1.4 支持窗口函数的查询元素
T-SQL性能调优秘笈——基于SQL Server 2012 窗口函数
并不是所有的查询子句都支持窗口函数,相反,仅仅SELECT和ORDER BY子句支持窗口函数。为了帮助大家理解这个约束的原因,我首先要解释查询逻辑处理的概念。然后,我会介绍支持窗口函数的子句,最后,解释如何在其他子句中避开约束。
1.4.1 查询逻辑处理
查询逻辑处理从概念性的角度描述SELECT查询是如何根据逻辑语言的设计进行判断的。它描述了怎样由查询的输入表,经由一系列步骤和阶段,直到查询的最终结果的过程。注意我的用词“查询逻辑处理”,我指的是查询判断的概念性方式——不一定是SQL Server处理查询的物理方式。作为优化的一部分,SQL Server会走捷径,会重新安排某些步骤的顺序,及使用它认为有助性能提高的其他手段。但前提是,它确定会按照查询逻辑处理在查询请求上的规则,提供正确的输出。
查询逻辑处理对作为输入的一张或多张表(行集)进行处理,输出返回一张表,上一个步骤的输出即成为下一个步骤的输入。
图1-6是一个流程图,显示SQL Server 2012的查询逻辑处理流程。
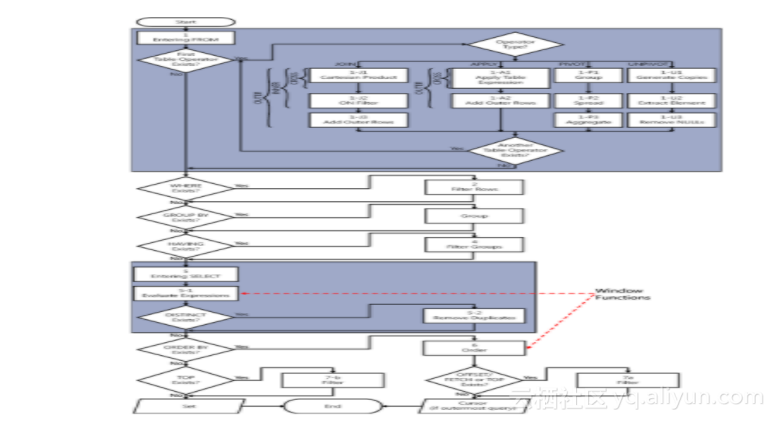
请注意,当编写查询语句时,在输入顺序上,SELECT子句是最早输入的,但观察查询的逻辑处理顺序,它几乎是最后处理的——仅仅排在ORDER BY子句的前面。
关于查询逻辑处理,还有很多可以提及的内容,但本书就不涉及这些内容了。为了便于本书后续内容的讨论,记住不同的子句的判断顺序很重要,顺序如下(粗体表示允许窗口函数出现的阶段):
1. FROM
2. WHERE
3. GROUP BY
4. HAVING
5. SELECT
5-1.Evalute Expressions(判断表达式)
5-2.删除重复数据
6. ORDER BY
7. OFFSET-FETCH/TOP
理解查询的逻辑处理以及逻辑处理顺序,就使我们明白了窗口函数只能出现在特定子句中这个限制的背后动机。
1.4.2 支持窗口函数的子句
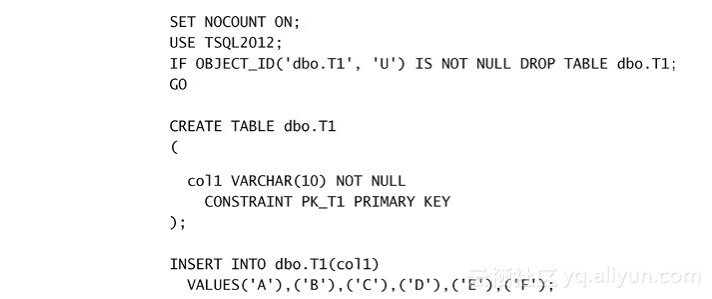
如图1-6所示,只有SELECT和ORDER BY子句直接支持窗口函数。做这个限制的原因是为了避免二义性,因此把(几乎是)查询的最终结果当作窗口的起点。如果窗口函数可以早于SELECT阶段出现,那么通过一些查询表单会无法得到正确的结果。我通过一个示例来展示这种二义性问题。首先运行下面的代码创建表T1,并在其中填入样本数据:
假定窗口函数可以出现在SELECT阶段之前——例如,在WHERE阶段。那么看看下面的查询,试着找出结果中col1的值:

在我们认为答案显而易见是C、D、E前,请考虑一下SQL中的同时发生概念。同时发生概念指的是,从概念上来说,同一个逻辑阶段里的所有表达式是同时判断的,这就意味着,顺序对表达式的判断并不重要。按照这个思路,从语义上来说,下面的查询与上面的查询是一样的:

现在,我们找到的正确答案是什么?是C、D、E,还是仅仅是C?
这就是我说的二义性示例。通过限制窗口函数,使其只出现在SELECT和ORDER BY查询子句中,就排除了这种二义性。
观察图1-6,我们会注意到,在SELECT阶段,步骤5-1(判断表达式)支持窗口函数,这一步骤在5-2(去重)之前进行。了解其中的微妙之处很重要,我会阐述为什么。
下面的查询从员工表中返回所有员工的empid和country特性: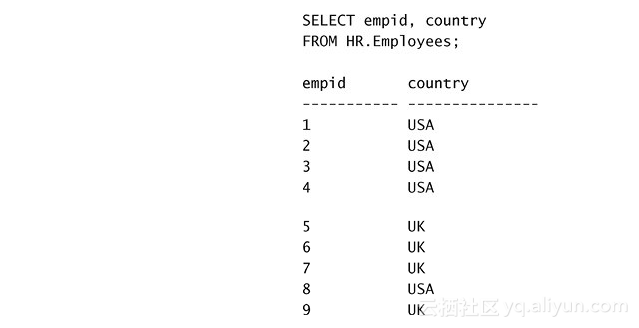
下一步,检查下面的查询,试着在执行查询前,猜一猜输出结果:
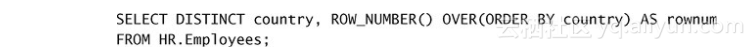
有些人以为会得到这样的输出:

实际上,输出如下所示:
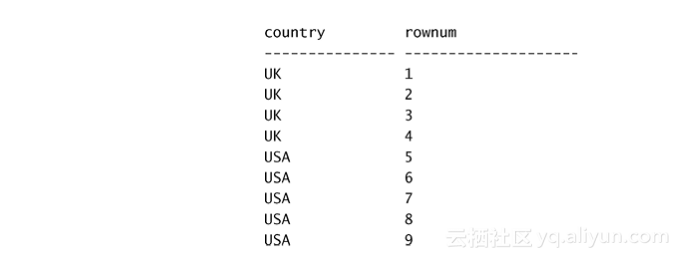
现在考虑一下:查询中的ROW_NUMBER函数和SELECT列表表达式都是在步骤5-1中判断——早于步骤5-2中的删除重复数据。ROW_NUMBER函数分配了9个行号给9个员工行,因此DISTINCT子句发现没有重复记录可以删除。
当我们认识到这一点并理解了查询逻辑处理对不同的元素的处理顺序时,我们就可以想出解决方案。例如,可以基于查询定义一个表表达式,仅仅返回不同的国家,在删除重复数据完成后,用外部查询分配行号,如下所示:

现在,大家可以想想用其他方法来解答问题,是否还有比上面更简单的方法?
窗口函数在SELECT或ORDER BY阶段判断,实际上意味着为计算定义的窗口,在应用进一步的约束之前,是前面阶段完成后查询的行的中间形式,即应用了所有的表操作符(如,联接)的FROM之后,在WHERE筛选之后,在分组和分组筛选之后。以下面的查询作为示例: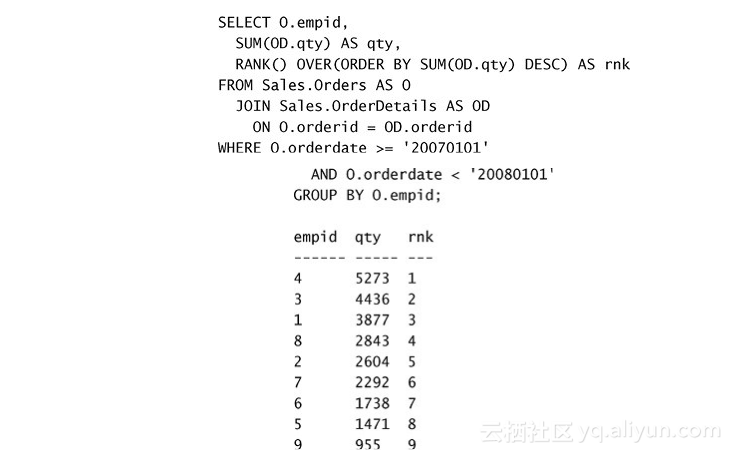
首先判断FROM子句,进行表的联接。随后筛选了2007年的订单,这些选中的订单按照员工号进行分组。直到这时,才判断SELECT列表中的表达式,包括RANK函数,它基于合计销量按降序进行计算。如果SELECT列表中有其他窗口函数,它们会使用同样的结果集作为起始点。现在回想对于窗口函数替代方案的讨论(例如,子查询),其数据开始点是从头开始的——意味着对于外部查询中的设定逻辑,我们必须在每个内部查询中重复设定一遍,导致代码冗长很多。
1.4.3 避开限制
前面解释了查询逻辑处理的各个阶段中,不允许窗口函数的判断早于SELECT子句的原因。但如果我们需要根据窗口函数的计算结果进行筛选或分组该怎么办?解决方法是使用像CTE那样的表表达式或派生表。在一个查询的SELECT列表中调用窗口函数,给计算分配一个别名,根据这个查询定义一个表表达式,当需要时,就可让外部查询指向这个别名。
下面的示例展示如何用一个CTE来筛选窗口函数的结果:
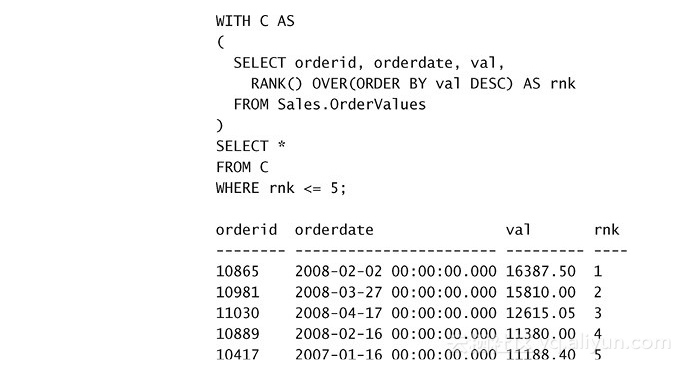
在修改语句中,窗口函数不能出现,因为修改语句不支持SELECT和ORDER BY子句。但在某些情况下,需要在修改的语句中使用窗口函数。用表表达式也可以满足这个需求,因为T-SQL支持通过表表达式修改数据。我用一个UPDATE示例来演示其能力。首先,运行下面的代码创建一个叫T1的表,其中有col1和col2两列,然后填充一些样品数据:

这里给col2中提供了明确的值,col1的值就是默认的NULL。
假设这个表代表一种数据质量有问题的情形。表中没有强制实现键,因此无法对各行进行唯一性识别,我们需要对所有行的col1指定唯一值,考虑在UPDATE语句中使用ROW_NUMBER函数,如下所示:

但回想一下,这是不允许的。变通方案是在T1上写一个查询,返回col1和一个基于ROW_NUMBER函数的表达式(把它称为rownum),基于这个查询定义一个表达式;最后,在CTE上用一个外部UPDATE语句,把rownum值赋给col1,如下所示:

查询T1,我们可以看到所有行的col1都有唯一值。

本文仅用于学习和交流目的,不代表异步社区观点。非商业转载请注明作译者、出处,并保留本文的原始链接。