对于AIX系统工程师来说,LVM是无论如何都无法避免的区域,VG镜像、存储迁移、IO调优,存储故障处理各个方面都有LVM的影子。每当我们在这些方面遇到难题时,其实都是直接或间接的和LVM战斗。
以下是一些LVM知识、常见问题及其解决方法和注意事项,掌握这些内容,必将提高你的LVM战斗力!
1. 基本概念
LVM内置在AIX系统中,随着AIX版本的更新而更新。不管是功能性还是扩展性都在逐步发展。我们在日常的工作中,一定结合自己的实际情况做好规划再使用,避免由于LVM本身的限制带来后期维护和扩展的困难。

典型问题:
1. lvm里关于VG三种选项有何差异,在实际使用中有何种不同体现,优缺点在哪里?
2. chvg -t factor各个因子分别代表什么?
3. AIX上卷组里关于quorum这个值的作用和意义?
解答以上问题,需要具备下知识
AIX LVM支持3种类型的VG,分别是normal VG,Big VG和Scalable VG,如下表所示:
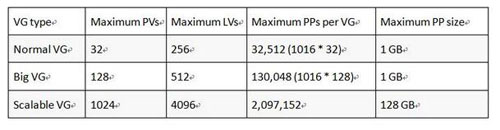
这三种VG最重要的区别就是在扩展性上的支持有很大差异。
normal VG扩展性最小,Big VG次之、Scalable VG扩展性最好。
这三种类型的vg是随着AIX版本的更新逐步推出的。如果在早期的项目实施中使用了normal vg,后续还有陆续扩容的需求,可能就会超出normal vg的自身限制,造成扩容失败的后果。此时又两个解决方法:
1. 升级到其他VG类型获取更高的扩展性:
Chvg–B xxvg 升级到big vg,可以在线升级
Chvg–G xxvg升级到scalable vg,需要先执行varyoffvg命令才能升级
两者都需要pv中有足够的空间来承载vgda信息的变更。
2. 更改factor因子。实际是通过更改pp限制来实现,由factor来指定。更改实际上是在pp数支持和pv支持数量上做一个平衡。如:
Chvg–t 2 xxvg
除了容量和扩展性的差别。在创建裸设备时,使用scalable vg创建的裸设备lv默认不带4k偏移,big vg加 -T -O参数可以不带4k偏移,普通vg不行。不过现在用裸设备的不多了,可以忽略。
卷组的quorum 是由有效的VGDA(卷组描述区)构成的。一个卷组中至少有2个 VGDA 区,每个物理卷上都至少有一个VGDA。VGDA 中记录了卷组中所包含逻辑卷和物理卷的状态和描述信息。 当卷组中只有一个物理卷时,该物理卷上就会存在2个VGDA区; 当卷组中有两个物理卷上时,其中一块物理卷上有2个VGDA ,另一物理卷上有1个VGDA; 当卷组由在3个以上(>=3)的物理卷组成时,每个物理卷上都会有1个VGDA。 当quorum的值设置为on时,quorum丢失会导致卷组关闭,防止进一步的操作造成数据丢失。
2.故障排错
在LVM的使用中,经常遇到各种故障。有的是理论知识不足,有的是细节有待完善。PVID、VGDA、VGSA、ODM、exportvg、recreatevg等等,我们需要梳理LVM的结构和相关术语,这样才能在故障排错中得心应手。
典型问题:
1. odmvgda混乱时,该如何下手?
2. lg_dumplv报too small,增加后很快又空间不足,能否忽略该问题?
3. vg信息与ODM同步问题?
4. AIX PV 出现missing和remove的状态原因和相应的解决办法探讨?
5. VG中添加PV失败?
解答以上问题,需要具备下知识
AIX中LVM的信息同时存放在硬盘和ODM里,硬盘里的表现为VGDA、VGSA等。当磁盘指定为pv(如执行mkdev)时,vgda被分配。当pv加入vg时,vgda内被写入信息。Aix对磁盘的识别以PVID为准。在正常情况下,硬盘上的信息和ODM里的信息应该是一致的。我们平时所做的操作如lspv、lsvg等命令,实际上是从ODM读取的信息。当执行exportvg命令时,实际上是将odm里的对应信息删除掉,执行importvg则是将vgda里的信息重新复制到odm中。以此为准,上面的问题就比较好解答了:
Q:odmvgda混乱时,该如何下手?
A:我们知道,lvm信息由两份,一份在硬盘上,一份在odm上。如果odm的出了问题,最常见的处理方式就是使用exportvg命令将vg导出后,重新importvg即可。但在一些特殊情况下这样做会不起作用,可以考虑使用以下几种方式:
Synclvodm,是从VGDA同步ODM,前提是VG的定义还在,ODM里错误的被修正,缺失的会从VGDA导入,但ODM里多的还会存在。
redefinevg也是从VGDA同步ODM,前提是VG定义没了才用,要指定从哪个PV导入,ODM里多的还会在
recreatevg,根据vgda信息重建vg,即使PVID丢失,只有原有的lv和fs等结构未破坏即可修复。
Q:lg_dumplv报too small,增加后很快又空间不足,能否忽略该问题?
A:用sysdumpdev -e看看生成的需要多大空间,然后建个大的dump device,指向新的dump device即可。Dump设备是用来在出故障时捕获内存等信息的,如果太小会dump失败。每天的报错是由crontab里的dumpcheck条目触发的。只有空间不足,每天定时任务里的dumpcheck检查都会导致出现报错。
Q:AIX PV 出现missing和remove的状态原因和相应的解决办法探讨?
A:(1).链路异常,物理损坏,不正常操作会导致missing
对应:排查并确保hdisk到存储lun的物理路径正常,如果链路没问题,一般cfgmgr后会自动更正。但是对于aix下rdac的情况,需要额外注意,aixrdac设备如下:
darX:设备路由,可用理解成整个一台存储,一台存储1个如:dar0
dacX:理解成控制器,一台存储2个如:dac0 dac1
hdiskX:聚合后的硬盘
ds45k存储下,rdac这几个设备经常会异常,导致硬盘紊乱,矫正不过来,需要从darx到hdiskx都删除,再重新cfgmgr
(2). 状态异常会导致remove,这个具体原因不明
应对: 使用chpv -v a hdiskx可以手工更正过来
(3).其他异常,如pvid丢失等。可通过recreatevg命令重建vg
3.LVM在集群环境中的应用
在实际生产环境中,LVM经常会出现在各种集群环境中,比如IBM PowerHA,Oracle RAC等等,在不同的集群环境、不用的应用场景中,对LVM的要求也各不相同,需要我们在实施和维护中多加注意。
典型问题:
1. HACMP中LVM shrink lv问题?
2. 想了解下ha环境中,lvm如何管理,存储扩容,存储性能优化?
3. LVM Mirror其中一台存储挂起,另一台文件系统访问时间?
4. PVID号不同的话不会影响ha接管吧?
5. 在HA环境下不停业务,如何将卷组增加mirror pool功能?
解答以上问题,需要具备下知识
LVM最常出现的场景就是IBM PowerHA(以前的HACMP),vg在HACMP中可以以两种方式出现。一种是普通的vg模式,一种是fast takeover模块(concurrent vg)。不管采用哪种方式,要求挂接的存储盘在两个节点上的PVID必须是一样的。最好major number也要一样。在配置好HACMP并投入运行后,后期对存储层面的变更基本都会涉及到lvm,目前有两种处理方式:
(1). 在其中一个节点进行LVM操作,另外一个节点重新导入。这样做需要预留一定的停机时间。
(2). 直接通过hacmp的c-spoc来在线操作,无需停止HACMP。
在使用Oracle RAC的场景中比较特殊。早期Oracle11.2之前的版本,可以使用裸设备、集群文件系统和asm(10版本)。不管是asm还是裸设备都使用了HACMP,在这里HACMP的作用是将并发的concurrent vg在两个节点同时拉起来(当然,rac的一些服务也要像grpsvcs注册,这里只讨论LVM相关)。所以,只有oracle在使用裸设备或asm的情况下,并且使用了LVM的方式,才会用到HACMP,其他时候不需要。并且,使用了HACMP+concurrent vg的场景下,后续lv的增删可以在一个节点执行,另一个节点会自动识别。到了11G r2版本后,裸设备已经不再被支持,HACMP也失去了存在的意义,基本只使用asm了。并且,由于asm使用的是裸磁盘,识别到的hdiskx还需要将PVID清除掉。
现在我们再来看上面的问题:
Q:HACMP中LVM shrink lv问题?
A:直接通过smithacmp–c-spoc菜单执行即可。也可以在单个节点修改后,另一个节点重新导入。
Q: 想了解下HA环境中,LVM如何管理,存储扩容,存储性能优化?
A: LVM管理,HA环境下需要考虑两台机器的一致性问题,powerha 7.1版本会自动把单机lvm命令翻译成HA环境下的双机命令,如果是hacmp6.1之前的版本,要在HA菜单中操作,才能保证共享vg的信息一致:smittycl_lvm
要注意,更老的版本,5.4.1之前的这个经常会失败,也就是说调整lvm,可能需要安排共享vg varyoff。存储扩容,对os来说,就是lvm管理,同上。
存储性能优化,要具体看环境,双存储镜像在核心db上很常见,要注意两份数据,很清晰的分布在两个存储上,而不只是分布在两个lun上。
Q:LVM Mirror其中一台存储挂起,另一台文件系统访问时间?
A:如果是本地盘,几乎没有影响。如果是两个存储做了LVM的镜像,在对这个环境调优情况下,(AIX FC HDISK参数)一般会有20s左右的io挂起时间。
Q:PVID号不同的话不会影响HA接管吧?
A:要求hacmp环境中的共享磁盘具有相同的PVID,最好major number也一样。
Q:在HA环境下不停业务,如何将卷组增加mirror pool功能?
A:mirror pool主要用于hacmp下的lvm mirror。它的好处是可以在盘数比较多的情况下,把要镜像的两组盘区分开。在ha不停机的情况下,步骤如下
(1)通过c-spoc在线添加对应磁盘
(2)通过c-spoc在线创建mirror pool
(3)通过c-spoc把磁盘加到mirror pool中
(4)通过c-spoc给vg做镜像
4.基于LVM的高可用或迁移方案
由于LVM自身的特性,使得可以直接基于LVM设计存储高可用和存储迁移的方案。善用LVM使得我们不管在方案设计还是日常工作中都会受益良多。
典型问题:
1. 生产挂两个存储,在VG层面做镜像,实施DS8000存储级容灾应该注意什么?
2. 对于善用AIX LVM特性直接做存储双活方案,有几个点想咨询?
3. lvm做镜像如何实现磁盘的读写分离?
4. lvm镜像不同存储的两个卷,存储性能需求及存储故障影响?
5. 如何用最短的停机时间实现存储切换/V5100L转V7000?
解答以上问题,需要具备下知识
AIX本身的LVM mirror功能使得AIX在LVM层面上的存储迁移和高可用成功可能。相关的mirrorvg、mklvcopy、migratepv等命令都可以应用这些场景中。其中mirrorvg实际上调用的还是mklvopcy命令,对卷组基本实现镜像。Mklvcopy可单独的对单个lv进行镜像。Migratepv用于在同卷组中的不同pv间迁移数据,不能在不同卷组间迁移,不能迁移条带化lv。
再来看上面的问题:
Q:生产挂两个存储,在VG层面做镜像,实施DS8000存储级容灾应该注意什么?生产挂两个存储,在VG层面做镜像,在这种场景做DS8000存储的MM复制需要关注那几个方面?应该注意什么?
A:这是IBM前几年最推崇的成熟可靠的解决方案,目前很多金融用户有案例,使用相对广泛,近两年开始推广hyperswap的方案了
LVM双存储需要调整大量的AIX OS FC Hidsk的参数,来保证本地的存储高可用性,同城之间使用DWDM来保证数据链路传输安全稳定可靠。

主要还是考虑性能方面的问题,如果两台存储配置不一样,性能不一样的话,做mirror可能会影响上层应用,注意多路径策略的选择。做MM的话,距离太远会导致IO传输路径变长,service time高,对IO响应时间敏感的应用系统需特别关注。
这样架构的还有一个问题在于,灾备端的卷vgda里记录是有VG镜像的。因此,在拉起灾备的时候,会pv missing校验报错,importvg时间会较长。因此在pv较多的情况下,需要测算一下灾备vg varyon的时间。某银行曾出现过类似架构切换拉起卷一个多小时的情况。
Q:对于善用AIX LVM特性直接做存储双活方案,有几个点想咨询?
(1)LVM方式将磁盘做镜像,那么两个镜像副本的IO延时会有几个毫秒的差异,两个镜像的链路也会存在抖动的风险,那么LVM层面有什么参数或者是策略能较少这方面的风险?
(2)将设远端镜像IO延时超时,那么另外一个镜像就相当于掉线了,当链路恢复之后,除了用镜像同步的方式还有没有更好的恢复掉线镜像的方式?
A:
(1)光纤卡的fc_err_recov硬盘的rw_timeoutreassign_to等参数的设置都会对挂起时间略有影响,需要做对应的调整
(2)因为是基于lvm mirror做的,只能从lvm层面同步stale的pp
Q:lvm做镜像如何实现磁盘的读写分离?
A: 通过在lv层面选择不同的策略即可,命令:chlv -d "ps" xxx_lvname
Q:lvm镜像不同存储的两个卷,存储性能需求及存储故障影响?
如题,lvm镜像两个不同存储的卷,系统io读写取决于较差性能的存储,并且lvm没有缓存机制,需要两个存储卷全部写入完成,才算是真正写入完成,一个存储卷或存储故障,整个系统均会受影响,从这两个角度,是否说明lvm不适用于外置存储卷镜像,只适用于内置硬盘镜像。
A:建议通过lv的读写策略来修正,比如在lv层面使用Parallel write with sequential read scheduling policy策略,即:同时写A,写B,A完成,B完成,写入完成永远从A读,读A失败则读B smitchlv可以改
因为写入是个硬需求改不了,顶多优化一下读。如果写操作比例大,还是建议两个存储的性能差别不要太大
Q:如何用最短的停机时间实现存储切换/V5100L转V7000?
各位专家,我客户现有一个存储IBM5100升级V7000的需求,具体有哪些完善的方案?
主机端为原来有P520和P550 ,新购P740,存储V5100,采用磁带LTO6备份。
AIX5.3,ORACLE10 ,SAP应用:业务数据接近3T。
另外,V7000:双控16G缓存,有8400G的SSD硬盘和16600G SAS,请问如果是全新LVM管理,应该如何对以上存储进行更加合理和优化。
A:因为你的新存储是v7000,所以有两种方案,停机时间都非常小,如下:
1. lvm方式。新的v7000接入aix,配置好lun加入vg,以mklvcopy的方式创建镜像,做完后解除镜像删掉5100的lun。可以无停机时间。
2. v7000的vdm:v7000挂接5100,以image模式导入lun,后续使用v7000的空间和5100做vdm即可。需要较短的停机时间,重新挂接存储
以上是LVM常见的十八个典型问题,以及解决这些问题必备的知识。通过这样一番学习,你是否可以在面对LVM的时候更加自信了?
作者:王巧雷
来源:51CTO