2.3监督学习和无监督学习
前一节中,我们看到即使一个非常简单的分类问题都存在无数的边界,然而,我们很难说究竟它们中哪一个是最合适的。这是因为,即便针对已知数据我们可以恰当地分类,这也并不能保证对未知数据能够达到相同效果。不过,你可以提高模式识别的准确率。每一种机器学习方法都会设置一个标准来进行更好地模式分类,决定最佳可能的边界——决策边界——从而提高识别的准确率。毫无疑问,这些标准使用不同的方法时差异很大。在本节中,我们将介绍本书所涉及的各种方法。
首先,从广义划分而言,机器学习可以分为监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)。这两种分类之间的差异是机器学习使用的数据集是否加了标签,即有标数据还是无标数据。监督学习中,机器使用包含输入和输出数据的标签数据,并确定与之相适应的模式方法模式进行分类结合起来完成工作。当机器接收到未知数据时,它会判断可以应用哪一种模式,并依据标签数据——过去的正确答案,对新的数据进行分类。举个例子,在图像识别领域,如果你准备并提供一定数量的猫的图片(并将其标记为“猫”)和同样数量的人类的图片(并将其标记为“人类”),之后你输入一些图像让机器进行学习,它能够自己进行判断这些图片应该被归类到猫或者人类的图片中(抑或二者都不属于)。当然,仅仅只是对图像是猫还是人进行判断并没有太多的实用价值,不过,如果你完全将这一技术应用到其他领域,譬如你可以创建一个系统,它能够自动地对上传到社交媒体中的图片进行标记,说明照片中的人是谁。综上所述,监督学习需要人们预先准备正确的数据,机器才能展开学习。
另一方面,无监督学习中,机器使用未标记的数据。这种情况下,只需要提供输入数据即可。机器学习的是数据集中隐含和包括的模式和规则。无监督学习的目标是掌握数据的形态。它包含了一个名为“聚类(Clustering)”的过程,它将一组具有共同特征的数据划分到一起,或者抽取出其中的关联规则。譬如,假如你手上有一组数据,是用户的年龄、性别以及访问在线购物网站的购买趋势。那么,你可能会发现,男性在二十多岁时的购物偏好和女性四十多岁时的购物偏好非常相近,你也许可以利用这种趋势改进你的产品市场策略。关于这一点,我们有一个著名的案例——通过无监督学习,人们发现大量的人在购买啤酒的同时会购买尿布。
现在,你知道监督学习和无监督学习之间存在着巨大的差别,但这还不是全部。每一种学习方法及对应的算法分别还有自己的不同。接下来的一节,让我们看看一些代表性的示例。
2.3.1支持向量机
你大概已经知道支持向量机(Support Vector Machine, SVM)是机器学习中最流行的监督学习方法。该方法仍被广泛地应用于数据挖掘产业。使用支持向量机方法时,它会在每类数据中寻找与其他类最接近的数据,并将其标记为标准,决策边界就通过这些标准定义,这样每个标记数据与边界的欧几里德距离之和最大。这些标记数据被称之为支持向量(Support Vector)。简而言之,支持向量机将决策边界设定到了一个中间位置,使得每种模式到其的距离都最远。因此,支持向量机在算法上也被称之为“最大化间隔”算法。下面这幅图解释了支持向量机的概念:
如果仅仅只听这些,你也许会疑惑“它是这样的吗?”,不过让支持向量机最有价值的是一种数学技术:核技巧(Kernel Trick),或者核方法(Kernel Method)。使用这种技术,我们可以将低维度无法线性分类的数据,映射到更高维的空间,之后就能毫不费力地以线性方式对其进行分类。看看下面这幅图,你就能理解内核技巧是以怎样的方式进行工作的了: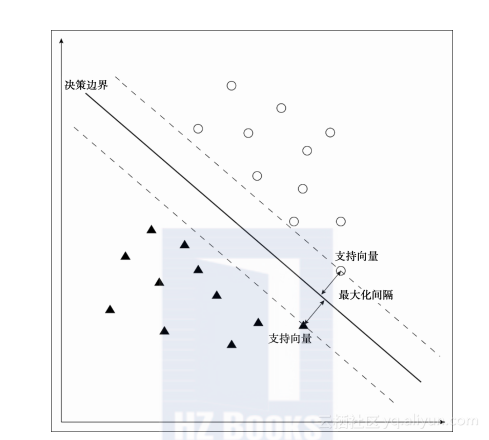
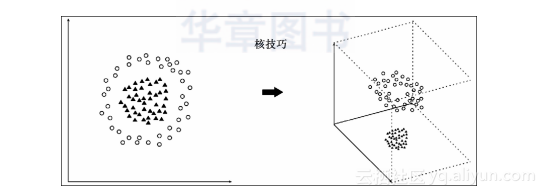
我们有两种类型的数据,分别以圆形和三角形代表,很明显,我们无法在二维空间中以线性的方式对其进行分类。然而,正如你在上图中看到的那样,一旦对这些数据(严格来说,是训练数据的特征向量)使用“核函数”,所有的数据会被转换到一个更高的维度空间,即三维空间,在这个空间里,我们可以使用二维平面对它们进行分类。
虽然支持向量机既有用又优雅,它依然有其局限性。由于支持向量机需要把数据映射到高维空间,通常情况下,计算量都会增大,因此,使用支持向量机时,随着计算复杂度的增大,它所消耗的时间也会迅速增加。
2.3.2隐马尔可夫模型
隐马尔可夫模型(Hidden Markov Model, HMM)是一种无监督训练方法,它假设所有的数据都遵循马尔可夫过程(Markov Process)。马尔可夫过程是一种随机过程,它假设未来状态只与当前值相关,而与过去的状态无关。隐马尔可夫模型主要用于预测只有一个可观察序列可见时,该观察对象可能的状态。
单凭前面的介绍,你可能还是无法全面地理解隐马尔可夫模型是如何工作的,那我们就一起来看一个例子。隐马尔可夫模型经常被用于分析碱基序列(Base Sequence)。你可能知道一个碱基序列包含了四个核苷酸(Nucleotide),譬如说A、T、G、C;碱基序列实际上就是这些核苷酸构成的串。如果仅仅是看这个串你得不到任何信息,你还需要分析它们与某一个基因的相对关系。如果我们假设,任何的碱基序列都是随机排列的,那么你从碱基序列中截取任意部分,这四个字母出现的几率都是百分之二十五。
然而,如果碱基序列的排列遵循一定的规律,譬如,C通常出现在G的后面 ,或者ATT字母的组合出现频率更高,那么每一种字符出现的概率也会随之发生变化。这种规律就是概率模型,如果输出的概率模型只依赖于它的直接前基,你就可以凭借隐马尔可夫模型从碱基序列(可观察状态序列)中定位出遗传信息(隐藏状态序列)。
除了生物信息领域,隐马尔可夫模型也常用于需要时间序列模式的领域,譬如自然语言处理(Natural Language Processing, NLP)的语法分析,或者是声音信号处理。我们在这儿并未深入介绍隐马尔可夫模型,因为它的算法与深度学习相关性不大,不过如果你想了解更多的话,可以阅读由麻省理工出版社出版的名声显赫的著作《统计自然语言处理基础(Foundations of statistical natural language processing)》。
2.3.3神经网络
神经网络(Neural Network)与传统的机器学习算法略有不同。虽然其他的机器学习算法都采取基于概率或者统计的方式,神经网络却独辟蹊径,采用了完全不同的方式,它试图模拟人类大脑的结构。人类大脑是由神经元网络组成。看看下图就能得到一个大致的轮廓: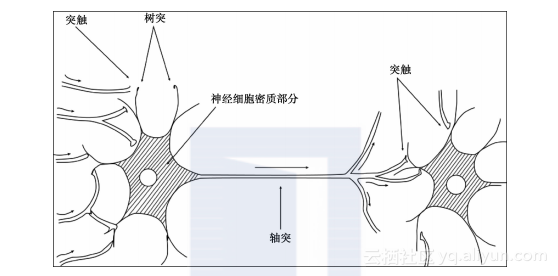
一个神经元通过另一个神经元连接到网络中,它从突触接收电信号的刺激。当电位超过某个阀值,神经元就被激活,将电刺激传送给它网络中连接的下一个神经元。神经网络依据电刺激是如何传递的来对外界进行判定。
神经网络刚出现时是一种监督学习,它以数字表示收到电信号的刺激。最近,尤其是深度学习出现以来,涌现了各种各样的神经网络算法,其中相当一部分是无监督学习。通过在学习中不断调整网络的权重,这些算法提升了它们预测的准确度。深度学习是一种基于神经网络的算法。我们会在后面的内容中详细介绍神经网络的知识,并提供相应的实现。
2.3.4逻辑回归
逻辑回归(Logistic Regression)是变量服从伯努利分布(Bernoulli Distribution)的一种统计回归模型。不同于支持向量机和神经网络都是分类模型,逻辑回归是一种回归模型,不过它也是一种监督学习方法。虽然逻辑回归并不是神经网络,但从数学解释上看,它可以被看作一种神经网络。我们在后面的内容中也会介绍逻辑回归的细节,并提供其实现。
正如你所看到的,每一种机器学习方法都有其独特的特征。依据你想要知道什么或者你希望用你的数据干什么,选择正确的算法是非常重要的。你可以说它们都是深度学习。不过深度学习也有不同的方法,因此,你不仅应该考量到底采用哪一种最适合的方法,还需要考虑是否在某些情况下没有必要使用深度学习。量体裁衣,因地制宜地选择最合适的方法非常重要。
2.3.5增强学习
除此之外,仅供参考的还有另外一种机器学习方法,名叫“增强学习”(Reinforcement Learning)。虽然有的分类方法会把增强学习划分到无监督学习,还有相当一部分的分类方法认为这三种学习算法:监督学习、无监督学习以及增强学习应该被划分为三种独立的算法类型。下图展示了增强学习的基础框架: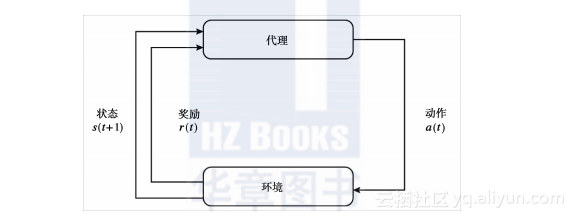
主体依据环境的状态采取相应的动作,环境根据动作呈现相应的变化。系统依据环境的变化为代理提供了一套奖励机制,代理借此可以学习更好的动作抉择(决策)。