Spark是时下很火的计算框架,由UC Berkeley AMP Lab研发,并由原班人马创建的Databricks负责商业化相关事务。而SparkSQL则是Spark之上搭建的SQL解决方案,主打交互查询场景。
人人都说Spark/SparkSQL快,各种Benchmark满天飞,但是到底Spark/SparkSQL快么,或者快在哪里,似乎很少有人说得清。因为Spark是基于内存的计算框架?因为SparkSQL有强大的优化器?本文将带你看一看一个SparkSQL作业到底是如何执行的,顺便探讨一下SparkSQL和Hive On MapReduce比起来到底有何区别。
SQL On Hadoop的解决方案已经玲琅满目了,不管是元祖级的Hive,Cloudera的Impala,MapR的 Drill,Presto,SparkSQL甚至Apache Tajo,IBM BigSQL等等,各家公司都试图解决SQL交互场景的性能问题,因为原本的Hive On MapReduce实在太慢了。
那么Hive On MapReduce和SparkSQL或者其他交互引擎相比,慢在何处呢?让我们先看看一个SQL On Hadoop引擎到底如何工作的。
现在的SQL On Hadoop作业,前半段的工作原理都差不多,类似一个Compiler,分来分去都是这基层。
小红是数据分析,她某天写了个SQL来统计一个分院系的加权均值分数汇总。
- SELECT dept, avg(math_score * 1.2) + avg(eng_score * 0.8) FROM students
- GROUP BY dept;
其中STUDENTS表是学生分数表(请不要在意这个表似乎不符合范式,很多Hadoop上的数据都不符合范式,因为Join成本高,而且我写表介绍也会很麻烦)。
她提交了这个查询到某个SQL On Hadoop平台执行,然后她放下工作,切到视频网页看一会《琅琊榜》。
在她看视频的时候,我们的SQL平台可是有很努力的工作滴。
首先是查询解析。
这里和很多Compiler类似,你需要一个Parser(就是著名的程序员约架专用项目),Parser(确切说是Lexer加Parser)的作用是把一个字符串流变成一个一个Token,再根据语法定义生成一棵抽象语法树AST。这里不详细展开,童鞋们可以参考编译原理。比较多的项目会选 ANTLR(Hive啦,Presto啦等等),你可以用类似BNF的范式来写Parser规则,当然也有手写的比如SparkSQL。AST会进一步包装成一个简单的基本查询信息对象,这个对象包含了一个查询基本的信息,比如基本语句的类型是SELECT还是INSERT,WHERE是什么,GROUP BY是什么,如果有子查询,还需要递归进去,这个东西大致来说就是所谓的逻辑计划。
- TableScan(students)
- -> Project(dept, avg(math_score * 1.2) + avg(eng_score * 0.8))
- ->TableSink
上面是无责任示意,具体到某个SQL引擎会略有不同,但是基本上都会这么干。如果你想找一个代码干净易懂的SQL引擎,可以参考Presto(可以算我读过的开源代码写的最漂亮的了)。
到上面为止,你已经把字符串转换成一个所谓的LogicalPlan,这个Plan距离可以求值来说还比较残疾。最基本来说,我还不知道dept是个啥吧,math_score是神马类型,AVG是个什么函数,这些都不明了。这样的LogicalPlan可以称为Unresolved(残疾的)Logical Plan。
缺少的是所谓的元数据信息,这里主要包含两部分:表的Schema和函数信息。表的Schema信息主要包含表的列定义(名字,类型),表的物理位置,格式,如何读取;函数信息是函数签名,类的位置等。
有了这些,SQL引擎需要再一次遍历刚才的残废计划,进行一次深入的解析。最重要的处理是列引用绑定和函数绑定。列引用绑定决定了一个表达式的类型。而有了类型你可以做函数绑定。函数绑定几乎是这里最关键的步骤,因为普通函数比如CAST,和聚合函数比如这里的AVG,分析函数比如Rank以及 Table Function比如explode都会用完全不同的方式求值,他们会被改写成独立的计划节点,而不再是普通的Expression节点。除此之外,还需要进行深入的语义检测。比如GROUP BY是否囊括了所有的非聚合列,聚合函数是否内嵌了聚合函数,以及最基本的类型兼容检查,对于强类型的系统,类型不一致比如date = ‘2015-01-01’需要报错,对于弱类型的系统,你可以添加CAST来做Type(类型) Coerce(苟合)。
然后我们得到了一个尚未优化的逻辑计划:
- TableScan(students=>dept:String, eng_score:double, math_score:double)
- ->Project(dept, math_score * 1.2:expr1, eng_score * 0.8:expr2)
- ->Aggregate(avg(expr1):expr3, avg(expr2):expr4, GROUP:dept)
- ->Project(dept, expr3+expr4:avg_result)
- ->TableSink(dept, avg_result->Client)
所以我们可以开始上肉戏了?还早呢。
刚才的计划,还差得很远,作为一个SQL引擎,没有优化怎么好见人?不管是SparkSQL还是Hive,都有一套优化器。大多数SQL on Hadoop引擎都有基于规则的优化,少数复杂的引擎比如Hive,拥有基于代价的优化。规则优化很容易实现,比如经典的谓词下推,可以把Join查询的过滤条件推送到子查询预先计算,这样JOIN时需要计算的数据就会减少(JOIN是最重的几个操作之一,能用越少的数据做JOIN就会越快),又比如一些求值优化,像去掉求值结果为常量的表达式等等。基于代价的优化就复杂多了,比如根据JOIN代价来调整JOIN顺序(最经典的场景),对SparkSQL 来说,代价优化是最简单的根据表大小来选择JOIN策略(小表可以用广播分发),而没有JOIN顺序交换这些,而JOIN策略选择则是在随后要解释的物理执行计划生成阶段。
到这里,如果还没报错,那你就幸运滴得到了一个Resolved(不残废的)Logical Plan了。这个Plan,再配上表达式求值器,你也可以折腾折腾在单机对表查询求值了。但是,我们不是做分布式系统的么?数据分析妹子已经看完《琅琊榜》的片头了,你还在悠闲什么呢?
为了让妹子在看完电视剧之前算完几百G的数据,我们必须借助分布式的威力,毕竟单节点算的话够妹子看完整个琅琊榜剧集了。刚才生成的逻辑计划,之所以称为逻辑计划,是因为它只是逻辑上看起来似乎能执行了(误),实际上我们并不知道具体这个东西怎么对应Spark或者MapReduce任务。
逻辑执行计划接下来需要转换成具体可以在分布式情况下执行的物理计划,你还缺少:怎么和引擎对接,怎么做表达式求值两个部分。
表达式求值有两种基本策略,一个是解释执行,直接把之前带来的表达式进行解释执行,这个是Hive现在的模式;另一个是代码生成,包括 SparkSQL,Impala,Drill等等号称新一代的引擎都是代码生成模式的(并且配合高速编译器)。不管是什么模式,你最终把表达式求值部分封装成了类。代码可能长得类似如下:
- // math_score * 1.2
- val leftOp = row.get(1/* math_score column index */);
- val result = if (leftOp == null) then null else leftOp * 1.2;
每个独立的SELECT项目都会生成这样一段表达式求值代码或者封装过的求值器。但是AVG怎么办?当初写wordcount的时候,我记得聚合计算需要分派在Map和Reduce两个阶段呀?这里就涉及到物理执行转换,涉及到分布式引擎的对接。
AVG这样的聚合计算,加上GROUP BY的指示,告诉了底层的分布式引擎你需要怎么做聚合。本质上来说AVG聚合需要拆分成Map阶段来计算累加,还有条目个数,以及Reduce阶段二次累加最后每个组做除法。
因此我们要算的AVG其实会进一步拆分成两个计划节点:Aggregates(Partial)和Aggregates(Final)。 Partial部分是我们计算局部累加的部分,每个Mapper节点都将执行,然后底层引擎会做一个Shuffle,将相同Key(在这里是Dept)的行分发到相同的Reduce节点。这样经过最终聚合你才能拿到最后结果。
拆完聚合函数,如果只是上面案例给的一步SQL,那事情比较简单,如果还有多个子查询,那么你可能面临多次Shuffle,对于MapReduce 来说,每次Shuffle你需要一个MapReduce Job来支撑,因为MapReduce模型中,只有通过Reduce阶段才能做Shuffle操作,而对于Spark来说,Shuffle可以随意摆放,不过你要根据Shuffle来拆分Stage。这样拆过之后,你得到一个多个MR Job串起来的DAG或者一个Spark多个Stage的DAG(有向无环图)。
还记得刚才的执行计划么?它最后变成了这样的物理执行计划:
- TableScan->Project(dept, math_score * 1.2: expr1, eng_score * 0.8: expr2)
- -> AggretatePartial(avg(expr1):avg1, avg(expr2):avg2, GROUP: dept)
- -> ShuffleExchange(Row, KEY:dept)
- -> AggregateFinal(avg1, avg2, GROUP:dept)
- -> Project(dept, avg1 + avg2)
- -> TableSink
这东西到底怎么在MR或者Spark中执行啊?对应Shuffle之前和之后,物理上它们将在不同批次的计算节点上执行。不管对应 MapReduce引擎还是Spark,它们分别是Mapper和Reducer,中间隔了Shuffle。上面的计划,会由 ShuffleExchange中间断开,分别发送到Mapper和Reducer中执行,当然除了上面的部分还有之前提到的求值类,也都会一起序列化发送。
实际在MapReduce模型中,你最终执行的是一个特殊的Mapper和特殊的Reducer,它们分别在初始化阶段载入被序列化的Plan和求值器信息,然后在map和reduce函数中依次对每个输入求值;而在Spark中,你生成的是一个一个RDD变换操作。
比如一个Project操作,对于MapReduce来说,伪代码大概是这样的:
- void configuration() {
- context = loadContext()
- }
- void map(inputRow) {
- outputRow = context.projectEvaluator (inputRow);
- write(outputRow);
- }
对于Spark,大概就是这样:
- currentPlan.mapPartitions { iter =>
- projection = loadContext()
- iter.map { row => projection(row) } }
至此为止,引擎帮你愉快滴提交了Job,你的集群开始不紧不慢地计算了。
到这里为止,似乎看起来SparkSQL和Hive On MapReduce没有什么区别?其实SparkSQL快,并不快在引擎。
SparkSQL的引擎优化,并没有Hive复杂,毕竟人Hive多年积累,十多年下来也不是吃素的。但是Spark本身快呀。
Spark标榜自己比MapReduce快几倍几十倍,很多人以为这是因为Spark是“基于内存的计算引擎”,其实这不是真的。Spark还是要落磁盘的,Shuffle的过程需要也会将中间数据吐到本地磁盘上。所以说Spark是基于内存计算的说法,不考虑手动Cache的情景,是不正确的。
SparkSQL的快,根本不是刚才说的那一坨东西哪儿比Hive On MR快了,而是Spark引擎本身快了。
事实上,不管是SparkSQL,Impala还是Presto等等,这些标榜第二代的SQL On Hadoop引擎,都至少做了三个改进,消除了冗余的HDFS读写,冗余的MapReduce阶段,节省了JVM启动时间。
在MapReduce模型下,需要Shuffle的操作,就必须接入一个完整的MapReduce操作,而接入一个MR操作,就必须将前阶段的MR结果写入HDFS,并且在Map阶段重新读出来,这才是万恶之源。
事实上,如果只是上面的SQL查询,不管用MapReduce还是Spark,都不一定会有显著的差异,因为它只经过了一个shuffle阶段。
真正体现差异的,是这样的查询:
- SELECT g1.name, g1.avg, g2.cnt
- FROM (SELECT name, avg(id) AS avg FROM students GROUP BY name) g1
- JOIN (SELECT name, count(id) AS cnt FROM students GROUP BY name) g2
- ON (g1.name = g2.name)
- ORDER BY avg;
而他们所对应的MR任务和Spark任务分别是这样的:
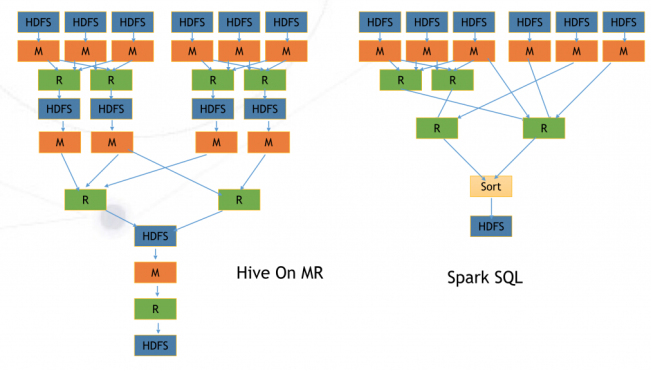
一次HDFS中间数据写入,其实会因为Replication的常数扩张为三倍写入,而磁盘读写是非常耗时的。这才是Spark速度的主要来源。
另一个加速,来自于JVM重用。考虑一个上万Task的Hive任务,如果用MapReduce执行,每个Task都会启动一次JVM,而每次JVM启动时间可能就是几秒到十几秒,而一个短Task的计算本身可能也就是几秒到十几秒,当MR的Hive任务启动完成,Spark的任务已经计算结束了。对于短 Task多的情形下,这是很大的节省。
说到这里,小红已经看完《琅琊榜》回来了,接下去我们讨论一下剧情吧。。。
本文作者:佚名
来源:51CTO