最近大家都在探索“超越深度学习”的方法,“美国版DeepMind” Vicarious 近日在Science上发布的一项研究,使用不同于深度学习的方法,将数据使用效率提升了300多倍,“对于未来的通用人工智能有重要意义”。该研究称,使用这种新的技术,他们攻破了网站常见的验证码防御,相当于通过了“反向图灵测试”。LeCun对这家公司和他们的研究提出了尖锐的批评,说“这是AI炒作教科书式的例子”。不过,支持Vicarious 的人可不少:马斯克、扎克伯格和贝佐斯都是其投资人。
总部位于旧金山的人工智能公司Vicarious近日在Science发表了自己的研究论文,提出了一个生成视觉模型RCN,研究称找到了一种不同于深度学习的方法,能够更高效地利用数据(最多提升300多倍的数据利用率),并且研究还攻破了基于文本的验证码(CAPTCHAs),引起广泛关注。
CAPTCHA ,即全自动区分计算机和人类的公开图灵测试(英语:Completely Automated Public Turing test to tell Computers and Humans Apart),俗称验证码。是一种区分用户是计算机或人的公共全自动程序。在CAPTCHA测试中,作为服务器的计算机会自动生成一个问题由用户来解答。这个问题可以由计算机生成并评判,但是必须只有人类才能解答。由于计算机无法解答CAPTCHA的问题,所以回答出问题的用户就可以被认为是人类。由于这个测试是由计算机来考人类,而不是标准图灵测试中那样由人类来考计算机,人们有时称CAPTCHA是一种 反向图灵测试。
这已经不是Vicarious第一次宣称突破CAPTCHA 了。早在2013年,LeCun就曾在网络上公开批评过他们。
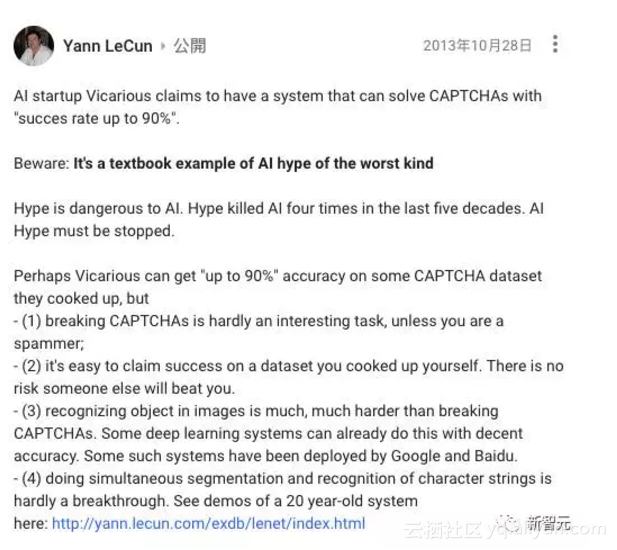
LeCun写道:“AI 初创公司 Vicarious 声称他们拥有一个能够以高达 90% 的成功率破解 CAPTCHAs 的系统。
小心:这是关于 AI 炒作教科书式的例子,最坏的那种。
炒作是 AI 的大敌。炒作在过去50年间“谋杀”了AI 4次。必须马上停止炒作。
也许 Vicarious 在某些他们自建的 CAPTCHA 数据集上达到了“90%”的准确率,但是:
1.攻破 CAPTCHAs 不是什么有趣的任务,除非你是个垃圾邮件发送者;
2.在你自建的数据集上取得这样的成功并不难,但其他人想攻破这个数据集并不容易;
3.在图像中识别对象要比攻破 CAPTCHAs 难得多。一些深度学习系统已经能实现不错的准确率。比如一些谷歌和百度部署的系统。
4.字符流的同时分割和识别几乎不是什么突破。这里有一个20年前就有的系统展示:http://yann.lecun.com/exdb/lenet/index.html
虽然面临着leCun的强烈批评,但是 Vicarious 得到了许多美国科技圈大佬的支持,受到了资本的青睐。新智元查阅资料发现,这家成立于2010年的AI公司,目前融资已经到达C轮,获得的总投资大约
1.34亿美元。公司早期的投资者包括: Elon Musk, Mark Zuckerberg 以及刚刚成为首富的亚马逊总裁 Jeff Bezos,还有YC创始人之一的
Sam Altman等。
Vicarious 被认为是可以与DeepMind相提并论的明星AI初创公司。
原论文
为了更深入的了解这一种研究和Vicarious的最新成果,先去看看这次发布在Science上的原论文。
论文题目:《A generative vision model that trains with high data efficiency and breaks text-based CAPTCHAs》地址:
http://science.sciencemag.org/content/early/2017/10/26/science.aag2612.full

在摘要中,作者介绍:
人类的视觉智能可以从很少的样本中学习并泛化到截然不同的情境下,但是即使是最先进的机器学习模型也没有这样的能力。通过从系统神经科学中获取灵感,我们引入了视觉的概率生成模型,其中基于消息传递的推理(Inference)以统一的方式处理识别、分割和推理(reasoning)。该模型展现出优秀的泛化和 闭塞推理 的能力, 并且在具有挑战性的场景文本识别基准上胜过了深度神经网络,取得了300倍以上的数据效率。此外,该模型通过在不使用特定 CAPTCHA 启发的情况下,将字符进行生成式的分割,基本上攻破了现代基于文本的 CAPTCHAs 防御。我们的模型强调数据效率和组成,这对于未来的通用人工智能有重要意义。

人类字体感知的灵活性。(A)人类善于解析不熟悉的 CAPTCHAs;(B)相同的字符形状以各种各样的外观呈现,人类都可以在这些图像中检测到“A”; (C)常识和上下文会影响字体感知:(i)m vs u 和 n;(ii)根据 occluder 的位置不同,会将相同的线段解释为 N 或 S; (iii)对形状的感知有助于识别“b,i,s,o,n”和“b,i,k,e”。

研究所使用的数据库列表,其中包括了MINIST,也就是LeCun联合发起的数据库。
技术核心:不同于深度学习的方法——递归皮质网络(RCN)
Vicarious 本次发表在Science上的论文,在技术上强调的是,一种新的神经网络方法——递归皮质网络(RCN),并称它在多种计算机视觉任务中实现了强大的性能和较高的数据效率。
在官方博客上,Vicarious 使用脚手架(scaffolding )和白板(tabula rasa)来描述这种网络在学习上与深度学习方法上的不同。
RCN以“脚手架”,也就是可以使用模型中原来已经存在的架构来进行建模。例如,虽然大多数的 CNN和 VAE( 变分自动编码器)都是整图的模型,但是对于对象和图像关注较少。RCN是一个基于对象的模型,它考虑到轮廓和曲面以及对象和背景的分解。 RCN也明确地对形状进行表征,并且横向连接的存在允许它跨越大的变换来池化而不失去特异性,从而增加其不变性。组合性允许RCN用多个对象来表示场景,但只需要对单个对象进行明确的训练。 RCN的所有这些特征都来源于我们的假设,即演化已经赋予了新皮层相似的“脚手架”,这使得我们可以在自己的世界轻松地学习表示,而不是从一个完全空白的“白板”开始。
有了正确的“脚手架”,学习和推理变得更加容易。 在学习过程中,RCN比“白板”的数据效率要高出数十倍,在场景文本识别基准的下,效率是300倍甚至更多。在许多模型都面临过拟合,有许多与其训练集的无关细节的情况下,RCN识别场景的显著特征,允许强化其他类似场景的泛化。此外,在RCN设置中,分类,检测,分割和闭塞推理(occlusion reasoning )都是不同的,它在同一模型上的互连命令,从而为图像中存在的证据提供解释。
CAPTCHA:为什么AI的核心问题是理解字母“A”
在2013年,Vicarious 宣布RCN的早期成功:它能够打破基于文本的人机识别,如下图所示(左栏)。

通过一个模型,Vicarious 在reCAPTCHA上达到66.6%的准确率,在BotDetect达到64.4%的准确率,Yahoo57.4%,PayPal57.1%,均高于在CAPTCHA达到的被认为无效率的1%(见[4]更多细节)。为特定风格优化单个模型时,可以达到高达90%的准确度。
Vicarious 在官方博客上写道: 在揭示了“什么”(what)和”如何”(how)之后,我们想描述“为什么”(why):为什么我们首先选择CAPTCHA基准,为什么它仍然是通用AI的相关基准。
上图(右栏)中的CAPTCHA风格的字母A表示了无需对变体进行特殊训练,人类呈现和识别字母A的组合方式,而不对这些变体进行明确的训练。我们评估的光学字符识别(OCR)的公开的API都没有能够捕获这种多样性,因为这要求识别引擎将其归纳为训练集中未表示的分布。这些方法是基于 暴力模式识别。他们没有组合的概念,因此没有将字母A与其背景分开的机制。此外,他们对物体没有理解,因此没有办法孤立地推断字母A的形状和外观。
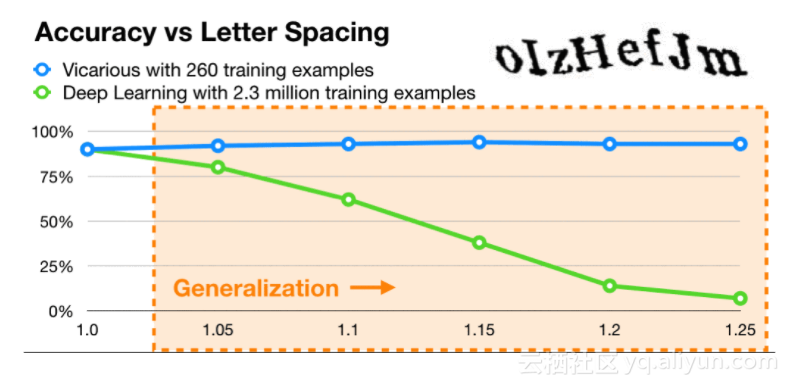
如下面的GIF所示,对CAPTCHA训练的CNN 等深度学习方法对单个字母间距的小变化泛化表现不佳。相比之下,随着字母的展开,RCN保持强劲。请注意,动画中的性能已报告了创建的CAPTCHA图像,以便与reCAPTCHA数据集分开来评估间距的影响。
有影响力的哲学家和AI研究员(Douglas Hofstadter)指出,AI的核心问题是理解字母A。就像Hofstadter一样,我们认为“任何可以用人的灵活性来处理字体的程序,都会拥有全面的人工智能。”虽然ImageNet分类或自动字幕生成系统的”超人“精准度可以让人感觉到感知问题已被解决,但看似简单的问题可以为发展类人智慧提供巨大的深度和洞察力。
Vicarious 在官方博客表示:“在本文中的工作是让计算机能够以人类感知的灵活性和流动性来理解字体的一小步。即使有所进步,我们仍然远远没有解决Hofstadter看起来简单的挑战,即检测到字母A与人的流动性和动力相同。我们相信,我们在本文中探讨的许多想法对于构建可以超越人类的训练分布的系统来说将是重要的。
我们周边世界充满了使用复杂行为在其壁龛内蓬勃发展的生物体。虽然蚂蚁具有超人般的挖掘隧道能力,鲑鱼可能是无与伦比的导航者,但他们的大脑几乎没有告诉我们通用智能。同样,深度学习也表现出许多有限的超人般识别照片和打比赛的能力。重要的是不要将深度学习的成功与创造多元化的狭义智慧融为一体,在通向智慧的道路上取得进步。”
DeepMind以外,另一家瞄准通用人工智能的AI初创企业
上文提到,Vicarious 被认为是可以与DeepMind相提并论的明星AI初创公司,其中的主要原因就是在研究方向上。他们瞄准的也是 通用人工智能。
在 Vicarious 介绍最新研究成果的博客上,他们写道了自己的研究思路,以及对常识的神经科学的观点。以下是部分翻译:
引言
我们从出生的那一刻起,就开始用感官来建立一个关于世界的连贯性模型。在成长的过程中,我们又不断地修正我们的模型,并在生活中毫不费力地使用它。
如果我们看到一个球滚到街上,我们可能会推想到可能是一个孩子将球踢到了那儿。当有人让我们去倒一杯葡萄酒,如果酒已经被装在醒酒器中,我们就不会再去找开瓶器。如果我们已知:“Sally把钉子钉在地板上”,然后被问到“钉子是垂直还是水平的”,我们可以想象出带有一定细节的场景,然后自信地回答:“垂直的”。
在这些情况下,我们正利用我们无与伦比的能力对常见情况做出预测和推论。这个特殊的能力就是我们所说的常识。
常识来自对过去经验,并将之提取成一个一种抽象的表征,可以在任何场景下,获取其中合适级别的细节。这种知识大部分存储在我们的视觉和运动皮层中,作为我们为世界的建立的内部模型。为了有效地发挥常识的作用,它需要被调整,以适应不同的假设,我们把这种能力称为想象力。它能让我们生成模型、实现概率表示和推理算法。
什么样的生成模型才足以产生常识?解决这个问题的一个方法是要问:人类的视觉系统建立了什么样的模型?在我们最近发表在《Science》的论文中,我们通过展示如何将来自大脑皮质的线索纳入我们称为递归皮质网络(RCN)的计算机视觉模型中,来回答这些问题。
在这篇博文中,我们将在常识,大脑皮层以及我们在 Vicarious 的长期研究目标的背景下描述RCN。
现有的生成模型能够产生常识吗?
机器学习和人工智能的现代研究往往是属于简化论(reductionist)的:由研究人员定义智能的一个方面,然后分离其定义的特征,并创建一个基准来评估研究在这一狭义问题的进展,同时尽可能多地控制其他变量。但是 ,常识的问题与这种简化论的道路是相互矛盾的,因为它包含了同一模型许多不同方面的智能。以计算机视觉为例,如果建立了常识模型,应该能够以不同的方式组合不同的表征变量,进而实现对象识别,分割,插补( imputation),生成和将其他各种不同的命令实现整合,在这一过程中,他不需要根据不同的命令进行再训练。
生成模型的研究往往侧重于可以解决具体问题的狭义解决方案,但并不提供一种通过任意概率命令来充分利用模型知识的简单方法。例如,在变分自动编码器(VAE)中,训练的副产品是快速推理网络。
然而,如果得到的命令是进行插补(Imputation),每次操作都需要使用不同观察变量集,那么我们就需要根据每次的命令进行重新训练,对不可用的模型进行渲染。此外,对黑箱模型上“证据下限”(ELBO)的优化一边倒的强调,也体现了获取有意义的潜在变量的重要性。
使用适当的生成结构(归因偏差)从可解释性和在更复杂的系统中实现更丰富的融合的角度上来看都是有益的,即便即使付出的代价是稍微较小的ELBO。生成对抗网络(GAN)的一个优点, 但同时也是其局限性,就是它们没有规定任何推理机制,所以即使在成功训练了一个生成模型之后,我们也必须诉诸不同的技术来回答概率上的命令。甚至一些易于处理的模型,如Pixel RNN,是根据一个等级顺序进行定义的,这可以让一些有条件的命令可以很简单地处理,但对于其他命令来说却很难。
这些单独的生成模型在其训练规则的范围内是很强大,但是它们并不会发展出对世界的连贯性的理解,就是我们定义的常识。为了寻找超越这些狭义的成功的规则,我们将我们转向在常识上取得唯一已知的成功的实践:人脑。
人类大脑的生成模型是什么样的?
认知科学和神经科学数十年的研究已经对人脑的计算和统计特性有了深入的洞察。这些特性体现了通往通用智能的生成模型所需要的几个功能性的要求。
简而言之,我们希望构建的生成模型是组合型的、因式分解的,层次化的,并且根据命令可以灵活调整的。
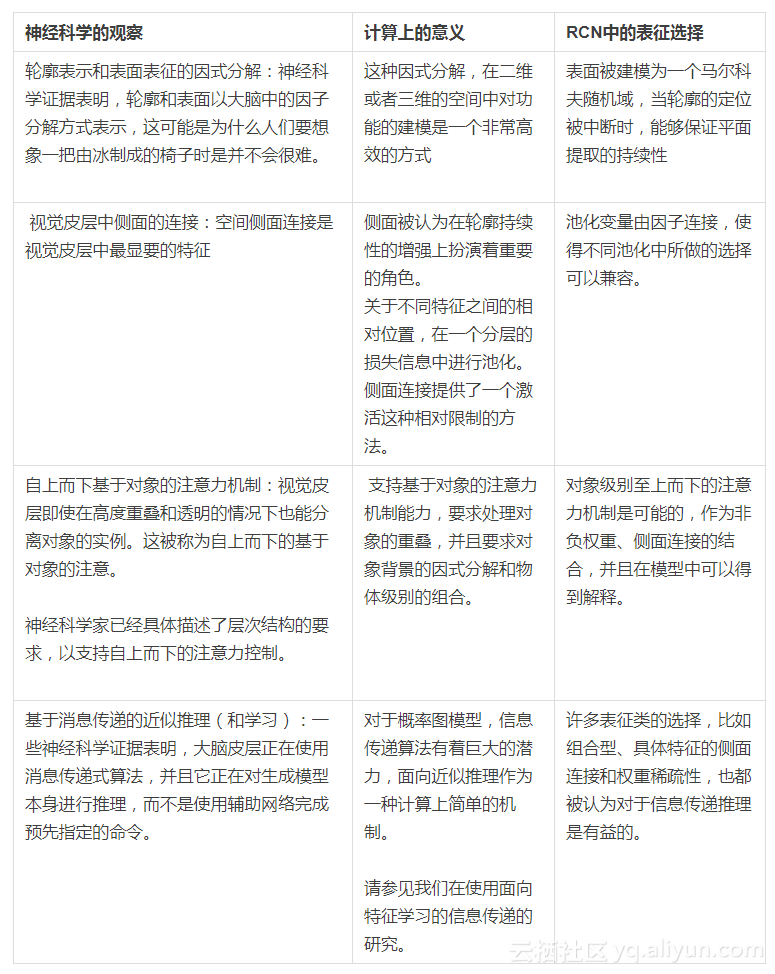
在下表中,我们列出了神经科学观察资料的抽样,为我们的研究提供了灵感。
原文发布时间为:2017-10-29
本文作者:胡祥杰 常佩琦 张易
本文来自合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号
原文链接:”【Science】超越深度学习300倍, Vicarious发布生成视觉模型,LeCun批“这就是AI炒作的教科书