在SQL
SERVER的查询语句中使用OR是否会导致不走索引查找(Index Seek)或索引失效(堆表走全表扫描 (Table
Scan)、聚集索引表走聚集索引扫描(Clustered Index Scan))呢?是否所有情况都是如此?又该如何优化呢?
下面我们通过一些简单的例子来分析理解这些现象。下面的实验环境为SQL SERVER 2008,如果在不同版本有所区别,欢迎指正。
堆表单索引
首先我们构建我们测试需要实验环境,具体情况如下所示:
DROP TABLE TEST
CREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(32));
CREATE INDEX PK_TEST ON TEST(OBJECT_ID)
DECLARE @Index INT =0;
WHILE @Index < 500000
BEGIN
INSERT INTO TEST
SELECT @Index, 'kerry'+CAST(@Index AS VARCHAR(6));
SET @Index = @Index +1;
END
UPDATE STATISTICS TEST WITH FULLSCAN
场景1:如下所示,并不是所有的OR条件都会导致SQL走全表扫描。具体情况具体分析,不要套用教条。
SELECT * FROM TEST WHERE (OBJECT_ID =5 OR OBJECT_ID = 105)

场景2:加
了条件1=1后,执行计划从索引查找(Index Seek)变为全表扫描(Table
Scan),为什么会如此呢?个人理解为优化器将OR运算拆分为两个子集处理,由于一些原因,1=1这个条件导致优化器认定需要全表扫描才能完成1=1条
件子集的计算处理(为了理解这个,煞费苦心,鉴于理论薄弱,如有错误或不足,敬请指出)。所以优化器在权衡代价后生成的执行计划最终选择了全表扫描
(Table Scan)
SELECT * FROM TEST WHERE (1=1 OR OBJECT_ID =105);

场景3: 下面场景比较好理解,因为下面需要从500000条记录中取出499700条记录,而全表扫描(Table Scan)肯定是最优的选择,代价(Cost)最低。
SELECT * FROM TEST WHERE (OBJECT_ID >300 OR OBJECT_ID =105);
场景4:这种场景跟场景2的情况本质是一样的。所以在此略过。其实类似这种写法也是实际情况中最常出现的情况,还在迷糊的同学,赶紧抛弃这种写法吧
DECLARE @OBJECT_ID INT =150;
SELECT * FROM TEST WHERE (@OBJECT_ID IS NULL OR OBJECT_ID =@OBJECT_ID);

聚集索引表单索引
在聚集索引表中,我们也依葫芦画瓢,准备实验测试的数据环境。
DROP TABLE TEST
CREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(32));
CREATE CLUSTERED INDEX PK_TEST ON TEST(OBJECT_ID)
DECLARE @Index INT =0;
WHILE @Index < 500000
BEGIN
INSERT INTO TEST
SELECT @Index, 'kerry'+CAST(@Index AS VARCHAR(6));
SET @Index = @Index +1;
END
UPDATE STATISTICS TEST WITH FULLSCAN
场景1 :索引查找(Index Seek)
SELECT * FROM TEST WHERE (OBJECT_ID =5 OR OBJECT_ID = 105)
场景2:聚集索引扫描(Clustered Index Scan)

场景3:似乎与堆表有所不同。聚集索引表居然还是走聚集索引查找。

场景4:OR导致聚集索引扫描

如果堆表或聚集索引表上建立有联合索引,情况也大致如此,在此不做过多案例讲解。下面仅仅讲述一两个案例场景。
DROP TABLE test1;
CREATE TABLE test1
(
a INT,
b INT,
c INT,
d INT,
e INT
)
DECLARE @Index INT =0;
WHILE @Index < 10000
BEGIN
INSERT INTO test1
SELECT @Index,
@Index,
@Index,
@Index,
@Index
SET @Index = @Index + 1;
END
CREATE INDEX idx_test_n1
ON test1(a, b, c, d)
UPDATE STATISTICS test1 WITH fullscan;
SELECT * FROM TEST1 WHERE A=12 OR B> 500 OR C >100000
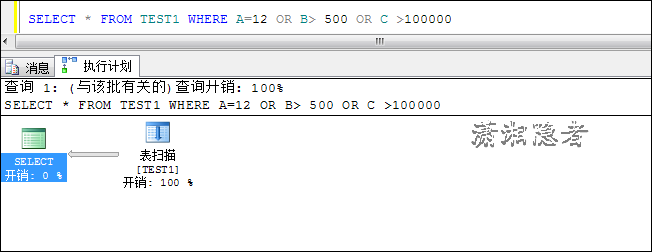
因为结果集是几个条件的并集,最多只能在查找A=12的数据时用索引,其它几个条件都需要表扫描,那优化器就会选择直接走一遍表扫描,以最低的代价COST完成,所以索引就失效了。
那么如何优化查询语句含有的OR的SQL语句呢?方法无外乎有三种:
1:通过索引覆盖,使包含OR的SQL走索引查找(Index Seek)。但是这个只能满足部分场景,并不能解决所有这类SQL。这个Solution具有一定的局限性。
SELECT * FROM TEST1 WHERE A=12 OR B=500

如果我们通过索引覆盖,在字段B上面也建立索引,那么下面OR查询也会走索引查找。
CREATE INDEX IDX_TEST1_B ON TEST1(B);
SELECT * FROM TEST1 WHERE A=12 OR B=500

2:使用IN替换OR。 但是这个Solution也有很多局限性。在此不做过多阐述。
3:
一般将OR的字句分解成多个查询,并且通过UNION ALL 或UNION连接起来。在联合索引或有索引覆盖的场景下。大部分情况下,UNION
ALL的效率更高。但是并不是所有的UNION ALL都会比OR的SQL的代价(COST),特殊的情况或特殊的数据分布也会出现UNION
ALL比OR代价要高的情况。例如,上面特殊的要求,从全表中取两条记录,如下所示
SELECT * FROM TEST1 WHERE A=12
UNION ALL
SELECT * FROM TEST1 WHERE B=500

UNON
ALL语句的代价(Cost)要高与OR是因为它做了两次索引查找(Index Seek),而OR语句只做一次索引查找(Index
Seek)就完成了。开销明显小一些,但是实际情况这类特殊情况比较少,实际情况的取数条件、数据都比这个简单案例要复杂得多。所以在大部分情况下,拆分
为UNION ALL语句的效率要高于OR语句
另外一个案例,就是最上面实验的堆表TEST, 在字段OBJECT_ID上建有索引
SELECT * FROM TEST WHERE (OBJECT_ID >300 OR OBJECT_ID =105);
SELECT * FROM TEST WHERE OBJECT_ID >300
UNION ALL
SELECT * FROM TEST WHERE OBJECT_ID =105;

可以从下面看出两者开销不同的地方在于IO方面,两者开销之所以有区别,是因为第二个SQL多了一次扫描(索引查找)


总结:
在实际开发环境中,OR这种写法确实会带来很多不确定性,尽量使用UNION 或IN替换OR。我们需要遵循一些规则,但是也不能认为它就是一成不变的,永为真理。具体场景、具体环境具体分析。要知其然知其所以然。在微软亚太区数据库技术支持组的官方博客中就有一个案例SQL Server性能问题案例解析 (3)也是OR引起的性能案例。 博客中有个观点,我觉得挺赞的:”需要注意的是,对于OR或UNION,并没有确定的孰优孰劣,使用时要进行测试才能确定。“ 。