Load很高,CPU使用率很低的诡异情况
第一次碰到这种Case:物理机的Load很高,CPU使用率很低
先看CPU、Load情况
如图一:
vmstat显示很有多任务等待排队执行(r)top都能看到Load很高,但是CPU idle 95%以上
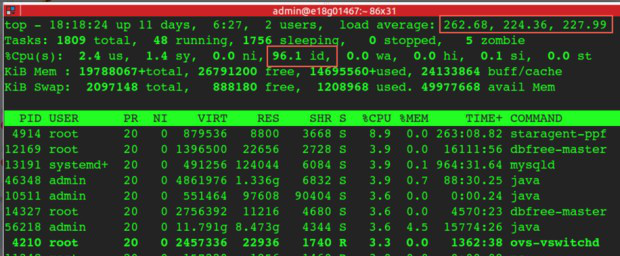
这个现象不太合乎常规,也许是在等磁盘IO、也许在等网络返回会导致CPU利用率很低而Load很高
贴个vmstat 说明文档(图片来源于网络N年了,找不到出处)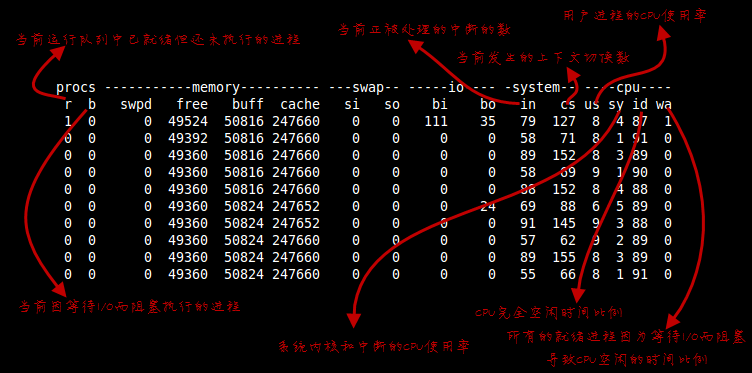
检查磁盘状态,很正常(vmstat 第二列也一直为0)
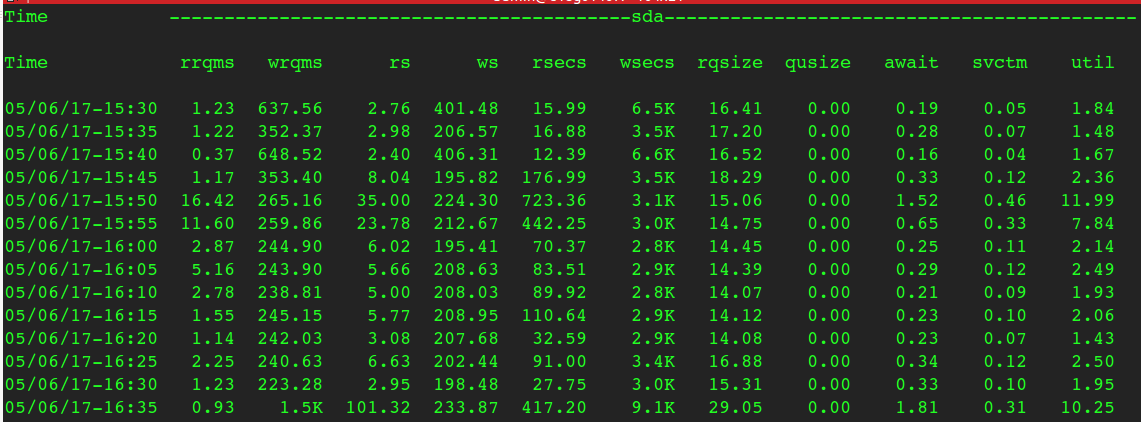
再看Load是在5号下午15:50突然飙起来的:
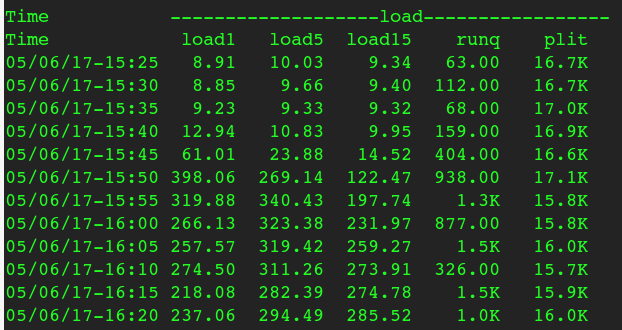
同一时间段的网络流量、TCP连接相关数据很平稳:
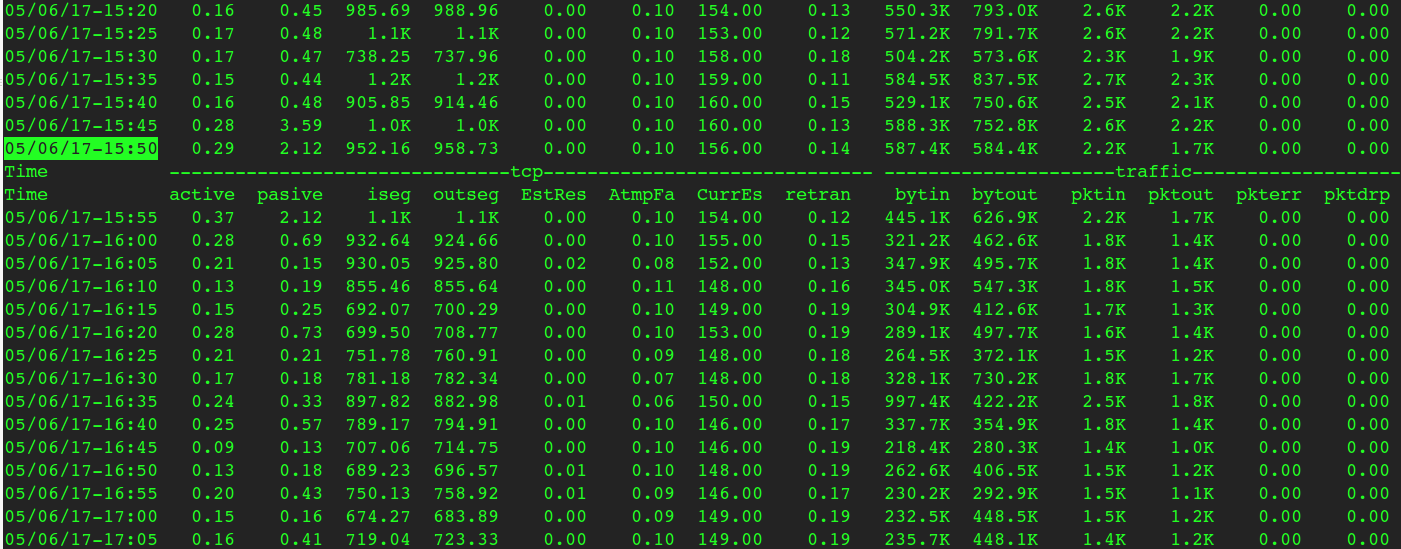
所以分析到此,可以得出:Load高跟磁盘、网络、压力都没啥关系
物理机上是跑的Docker,分析了一下CPUSet情况:

发现基本上所有容器都绑定在CPU1上(感谢 @辺客 发现这个问题)
进而检查top每个核的状态,果然CPU1 的idle一直为0
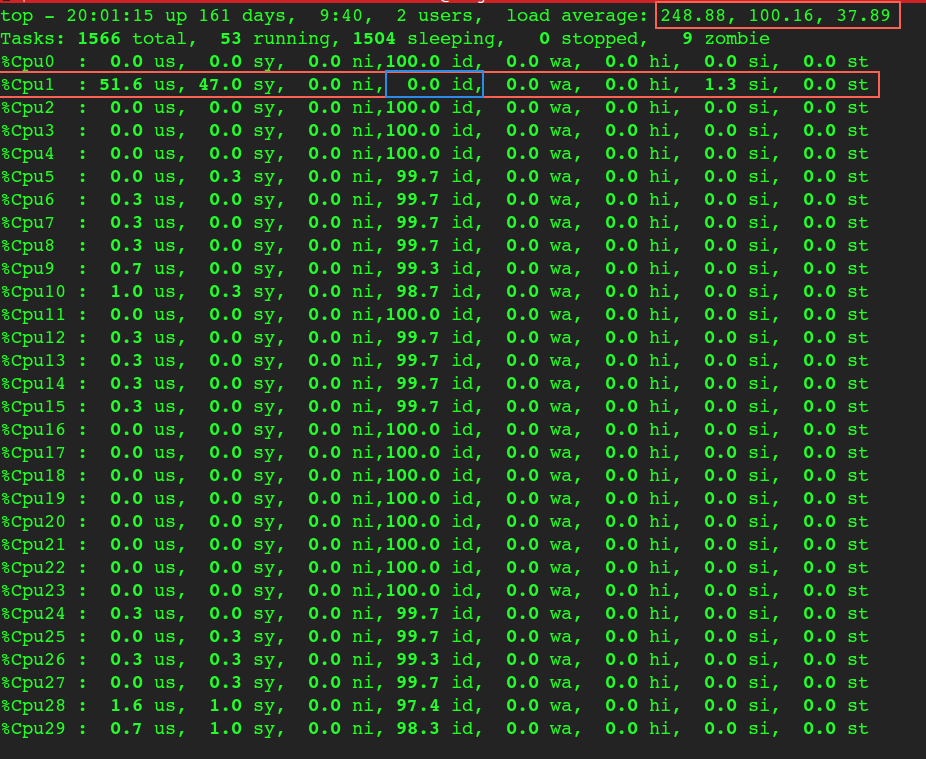
看到这里大致明白了,虽然CPU整体很闲但是因为很多进程都绑定在CPU1上,导致CPU1上排队很长,看前面tsar的--load负载截图的 等待运行进程排队长度(runq)确实也很长。
物理机有32个核,如果100个任务同时进来,Load大概是3,这是正常的。如果这100个任务都跑在CPU1上,Load还是3(因为Load是所有核的平均值)。但是如果有源源不断的100个任务进来,前面100个还没完后面又来了100个,这个时候CPU1前面队列很长,其它31个核没事做,这个时候整体Load就是6了,时间一长很快Load就能到几百。
这是典型的瓶颈导致积压进而高Load。
为什么会出现这种情况
检查Docker系统日志,发现同一时间点所有物理机同时批量执行docker update 把几百个容器都绑定到CPU1上,导致这个核忙死了,其它核闲得要死(所以看到整体CPU不忙,最忙的那个核被平均掩盖掉了),但是Load高(CPU1上排队太长,即使平均到32个核,这个队列还是长,这就是瓶颈啊)。
如下Docker日志,Load飙升的那个时间点有人批量调docker update 把所有容器都绑定到CPU1上:
检查Docker集群Swarm的日志,发现Swarm没有发起这样的update操作,似乎是每个Docker Daemon自己的行为,谁触发了这个CPU的绑定过程的原因还没找到,求指点。
手动执行docker update, 把容器打散到不同的cpu核上,恢复正常:

总结
- 技术拓展商业边界,同样技能、熟练能力能拓展解决问题的能力。 开始我注意到了Swarm集群显示的CPU绑定过多,同时也发现有些容器绑定在CPU1上。所以我尝试通过API: GET /containers/json 拿到了所有容器的参数,然后搜索里面的CPUSet,结果这个API返回来的参数不包含CPUSet,那我只能挨个 GET /containers/id/json, 要写个循环,偷懒没写,所以没发现这个问题。
- 这种多个进程绑定到同一个核然后导致Load过高的情况确实很少见,也算是个教训
- 自己观察top 单核的时候不够仔细,只是看到CPU1 的US 60%,没留意idle,同时以为这个60%就是偶尔一个进程在跑,耐心不够(主要也是没意识到这种极端情况,疏忽了)