一,前面的话
表和列的统计信息对CBO的结果有着极大地影响,能够高效和准确的收集统计信息是极其重要的。但高效和准确是矛盾的,更准确的统计信息往往需要更多的计算,我们能做的是在高效和准确之间找到更好的平衡。接下来的内容是关于目前在ComputeColStats中用的一些近似算法。
二,收集的内容
目前针对列主要会收集以下统计信息:
cntRows : 列中总数据个数,包括nulll值
avgColLen :列的平均长度
maxColLEN :列的最大长度
minValue :列的最小值
maxValue :列的最大值
numNulls :列中null值个数
numFalses :如果boolean型,false值的个数
numTrues :如果boolean型,true值的个数
countDistinct :不同值的个数
topK :topk值的个数,数据倾斜的标志
一般说来除了countDistinct 和topK 以外的统计信息基本上消耗资源并不大(minValue和maxValue存在大量比较,也会消耗不少资源),问题主要集中在countDistinct 和topK上。下面要描述的近似算法也是主要针对这两个点。
三,countDistinct 实现
算法:Flajolet-Martin
论文见:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.81.3869&rep=rep1&type=pdf
简介
对于n个object,如果Hash结果中,结尾(或开头)连续0的长度的最大值是m,那么,可以估计唯一的object的数据量是2^m个。
假设有一个非常好的hash函数,能够将object哈希成一个二进制数0101……,并且非常均匀的打散到二进制空间。如果有8个唯一的object,将它们全部Hash之后,结果按照概率应该有4个object的Hash值以0结尾,这4个Hash值又应该有2个结尾是00,这2个中又有1个结尾是000。
采用多个独立的hash函数,每个hash函数分别计算最长0比特序列,然后求平均值,减少误差。
hash函数的个数基本上就决定了Flajolet-Martin算法的效率和准确度,后面有针对不同hash函数个数的测试结果。
四,topK实现
算法:Space-Saving
伪代码: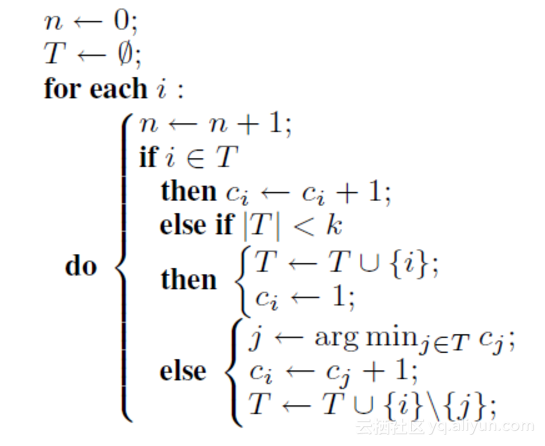
五,基本性能测试

结论:
1,Base Stats对性能也是存在影响的,主要是minValue和maxValue的计算,尤其是collen较长的情况下
2,一般说来distinct相对topK会更慢些,除非在collen较长的时候,topK也是基于比较来的
3,随着列个数的增加,收集stats消耗的时间也线性的增加
4,distinct的计算基于hash,而topK的计算基于比较,所以前者对collen并不敏感
六,不同hash函数个数执行效率的测试

结论:
基本上随着hash函数个数的增加线性的增长
七,不同hash函数个数准确性的测试
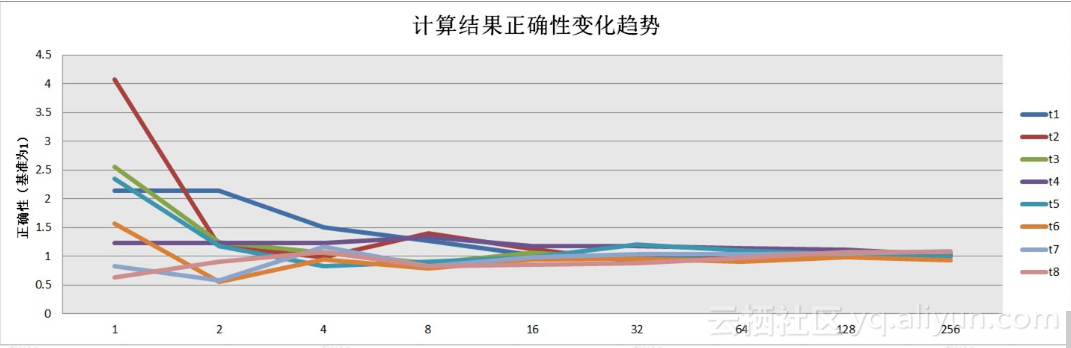
结论:
hash函数个数增加到32个后,准确率基本能满足需求
八,不同hash函数个数的测试总结

结论:选择32个hash函数计算distinct,平衡执行效率及准确性
九,sample算法的选择
1,必要性:
基于前面对执行效率的测试,为了避免对任务产生过大的影响,Sample是一定要做的
2,Sample算法的要求:
效率,随机
3,Sample的选择:
采用buildin的sample函数实现
前提是假设数据分布是随机的
4,Sample的影响:
对某些stats基本没影响,比如说avgColLen,maxColLen,minValue,maxValue
对某些stats有些影响,比如说cntRows, numNulls,numFalses,numTrues,topK
对countDistinct影响比较大,并且countDistinct也更加重要,需要特别注意
5,Sample后countDistinct的处理:
根据Sample的countDistinct预测完整数据的countDistinct,采样,拟合
基本思路如下图: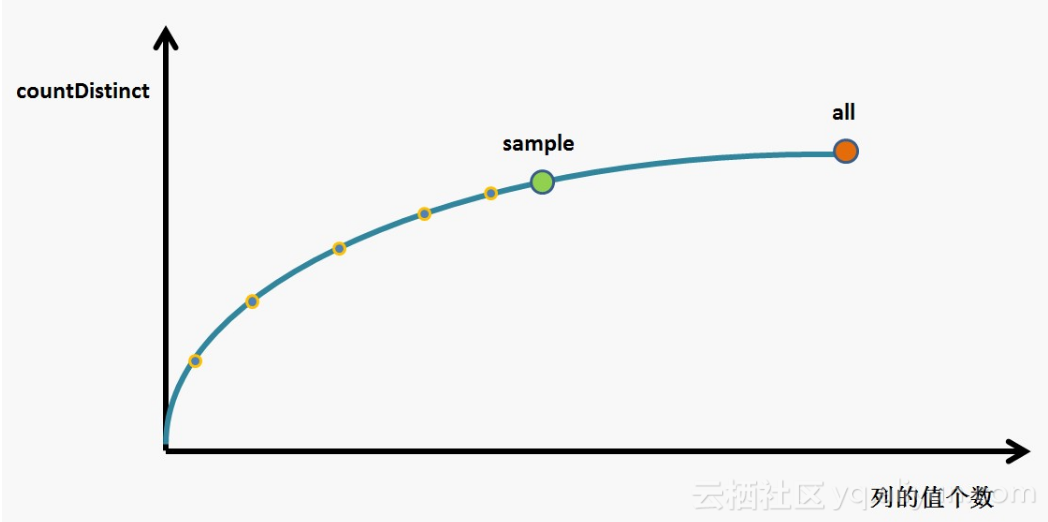
希望通过对sample内的数据进行采样,利用这些采样点描绘全部数据的形态,达到基本准确预测全部数据distinct的结果。这是个美好的愿望,在sample的数据相对较少的时候,总有些情况下sample下的形态跟完整数据的形态存在较大的差异,此时的误差会比较大。
十,不同sample比例执行效率的测试
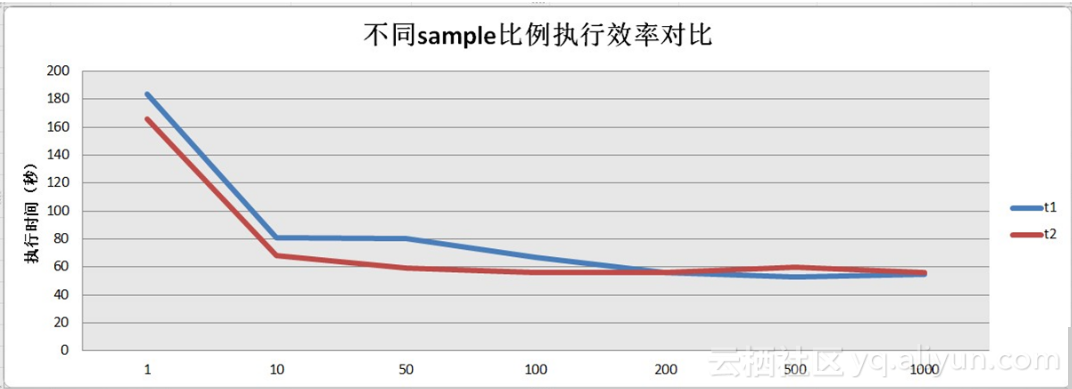
采样比例在1/100后执行时间差距不大,此时最大的消耗在数据读取上,而不针对distinct的计算。
十一,不同sample比例准确性的测试
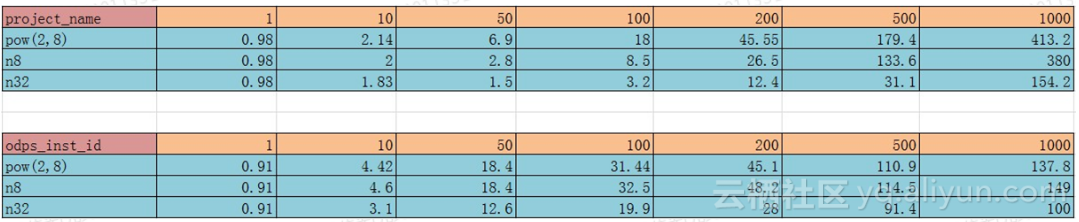
针对表meta.m_fuxi_instance表中的列project_name,odps_inst_id做了些测试,结果如上。看起来1/50的结果还是可以接受的。
多说一句,对于distinct来说,并不需要完全的正确,10倍以内的差距目前来说是可以接受的,这也是我们可以通过采样来提高效率的前提。
十二,按sample比例为1/25为例的计算结果
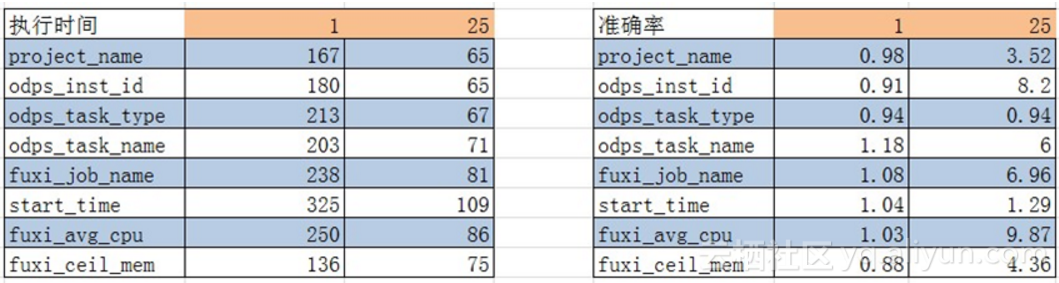
执行时间和准确率基本都可以满足现在需求
十三,后续的工作
对于准确率的提升是后续需要做的事情之一,这关键还是如何在sample里面找带更有代表性的点来预测全部数据的形态。但,要作好心理准备,对于某些场景来说,可能就找不到这样的方法,需要接受一定范围的误差。