tsharding
TSharding is the simple sharding component used in mogujie trade platform.
分库分表业界方案
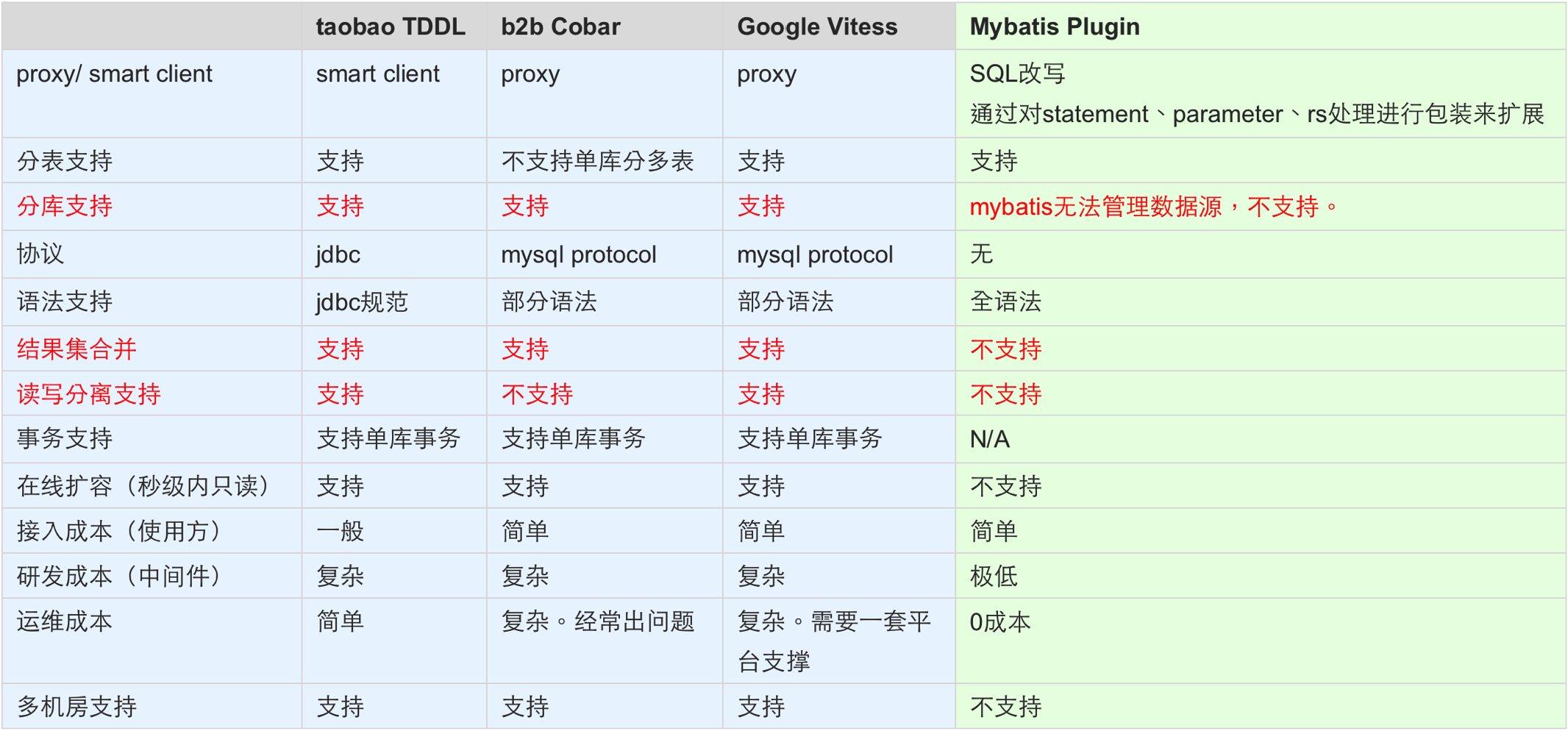
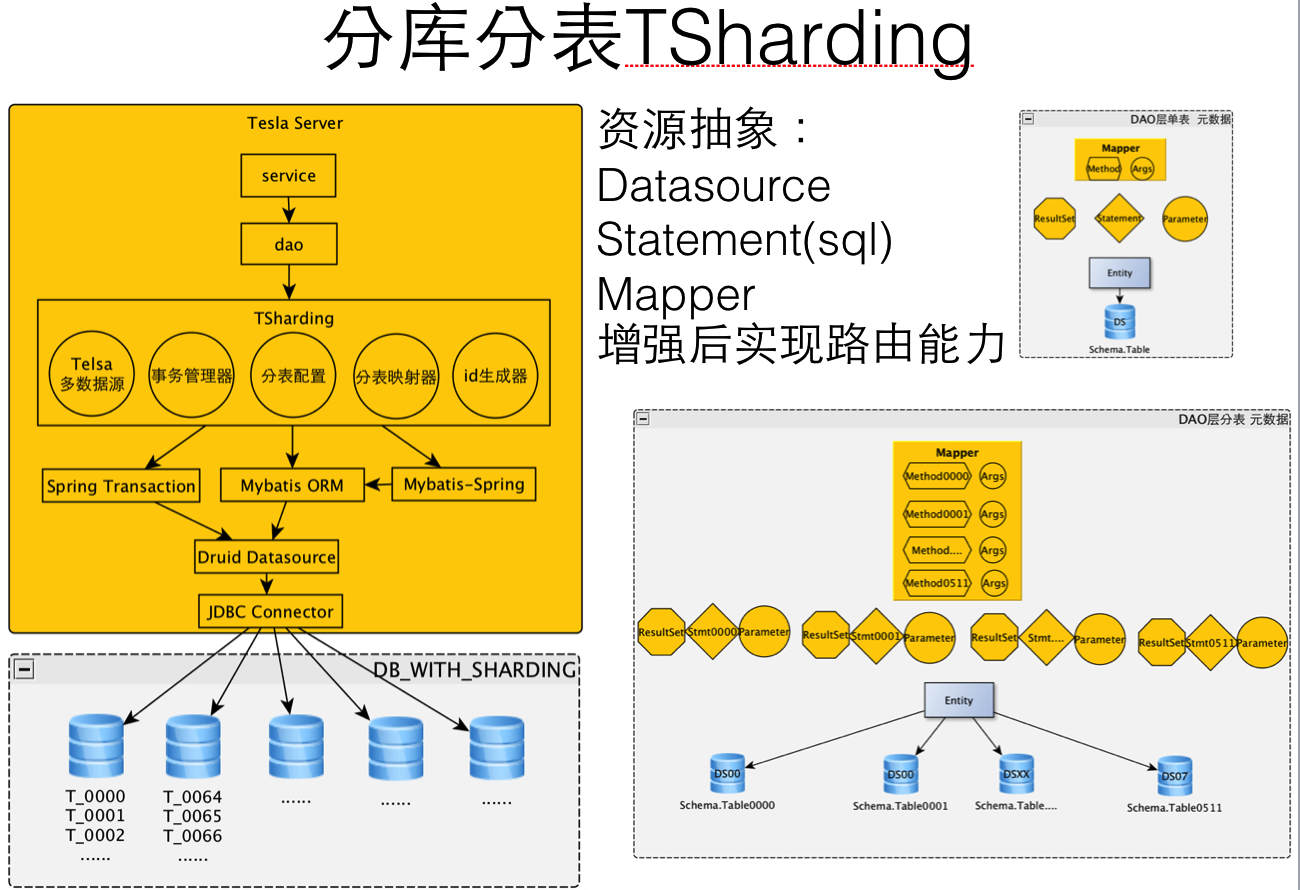
分库分表TSharding
TSharding组件目标
- 很少的资源投入即可开发完成
- 支持交易订单表的Sharding需求,分库又分表
- 支持数据源路由
- 支持事务
- 支持结果集合并
- 支持读写分离
TSharding Resources Abstract
TSharding Resources Classes
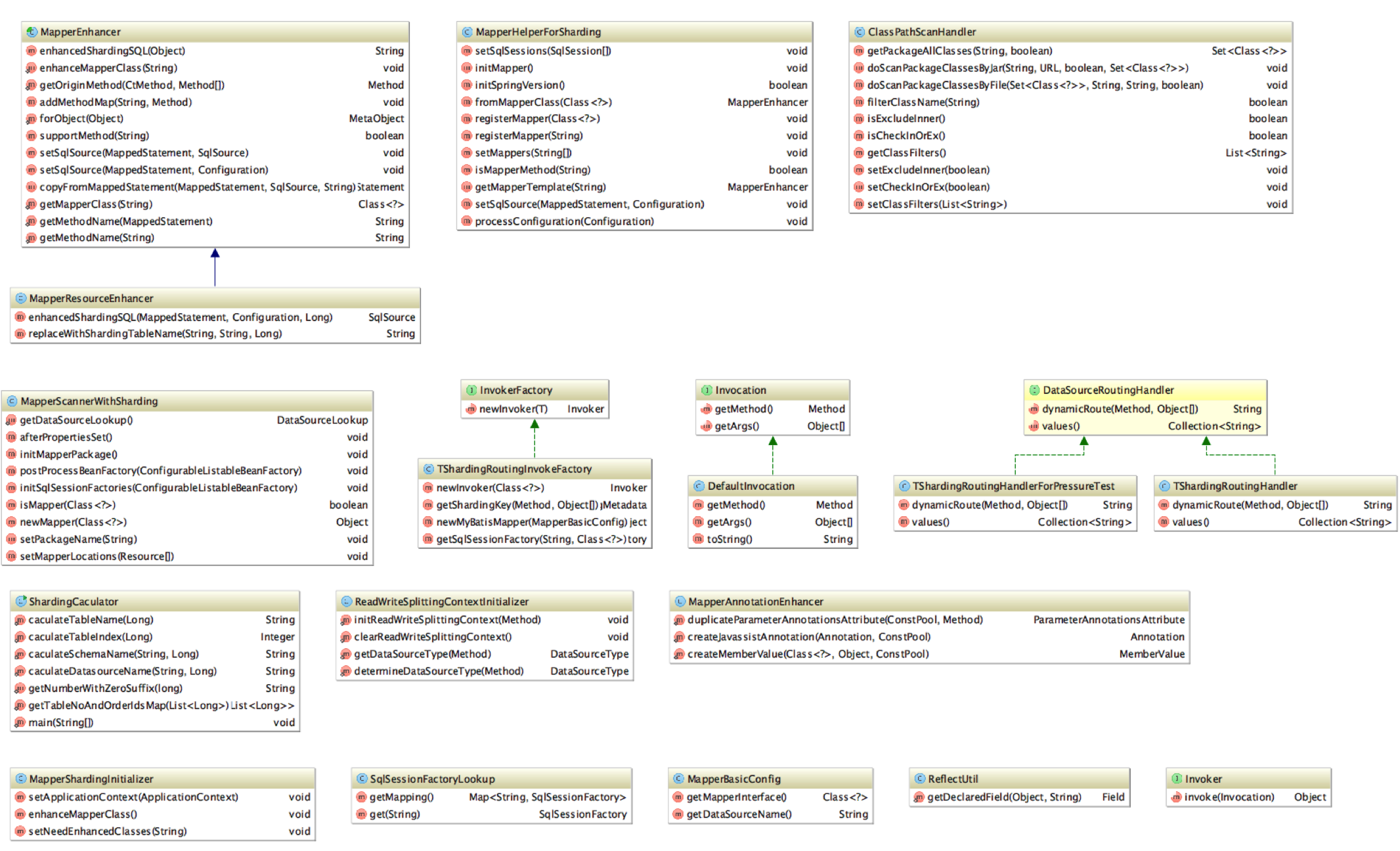
TSharding组件接入过程:
- 引入TSharding JAR包
- 配置所有分库的JDBC连接信息
- Mybatis Mapper方法参数增加ShardingOrderPara/ShardingBuyerPara/ShardingSellerPara注解
- 批量查询增加结果集合并逻辑
http://www.ctolib.com/tsharding.html
时间: 2024-08-07 01:29:06