
Introduction
A real-time system is a system that processes input data within milliseconds so that the processed data is available almost immediately for feedback. Real-timeliness in the video recommendation system is mainly reflected in three layers:
- Real-Time Construction of Short-Term Interest Models in the User's Profile: After a user finishes a video, the video content will influence the user's short-term interest model for a few seconds. The recommended video reflects this embodied influence.
- Real-Time Changes of Candidate Sets: In this recommendation system, the definition of the candidate sets is the recommendation of different types of video libraries for the user. A user cannot view all the candidate sets but can view only a part of the candidate set after the matching algorithm processes the candidate sets. The update interval of the candidate set directly affects the real-timeliness of videos that the user can see. Several candidate sets exist, each tailored for different scenarios. For example, by combining the latest candidate set and the most popular candidate set in the past N hours, we can achieve a recommendation effect similar to that of toutiao.com. The generation of new content candidate sets is in real time, while the popular video candidate set in the past N hours may be updated every several minutes. As another example, synergy can achieve the recommendation of related videos, which can further shortlist the user-favorite content from popular candidate sets that attract the common interest of users.
- Real-Time Presentation of Recommendation Performance Metrics: After the product is online, key metrics such as the click conversion rate can be updated once every several minutes. The recommendation system has a special feature in which the performance is not measured by subjective opinions but by specific metrics, such as the click conversion rate.
User Profiles and Video Profiles
Reflection of user profiles in the interest model is a common occurrence. By building users' long-term and short-term interest models, businesses can satisfy users' interests and demands. There are various ways to provide recommendations, such as synergy and a variety of small tricks. However, user profile-based and video profile-based recommendations are difficult in the initial phase. In the long run, these user profiles can promote the team's understanding of users' video consumption habits and support businesses other than recommendations.
Asynchronous
A user's refresh actions triggers the recommendation calculation. Once refreshed, the user information is sent to Kafka asynchronously, and the Spark Streaming program will analyze the data and match candidate sets with users. The user's private queue in Redis receives the calculation result. The interface service is only responsible for getting the recommendation data and sending the user refresh actions. The private queue of a new user or a user who has not accessed the service in a long time may have expired. In this case, the asynchronous operation will cause problems. Once the front-end interface discovers this issue, it will perform one of the following actions to resolve the problem:
- Sends a special message (the backend connects to a Storm cluster) and then holds the session, waiting for the asynchronous calculation result.
- Obtains the user interest tags and tries to determine the synergy according to certain rules. Then it searches for the data in ES, populates the data onto the private queue, and quickly provides the result (the solution we are adopting).
Asynchronous calculation covers most of the calculations, except for new users.
Impact of Streaming Technologies on Recommendation System
In 2014, the concept of stream computing concept did not exist and the reuse of existing technical system was not possible. As a result, our recommendation system was overly complicated and difficult to be productized. To make matters worse, the recommendation effects were only visible the next day, resulting in a prolonged cycle of effect improvement. During that time, the entire development cycle exceeded one month.
On the contrary, today's system based on StreamingPro has two or three developers, each investing only two to three hours a day. The developers can complete the entire development within just two weeks. Stream computing has had a large impact on the approach and implementation of the recommendation system.
The recommendation system includes all other computing-related features, except interface services. However, the features are not limited to:
- New content pre-processing, such as tagging and storage into multiple stores
- User profile construction, such as short-term interest model
- New and popular data candidate sets
- Short-term synergy
- Recommendation performance metrics, such as click conversion rate
All these processes are completed using "Spark Streaming." For long-term synergy (data of more than one day) and the user's long-term interest models among others, Spark batch processing is adopted. Thanks to the utilization of the StreamingPro project, all the calculation processes can be configured. You will see a list of description files that constitute the core computing processes of the entire recommendation system.
We would like to mention three points here, which are as follows:
- Recommendation Effect Evaluation: We use the Spark Streaming + ElasticSearch solution. That is, Spark Streaming pre-processes the reported exposure click data and stores the data to ES. Then ES provides the query interface for the BI report to use. This avoids pre-calculation of metrics, which may result in frequent changes of the streaming computing procedures because it does not consider the implementation of many metrics.
- Reuse of Existing Big Data Infrastructure: Throughout the entire recommendation system, only the provision of API services requires a separate deployment and all other calculations run on the Hadoop cluster using Spark.
- Adjustment of Calculation Cycles: All calculation cycles and computing resources can be adjusted conveniently or even dynamically (Spark Dynamic Resource Allocation). This is vital because it allows us to sacrifice specific real-timeliness to save resources or spare more resources for offline tasks.
Recommendation System Architecture
The figure below shows the structure of the entire recommendation system:
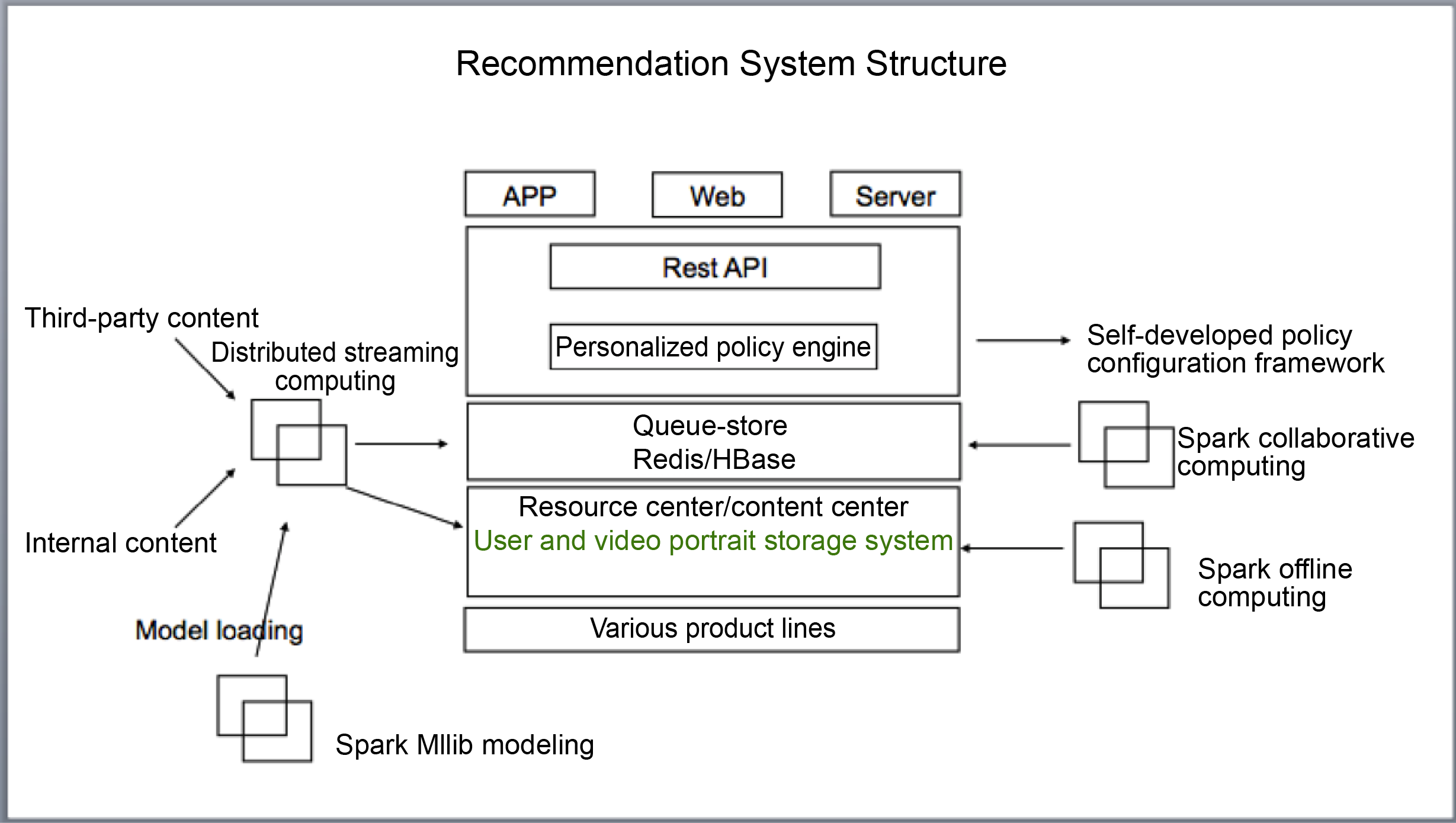
Figure 1. Recommendation System Structure
Distributed streaming computing is mainly responsible for five sections:
- Processing of clicks, exposures, and other reported data
- New video tagging
- Short-term interest model calculation
- User recommendation
- Calculation of candidate sets, such as the latest, the most popular sets (during any time period)
The storage solutions include:
1. Codis (user recommendation list)
2. HBase (user profile and video profile)
3. Parquet (HDFS) (archived data)
4. ElasticSearch (copy of HBase)
The following figure shows more details about the streaming computing section:
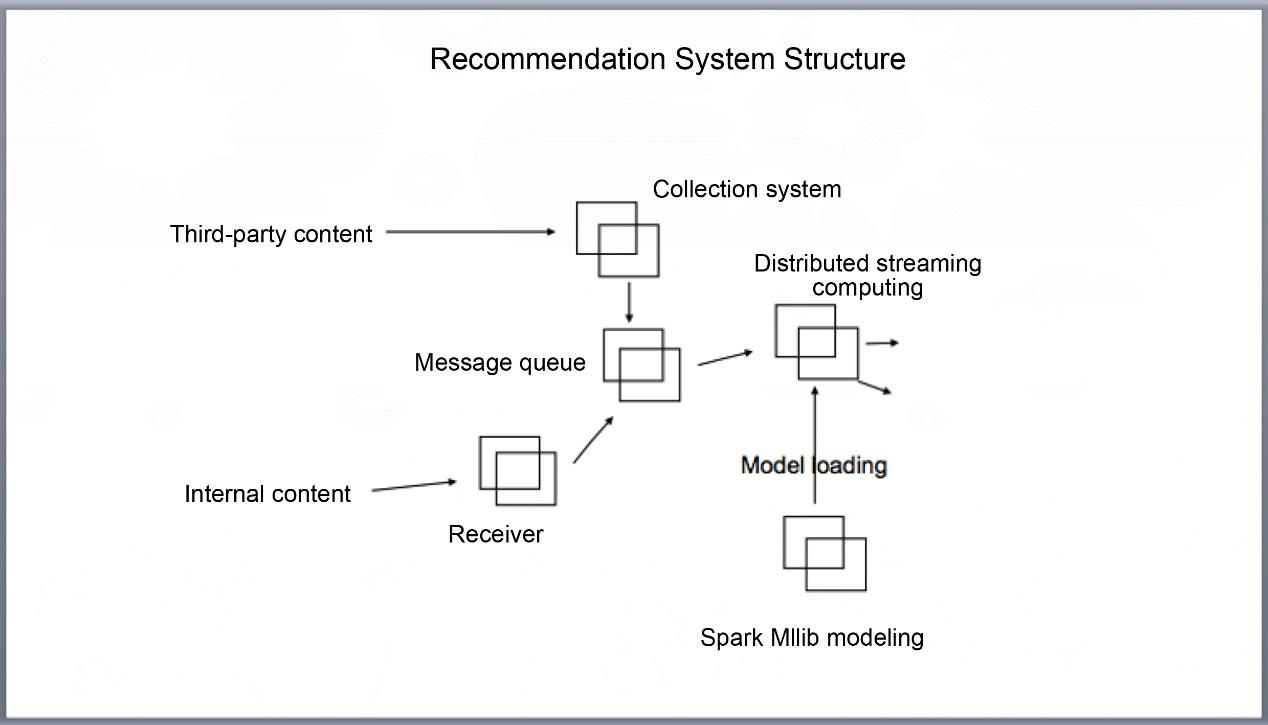
Figure 2. Detailed Recommendation System Structure
Technical solutions adopted for user reporting:
- nginx
- Flume (Collect nginx logs)
- Kafka (Receive Flume reports)
For third-party content (full-site), we developed a collection system on our own.
Personalized Recommendation
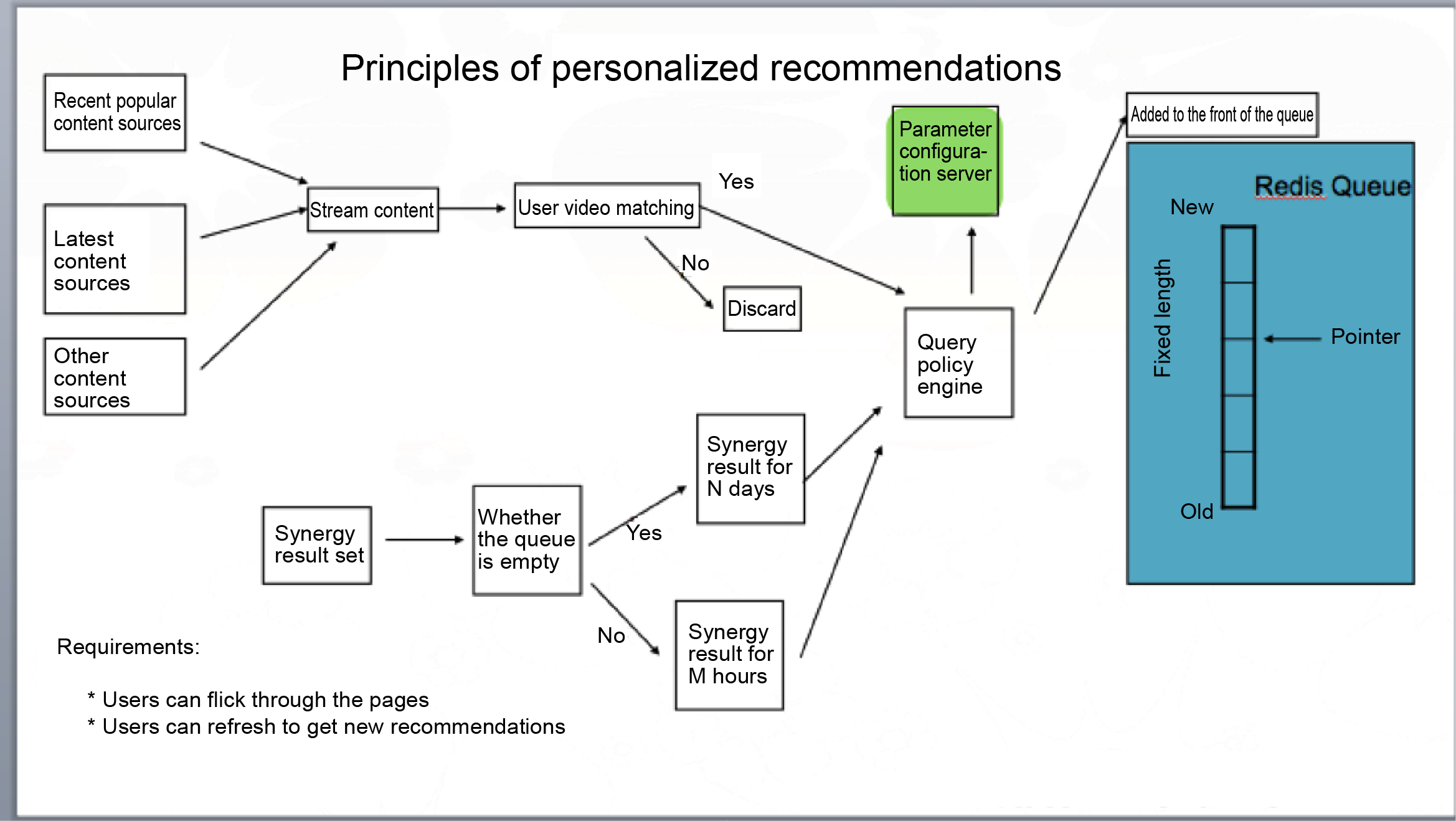
Figure 3. Principles of Personalized Recommendations
The recommendation system updates all candidate sets in real time.
The concept of parameter configuration servers can be understood as follows.
Suppose, we have two algorithms A and B, each of which are completed by independent streaming programs. Each program calculates its result set. The content data size and frequency calculated by different candidate sets and algorithms vary. Let us assume that the result set from A is too large, while that from B is small but of excellent quality. In this case, when the recommendation queue of a user receives algorithms A and B, the algorithms submit their own situations to the parameter configuration server. These algorithms will determine the final amount to be sent to the queue. The parameter server can likewise control the corresponding frequency. For example, if algorithm A generates a new recommendation in just 10 seconds after the last recommendation result, the parameter server can refuse to write its content to the recommendation queue of the user.
The above-mentioned case is a multi-algorithm process control. However, there is an alternate approach to this process. We can introduce a new algorithm, K, by blending the results from A and B. Since every algorithm is a configurable module in StreamingPro, A, B, and K will be put into a Spark Streaming application now. K can periodically call A and B for calculation and mix the results, and finally, write the result to the recommendation queue of the user as authorized by the parameter configuration server.
Conclusion
This article explores the usage of stream computing for the personalized video recommendation system. In this approach, a tag system is designed and then applied users and videos. Multiple algorithms, including LDA and Bayesian, are combined to gain a wholesome and useful experience.