11.11 三维模型重建算法
由三维成像传感器获得的点云,实质上是在特定视点下对物体表面的离散采样。由于受自遮挡的影响,单个视点下获得的点云是不完备的,无法完整覆盖三维物体的各个表面。因此,大量研究集中于如何将来自多个视点的点云变换到统一的参考坐标系下 ( 即点云配准过程 ),进而将这些配准后的点云融合以得到一个完整的三维模型。
一个典型的三维模型重建系统通常包括成对点云配准、多视点云配准以及三维表面重建三个部分。早期的成对点云配准算法大多借助转台或标记点等方式手动实现[4] ,费时费力且应用场景受限。针对此,本文提出了一种基于局部特征的高精度且稳健的成对点云自动配准算法[5] 。该算法首先在点云上检测关键点并提取 RoPS 局部特征描述子,并利用特征描述子相似性获得两个点云之间的匹配特征对应点对;进而采用关键点的局部参考坐标框架计算可能的刚性变换关系;最后,采用改进迭代最近点 (ICP)算法实现点云之间的精配准。实验结果表明,在大部分情况下,点云配准的旋转误差小于 1.0°且平移误差小于 1 倍点云分辨率。如图 3 所示,当重合度大于 60% 时,所有点云对均能实现正确配准。当重合度在 30%~60% 之间时,75% 的点云对能实现正确配准。此外,本文的成对点云配准算法对噪声和数据分辨率变化十分稳健。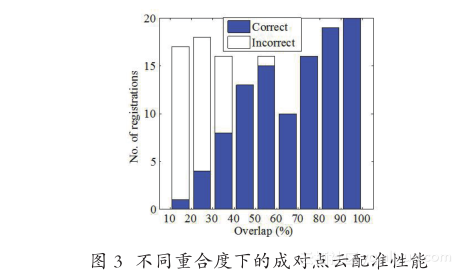
多视点云配准算法的任务,在于获得点云之间的邻接关系及邻接点云的变换关系。经典算法包括张树算法[6]和连接图 (connected graph) 算法[7] ,其缺陷在于运算量较大且只能对来自同一个物体的多视点云进行配准。针对此,本文提出了一种全新的形状生长算法用于实现多物体混合多视点云的高效配准,并由此设计了一个完整的三维模型重建系统[5] 。多视点云配准算法示意图如图 4 所示。首先以所有输入点云作为初始搜索空间 Φ,然后从搜索空间中选择一幅点云作为参考形状 R 1 。对于搜索空间中的点云 S i ,首先采用成对点云配准算法将其与参考形状 R 1 配准,如图 4(a) 所示。若二者之间的重合点数超过一定的阈值,则认为点云 S i 与 R 1 成功实现了配准,并将点云 S i 中与 R 1 的距离大于平均数据分辨率的点添加到参考形状 R 1 中,从而实现了参考形状 R 1 的更新,并将 S i 从搜索空间 Φ 中删除。接着,继续采用形状生长算法对搜索空间 Φ 中尚未验证过的点云 S i+1 进行验证,直到所有的输入点云均已更新到参考形状 R 1中,或 Φ 中没有输入点云可以实现与 R 1 的配准为止。在算法迭代的过程中,R 1 逐渐生长为一个完整三维形状,如图 4(b) 所示。与此同时,形状 R 1 的姿态在整个形状生长过程中均保持不变。因此,所有点云均被配准到一个公共坐标系(即R 1 所采用的坐标系)下。当形状生长过程完成后,便得到了所有可配准输入点云与参考形状 R 1 之间的刚性变换矩阵。采用这些变换矩阵将所有的输入点云变换到 R 1 的坐标系下,从而实现了输入点云的粗配准,进而采用多视点云精配准算法对结果做进一步优化,从而将配准误差均匀分配到整个三维模型中,如图 4(c) 所示。最后,采用体素空间隐式曲面表示法实现多视点云的融合,并采用 Marching Cubes 算法实现三维表面重建,从而到一个光滑无缝的完整三维模型,如图 4(d) 所示。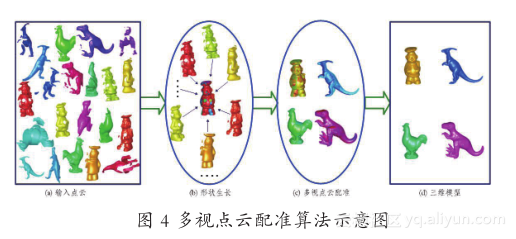
实验结果表明,本文所提多视点云配准算法对输入点云的次序不敏感,计算效率优于张树算法和连接图算法,能高精度全自动地实现单物体或多物体的多视点云配准,在对高分辨率和低分辨率点云上均能获得很好的三维重建结果。图 5(a) 展示了多个物体在多视点下的点云,图 5(b) 至 (e) 为多视点云自动配准后的结果。
