表、存储、查询。本文以hbase举例讲述数据模式的变化。
传统关系型数据库(mysql,oracle)数据存储方式主要如下: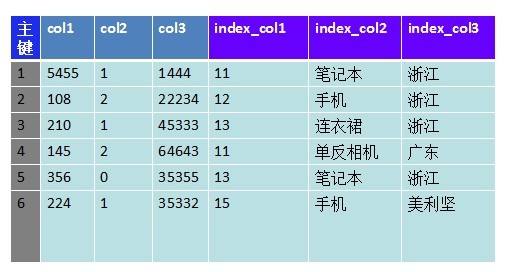
图一
上图是个很典型的数据储存方式,我把每条记录分成3部分:主键、记录属性、索引字段。我们会对索引字段建立索引,达到二级索引的效果。
但是随着业务的发展,查询条件越来越复杂,需要更多的索引字段,且很多值都不存在,如下图:
图二
上图是6个索引字段,实际情况可能是上百个甚至更多,并且还需要根据多个索引字段刷选。查询性能越来越低,甚至无法满足查询要求。关系型数据里的局限也开始显现,于是很多人开始接触NoSQL。
列族数据库很强大,很多人就想把数据从mysql迁到hbase,存储的方式还是跟图一或者图二一样,主键为rowkey。其他各个字段的数据,存 储一个列族下的不同列。但是想对索引字段查询就没有办法,目前还没有比较好的基于bigtable的二级索引方案,所以无法对索引字段做查询。
这时候其实可以转换下思维,可以把数据倒过来,如下图:
图三
把各个索引字段的值作为rowkey,然后把记录的主键和属性值按照一定顺序存在对应rowkey的value里。上图只有一个列族,是最简单的方式。 Value里的记录可以设置成定长的byte[],多个记录集合通过移位快速查询到。
但是上面只适合单个索引字段的查询。如果要同时对多个索引字段查询,图三的方式需要求取出所有value值,比如查询“浙江”and“手机”,需要取出两个value,再解析出各自的主键求交。如果每条记录的属性有上百个,对性能影响很大。
接下来的变化是解决多索引字段查询的问题。我们将主键字段和属性字段分开存储,储存在不同的列族下,多索引查询只需要取出列族1下的数据,再去最小集合的列族2里取得想要的值。储存如图四: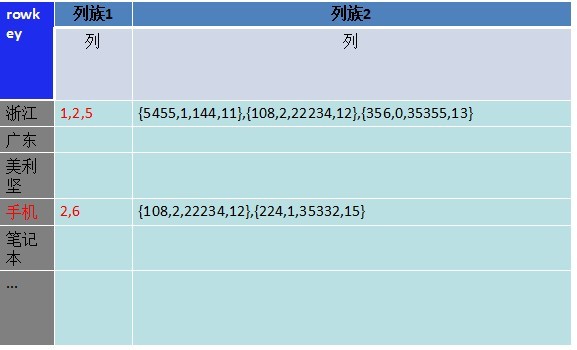
图四
为什么是不同列族,而不是一个列族下的两个列?
列族数据库数据文件是按照列族分的。在取数据时,都会把一个列族的所有列数据都取出来,事实上我们并不需要把记录明细取出来,所以把这部分数据放到了另一个列族下。
接下来是对列族2扩展,列族2储存更多的列,用来做各种刷选、计算处理。如下图: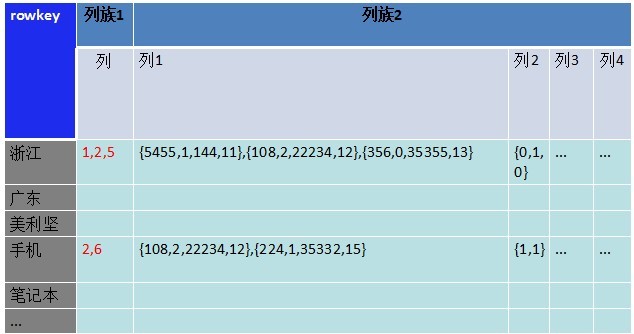
图五
后来我感觉这玩样越来越像搜索了。。。