MaxCompute(原ODPS)是阿里云自主研发的具有业界领先水平的分布式大数据处理平台, 尤其在集团内部得到广泛应用,支撑了多个BU的核心业务。 MaxCompute除了持续优化性能外,也致力于提升SQL语言的用户体验和表达能力,提高广大ODPS开发者的生产力。
MaxCompute基于ODPS2.0新一代的SQL引擎,显著提升了SQL语言编译过程的易用性与语言的表达能力。我们在此推出MaxCompute(ODPS2.0)重装上阵系列文章
第一弹 - 善用MaxCompute编译器的错误和警告
第二弹 - 新的基本数据类型与内建函数
第三弹 - 复杂类型
第四弹 - CTE,VALUES,SEMIJOIN
上次向您介绍了复杂类型,从本篇开始,向您介绍MaxCompute在SQL语言DML方面的改进
- 场景1
_需要写一个复现的SQL, 从多个表中读取数据,有些之间做Join,有些之间做Union,生成中间数据又要Join, 最后需要输出多张表,最后写成了n层嵌套的子查询,自己都看不懂了。而且同样的查询,在不同的子查询中有重复。为了维护方便,把复杂的语句拆成多个语句,但是发现每个语句都需要单独提交,排队,并且要将中间结果写到本来不需要的临时表,在后面的语句中再读出来,慢了好多。。。 - 场景2
正在开发新项目,需要给一个小数据表准备些基本数据,但是没有INSERT ... VALUES 语句,没办法把数据和创建表的DDL放在一起维护,只好另用一些脚本,调用ODPS命令行准备数据。。。 - 场景3
想测试一个新写的UDF,只写SELECT myudf('123');会报错,还必须创建一个dual表,里面加一行数据,好麻烦。如果测试UDAF,还要在测试表里面准备多行数据,每次测试不同的输入都要修改表内容或者创建新表,如果有个办法不用创建表也能不同的数据组合测试我的UDF就好了。。。 - 场景4
迁移一个原来在Oracle上面的ETL系统,发现用了WHERE EXISTS( SELECT ...)和WHERE IN (SELECT ...)这类的语句,可是发现ODPS在这方面支持不完整,还要手工将这些半连接的语句转换为普通JOIN,再过滤。。。
MaxCompute采用基于ODPS2.0的SQL引擎,对DML进行了大幅扩充,提高了易用性和兼容性,基本解决了上述问题。
Common Table Expression (CTE)
MaxCompute支持SQL标准的CTE。能够提高SQL语句的可读性与执行效率。
此文中采用MaxCompute Studio作展示,首先,安装MaxCompute Studio,导入测试MaxCompute项目,创建工程,建立一个新的MaxCompute脚本文件, 如下
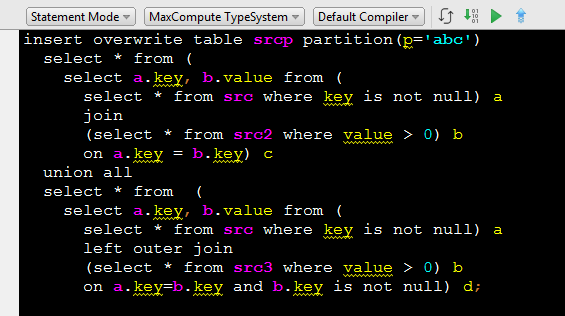
可以看到,顶层的union两侧各为一个join,join的左表是相同的查询。通过写子查询的方式,只能重复这段代码。
使用CTE的方式重写以上语句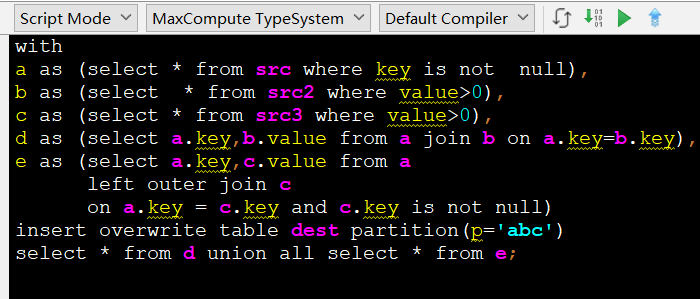
可以看到,a对应的子查询只需要写一次,在后面重用,CTE的WITH字句中可以指定多个子查询,像使用变量一样在整个语句中反复重用。除了重用外,也不必再反复嵌套了。
编译此脚本,可以观察执行计划如下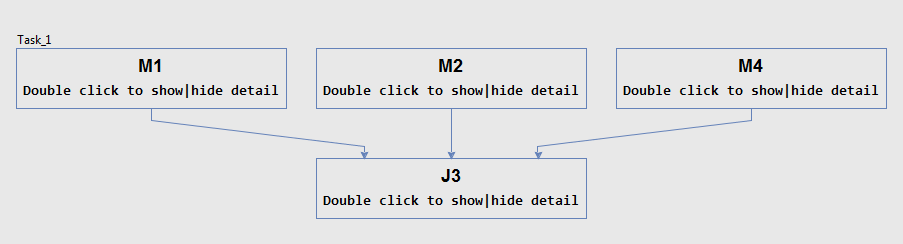
其中M1, M2, M4三个分布式任务分别对应对应三个输入表,双击M2可以看到中具体执行的DAG(在DAG中再次双击可以返回),如下
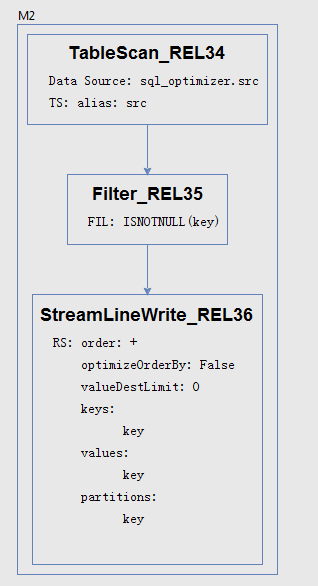
可以看到对src读后进行过滤的DAG。对src的读取与过滤在整个执行计划中只需要一次 ( 注1 )。
VALUES
创建一个新的文件,如下: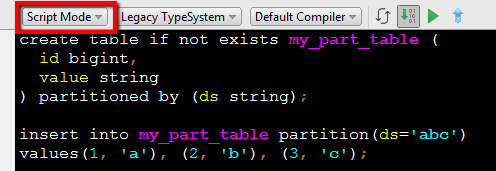
执行后在,MaxCompute Project Explorer中可以找到新创建的表,并看到values中的数据已经插入到表中,如下: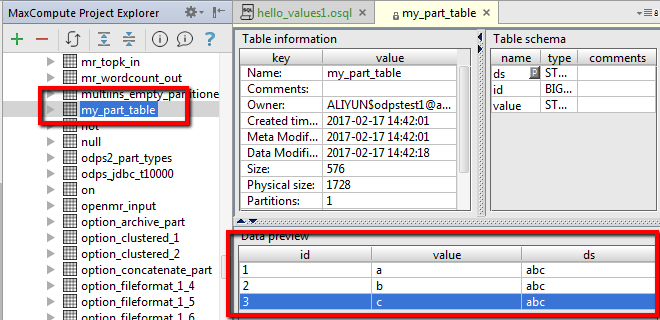
有的时候表的列很多,准备数据的时候希望只插入部分列的数据,此时可以用插入列表功能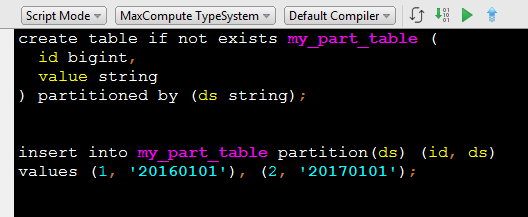
执行后,MaxCompute Project Explorer中找到目标表,并看到values中的数据已经插入,如下:
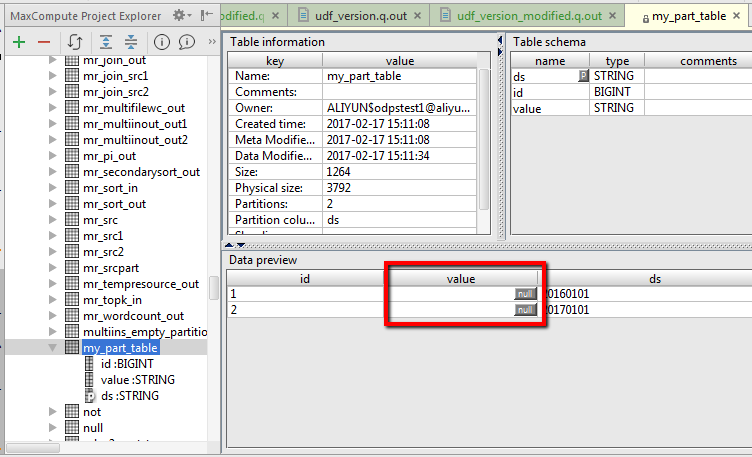
对于在values中没有制定的列,可以看到取缺省值为NULL。插入列表功能不一定和VALUES一起用,对于INSERT INTO ... SELECT..., 同样可以使用。
INSERT... VALUES... 有一个限制,values必须是常量,但是有的时候希望在插入的数据中进行一些简单的运算,这个时候可以使用MaxCompute的VALUES TABLE功能,如下:
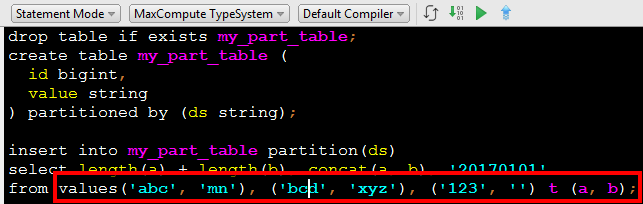
其中的VALUES (...), (...) t (a, b), 相当于定义了一个名为t,列为a, b的表,类型为(a string, b string),其中的类型从VALUES列表中推导。这样在不准备任何物理表的时候,可以模拟一个有任意数据的,多行的表,并进行任意运算。
实际上,VALUES表并不限于在INSERT语句中使用,任何DML语句都可以使用。
还有一种VALUES表的特殊形式
select abs(-1), length('abc'), getdate();
也就是可以不写from语句,直接执行SELECT,只要SELECT的表达式列表不用任何上游表数据就可以。其底层实现为从一个1行,0列的匿名VALUES表选取。这样,在希望测试一些函数,比如自己的UDF等,就再也不用手工创建DUAL表了。
SEMI JOIN
MaxCompute支持SEMI JOIN(半连接)。SEMI JOIN中,右表只用来过滤左表的数据而不出现在结果集中。支持的语法包括LEFT SEMI JOIN,LEFT ANTI JOIN,(NOT) IN SUBQUERY,(NOT) EXISTS
LEFT SEMI JOIN
返回左表中的数据,当join条件成立,也就是mytable1中某行的id在mytable2的所有id中出现过,此行就保留在结果集中
例如:SELECT * from mytable1 a LEFT SEMI JOIN mytable2 b on a.id=b.id;
只会返回mytable1中的数据,只要mytable1的id在mytable2的id中出现过
LEFT ANTI JOIN
返回左表中的数据,当join条件不成立,也就是mytable1中某行的id在mytable2的所有id中没有出现过,此行就保留在结果集中
例如:
SELECT * from mytable1 a LEFT ANTI JOIN mytable2 b on a.id=b.id;
只会返回mytable1中的数据,只要mytable1的id在mytable2的id没有出现过
IN SUBQUERY/NOT IN SUBQUERY
IN SUBQUERY与LEFT SEMI JOIN类似。
例如:
SELECT * from mytable1 where id in (select id from mytable2);
等效于
SELECT * from mytable1 a LEFT SEMI JOIN mytable2 b on a.id=b.id;
原有ODPS也支持IN SUBQUERY,但是不支持correlated条件,MaxCompute支持
例如:
SELECT * from mytable1 where id in (select id from mytable2 where value = mytable1.value);
其中子查询中的where value = mytable1.value就是一个correlated条件,原有ODPS对于这种既引用了子查询中源表,由引用了外层查询源表的表达式时,会报告错误。MaxCompute支持这种用法,这样的过滤条件事实上构成了SEMI JOIN中的ON条件的一部分。
对于NOT IN SUBQUERY,类似于LEFT ANTI JOIN,但是有一点显著不同
例如:
SELECT * from mytable1 where id not in (select id from mytable2);
如果mytable2中的所有id都不为NULL,则等效于
SELECT * from mytable1 a LEFT ANTI JOIN mytable2 b on a.id=b.id;
但是,如果mytable2中有任何为NULL的列,则 not in表达式会为NULL,导致where条件不成立,无数据返回,此时与LEFT ANTI JOIN不同。
原有ODPS也支持[NOT] IN SUBQUERY不作为JOIN条件,例如出现在非WHERE语句中,或者虽然在WHERE语句中,但无法转换为JOIN条件。MaxCompute仍然支持这种用法,但是此时因为无法转换为SEMI JOIN而必须实现启动一个单独的作业来运行SUBQUERY,所以不支持correlated条件。
例如:
SELECT * from mytable1 where id in (select id from mytable2) OR value > 0;
因为WHERE中包含了OR,导致无法转换为SEMI JOIN,会单独启动作业执行子查询
另外在处理分区表的时候,也会有特殊处理
SELECT * from sales_detail where ds in (select dt from sales_date);
其中的ds如果是分区列,则select dt from sales_date 会单独启动作业执行子查询,而不会转化为SEMIJOIN,执行后的结果会逐个与ds比较,sales_detail中ds值不在返回结果中的分区不会读取,保证分区裁剪仍然有效。
EXISTS SUBQUERY/NOT EXISTS SUBQUERY
当SUBQUERY中有至少一行数据时候,返回TRUE,否则FALSE。NOT EXISTS的时候则相反。目前只支持含有correlated WHERE条件的子查询。EXISTS SUBQUERY/NOT EXISTS SUBQUERY实现的方式是转换为LEFT SEMI JOIN或者LEFT ANTI JOIN
例如:
SELECT from mytable1 where exists (select from mytable2 where id = mytable1.id);`
等效于
SELECT * from mytable1 a LEFT SEMI JOIN mytable2 b on a.id=b.id;
而
SELECT from mytable1 where not exists (select from mytable2 where id = mytable1.id);`
则等效于
SELECT * from mytable1 a LEFT ANTI JOIN mytable2 b on a.id=b.id;
其他改进
- MaxCompute支持UNION [DISTINCT] - 其中DISTINCT为忽略
SELECT FROM src1 UNION SELECT FROM src2;
执行的效果相当于
SELECT DISTINCT FROM (SELECT FROM src1 UNION ALL SELECT * FROM src2) t;
支持IMPLICIT JOIN
SELECT * FROM table1, table2 WHERE table1.id = table2.id;
执行的效果相当于
SELECT * FROM table1 JOIN table2 ON table1.id = table2.id;
此功能主要是方便从其他数据库系统迁移,对于信贷买,我们还是推荐您使用JOIN,明确表示意图
支持新的SELECT语序
在一个完整的查询语句中,例如
SELECT key, max(value) FROM src t WHERE value > 0 GROUP BY key HAVING sum(value) > 100 ORDER BY key LIMIT 100;
实际上的逻辑执行顺序是 FROM->WHERE->GROUY BY->HAVING->SELECT->ORDER BY->LIMIT,前一个是后一个的输入,与标准的书写语序实际并不相同。很多容易混淆的问题,都是由此引起的。例如order by中只能引用select列表中生成的列,而不是访问FROM的源表中的列。HAVING可以访问的是 group by key和聚合函数。SELECT的时候,如果有GROUP BY,就只能访问group key和聚合函数,而不是FROM中源表中的列。
MaxCompute支持以执行顺序书写查询语句,例如上面的语句可以写为
FROM src t WHERE value > 0 GROUP BY key HAVING sum(value) > 100 SELECT key, max(value) ORDER BY key LIMIT 100;
书写顺序和执行顺序一致,就不容易混淆了。这样有一个额外的好处,在MaxCompute Studio中写SQL语句的时候,会有智能提示的功能,如果是SELECT在前,书写select列表的表达式的时候,因为FROM还没有写,MaxCompute Studio没办法知道可能访问那些列,也就不能做提示。如下
需要先写好FROM,再回头写SELECT列表,才能提示。如下

如果使用上述以FROM起始的方式书写,则可以自然而然的根据上下文进行提示。如下

支持顶层UNION
ODPS1.0不支持顶层UNION。ODPS2.0可以支持,例如
SELECT FROM src UNION ALL SELECT FROM src;
UNION后LIMIT的语义变化。
大部分DBMS系统中,如MySQL,Hive等,UNION后如果有CLUSTER BY, DISTRIBUTE BY, SORT BY, ORDER BY或者LIMIT子句,其作用于与前面所有UNION的结果,而不是UNION的最后一路。ODPS2.0在set odps.sql.type.system.odps2=true;的时候,也采用此行为。例如:
set odps.sql.type.system.odps2=true;
SELECT explode(array(1, 3)) AS (a) UNION ALL SELECT explode(array(0, 2, 4)) AS (a) ORDER BY a LIMIT 3;
返回
| a |
|---|
| 0 |
| 1 |
| 2 |
小节
MaxCompute大大扩充了DML语句的支持,在易用性,兼容性和性能方面,可以更好的满足您的需求。对于SQL比较熟悉的专家会发现,上述功能大部分是标准的SQL支持的功能。MaxCompute会持续提升与标准SQL和业界常用产品的兼容性。
除此之外,针对MaxCompute用户的特点,也就是需要在非常复杂的业务场景下,支持对己大量数据的处理,MaxCompute提供了特有的脚本模式和参数化视图,将在下一次为您介绍。
标注
- 注1
是否合并或者分裂子查询,是由ODPS2.0的基于代价的优化器 (CBO)做出决定的,SQL本身的书写方式,不管是CTE还是子查询,并不能确保物理执行计划的合并或者分裂。