3.6 Spark 资源管理器:Standalone、YARN和Mesos
在本章其他部分(在 PySpark shell 和应用程序中),我们已经在 Spark 的 Standalone 资源管理器中执行过 Spark 应用程序。让我们尝试理解这些集群资源管理器相互之间有什么不同,以及它们该在什么情况下使用。
3.6.1 本地和集群模式
在继续讲解集群资源管理器之前,让我们来了解集群模式与本地模式的区别。
当跨集群执行代码时,了解变量和方法的范围和生命周期非常重要。让我们看一个使用 foreach 动作的例子:

在本地模式下,前面的代码执行正常,因为计数器(counter)变量和 RDD 在相同的内存空间(单个 JVM)里。
在集群模式下,计数器 counter 的值永远不会改变,并且始终保持为 0。在集群模式下,Spark 会计算出带有变量和方法的闭包,并将它们发送到执行进程。当执行进程执行这个 foreach 函数时,它指向的是执行进程上的计数器的新副本。执行进程不能访问驱动进程上的计数器。因此,每次执行此操作时,本地计数器都会递增,但不会返回到驱动进程。要在集群模式下解决此问题,需要为每个闭包创建一个单独的变量副本,或使用一个累加变量。
3.6.2 集群资源管理器
你可以在四种不同的模式下运行 Spark 应用程序:

如果指定了 spark.master(或--master)配置属性,应用程序会在它指定的一个集群资源管理器上运行,运行在客户端还是集群模式则取决于指定的 --deploy-mode 参数。

1. Standalone
默认情况下,以 Standalone模式提交的应用程序会占用集群的所有 CPU 内核(根据 spark.deploy.defaultCores 属性),并给每个执行进程分配 1G 内存。在多个应用程序的环境中,重要的是限制每个应用程序占用的资源上限。限制 CPU 内核占用的方式可以利用 spark-submit 的 --total-executor-cores 参数,或 Spark 配置文件中的 spark.cores.max 参数。要限制占用的内存,可以利用 spark-submit 的 --executor-memory 参数,或 Spark 配置文件中的 spark.executor.memory 参数。
在本示例中,我们使用一个 20 节点的集群,每个节点有 4 个 CPU 内核:

2. YARN
应用程序可以用 --master yarn-client 参数提交,即为客户端模式;或用 --master yarn-cluster 参数提交,即为集群模式。在 Yarn 模式下,你可以指定所需的执行进程数与 CPU 内核数,这可以对照 Spark 的 Standalone 主机中的 -total-executor-cores 参数。

在本示例中,我们使用了一个 20 节点的集群,每个节点有 4 个 CPU 内核:


动态资源分配
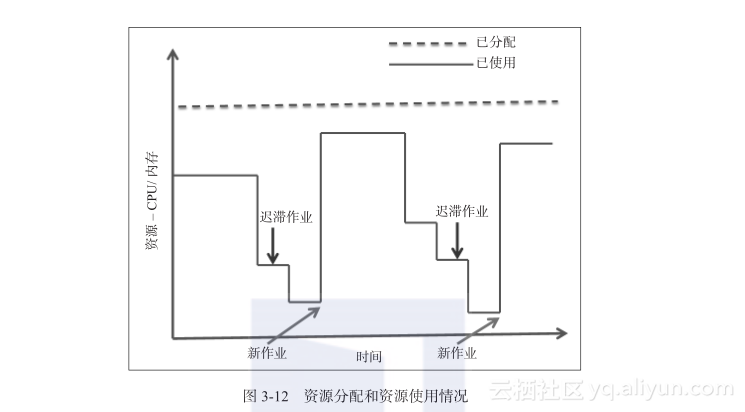
动态资源分配功能是在 Spark 1.2 中引入的。应用程序可以把不会再用到的资源返回给集群,并在以后需要时再次请求它们。动态的资源分配可以有效率地控制集群上的资源使用。如图3-12 所示,由于存在运行较慢的节点(straggler)、调度、等待、空闲等情况,所有 Spark 应用程序中分配和使用的资源都有很大的变化。
要启用此功能,可以在应用程序中设置以下配置属性:


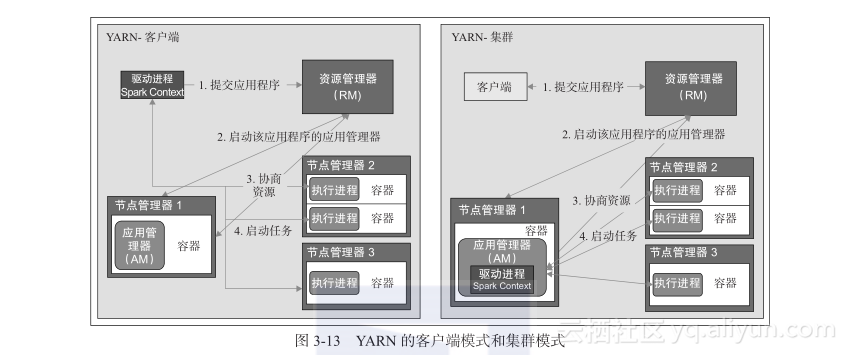
客户端模式和集群模式
在 YARN 客户端模式下运行 Spark 时,驱动进程在客户端计算机上运行,应用管理器和执行进程在集群上运行。每个 Spark 执行进程会作为客户端或集群模式下的一个 YARN 容器运行。
在 YARN 集群模式下,驱动进程在应用管理器中运行。因此,应用管理器负责运行驱动进程和从 YARN 资源管理器请求资源。启动应用程序的客户端在应用程序的整个生命周期中并不需要一直介入。
YARN 集群用于生产作业,而 YARN 客户端模式用于交互模式,在这种模式下,你可以即时看到应用程序的输出。
YARN 客户端模式和集群模式如图3-13 所示。

3. Mesos
Apache Mesos 是一个通用的集群管理器,它可以在集群上运行分析任务及长时间运行的服务(例如 Web 应用程序或键值存储)。请参阅以下示例用法:

Mesos 中有两种类型的调度模式:

4. 该使用哪种资源管理器
当在 Hadoop 集群上把 Spark 和其他应用程序配套使用时,最好使用 YARN 来更好地共享资源。在无需担心改善性能和共享资源的情况下,可以使用 Standalone 管理器。Mesos 和 Yarn 提供了类似的资源共享功能。在 Hadoop 集群上,使用 YARN 是合适的,因为 Hadoop 的所有其他框架都与 Yarn 集成了。对于非 Hadoop 集群,使用 Mesos 也是可行的。