1. Cache Pool引发的问题
之前的文章《MongoDB WiredTiger 存储引擎cache_pool设计 (上) -- 原理篇》和大家分享WiredTiger的整体架构和Cache Pool相关的设计,这篇来介绍下阿里云MongoDB线上出现的问题,及改进措施。
用过MongoDB 3.0之后版本的同学应该都比较熟悉WiredTiger的cache evict问题。
连续好几个版本在cache 淘汰算法上设计都有些小问题,现象总结起来就是写入hang住。本文使用的是MongoDB v3.2.9下wiredtiger-2.8.1(现在wt官方主推v2.9.0版本, MongoDB v3.4之后会使用这个版本,云MongoDB现在可以使用v3.2.9,后续我们会很快支持)。WiredTiger逐渐并入MongoDB的分之管理,Github可以看到如下:
如果自建使用的MongoDB v3.2.10之后的版本,可参考 @林青 的文章?spm=5176.100240.searchblog.34.AinuZY
我们在服务内部用户的时候,发现在write heavy场景下,通过mongostat发现used%居高不下,写入也会抖动的比较厉害,磁盘IO偶尔出现uitl 100%或者非常空闲的奇怪现象,抓取了Mongo的stack发现异常的线程和cache evict相关,紧急情况下收集了部分数据,将MongoDB升级到v3.2.10,问题解决。于是,我们在线下环境进行了复现,收集了profiling数据。
1.1 cache evict
首先介绍cache evict相关的概念,在MongoDB v3.2.8(WiredTiger v2.8.1)里面有如下选项:(注:这些变量在wt-v2.9.1之后意义改变比较大,如不清楚版本可参见http://source.wiredtiger.com/2.8.0/group__wt.html)
| 参数选项 | 含义 |
|---|---|
| cache_size | cache的总大小 |
| eviction_trigger | 百分比, 如果cache内存使用量超过此百分比,则触发cache evict的淘汰 |
| eviction_target | 百分比,如果触发了evict淘汰,则需要将cache内存使用量降至此百分比之下,才停止evict |
| eviction_dirty_trigger | 百分比, 如果cache中dirty page内存使用量超过此百分比,则触发cache evict的淘汰 |
| eviction_dirty_target | 百分比,如果触发了evict淘汰,则需要将cache中dirty page内存使用量降至此百分比之下,才停止evict |
| evict.threads_max | 最大并发的evict线程数 |
| evict.threads_min | 最少并发的evict线程数 |
MongoDB默认设置:threads_max = 4, eviction_target == eviction_dirty_target == 80%eviction_trigger == eviction_dirty_trigger == 95%,cache_size用户设置
在线下环境我们让cache_size尽可能的小,分别设置了2G和10MB,通过sysbench和ycsb在insert heavy情况下复现并遇到了如下两个问题。
1.2 _evict_server cpu 100%
压测程序QPS陡降到100以下,mongostat发现写入几乎完全hang住,cache used 100%左右徘徊
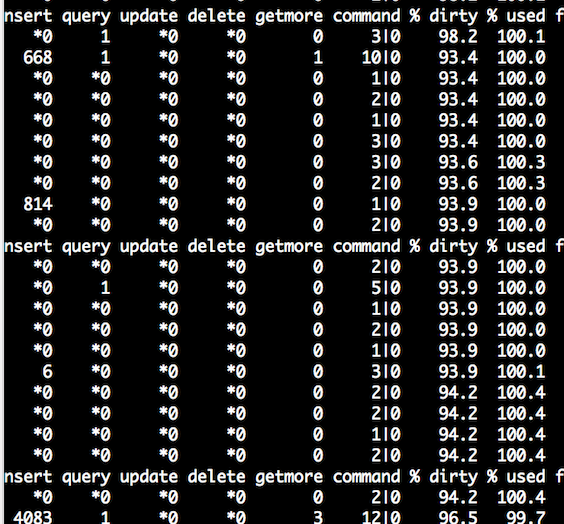
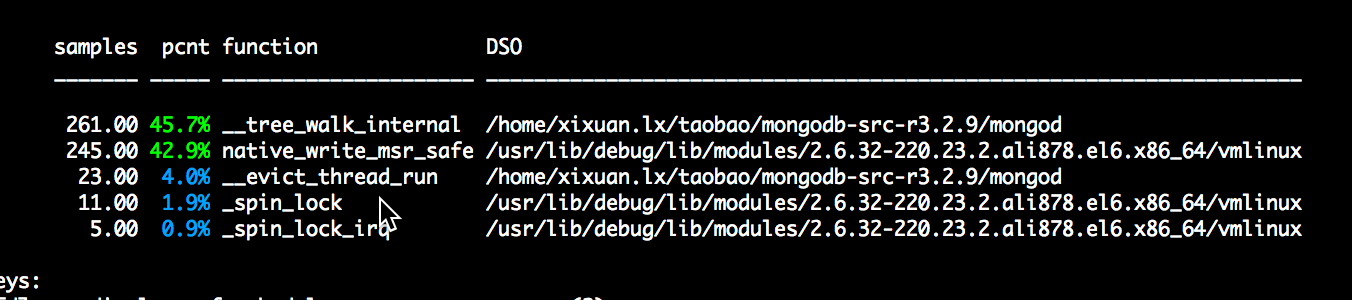
堆栈采样显示__tree_walk_internal占据绝大部分cpu,这个函数是btree 遍历page所用。cache模块的evict_server在寻找可以淘汰的dirty/clean page时会用这个函数依次遍历dirty/clean page,查看是否可以将page进行淘汰,evict_server每检查一次page就会触发__tree_walk_internal,到这里我们猜想cache evict是在大量的遍历page,导致cpu飙高。
1.3 evict hang
同样一个测试数据集,我们使用cacheSize=10MB(最初的目的是让问题尽快复现),偶发出现写入hang,但cpu都是idle。并且MongoDB基本是不可用的状态,·cache used甚至超过100%·
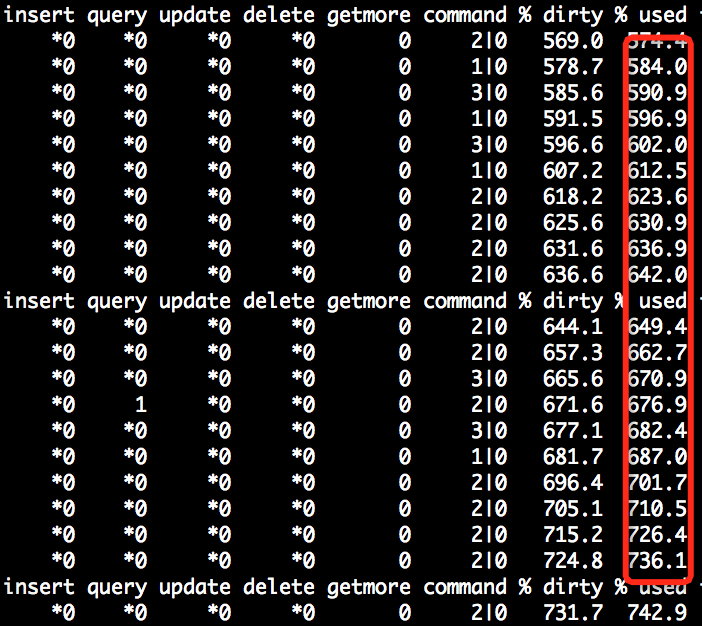
此时获得的堆栈采样在·__wt_sleep()·函数采样比例较高。但由于WiredTiger自选地方比较多,__wt_sleep()经常出现在spin超过一定次数后发生yield,还好有strace,发现sleep()的调用的入参十分有规律,是N + 1000的sleep方式,通过追代码发现如下
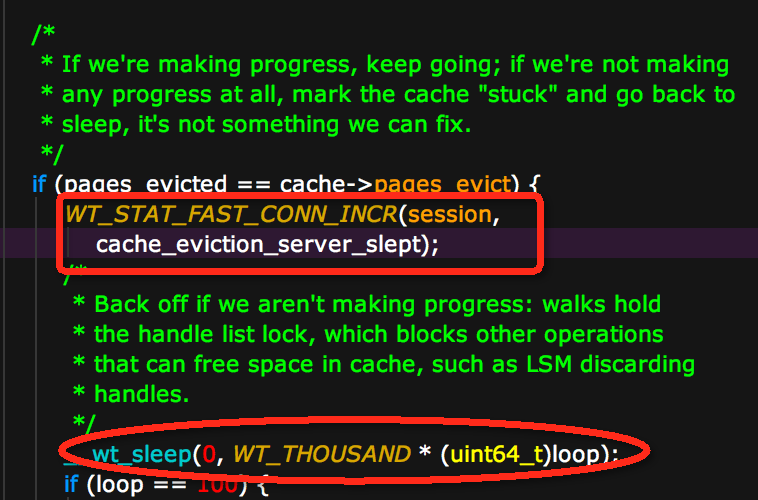
这是当evict_server找到一些page后,但是evict_worker不能进行evict操作,也就是之前统计的pages_evicted等于现在的cache->pages_evict(说明evict的page数量是0),会主动的休眠一下。
这里官方的想法应该是现在evict_worker已经很忙了,不能再evict(比如磁盘IO很大),这时候应该通过sleep放慢evict_server查找脏页的速度(这个假设不一定是成立的,后面会讲到)。
至此,基本的trace工具能搜集到的都差不多收集完了,其实还有systemtap这个神器还没用,打点的功能真是没的说。细心的同学可能发现上图中红色方形中的WT_STAT相关的内部采集点,没错wt内部提供了这样的机制,通过点计数方profiling内部的逻辑。
2. WiredTiger profiling 工具
MongoDB本身支持了wt的profiling参数,通过--wiredTigerStatisticsLogDelaySecs可定期将统计信息写入统计日志(默认0不开启)。我们设置5s一次的采集,在dbpath下会生成很多WiredTigerStat.xx.yy的文件。然后我们通过内置的wtstats.py脚本来生成可读的html
python ./src/third_party/wiredtiger/tools/wtstats/wtstats.py /data/u10/mongod-xixuan/data/primary/)
打开之后可以看到cache、cursor、blockmanager、log、transaction等统计信息
- 更多的Cache Pool相关参数解释可以另一篇文章 《WiredTiger v2.8.1 cache相关参数整理》
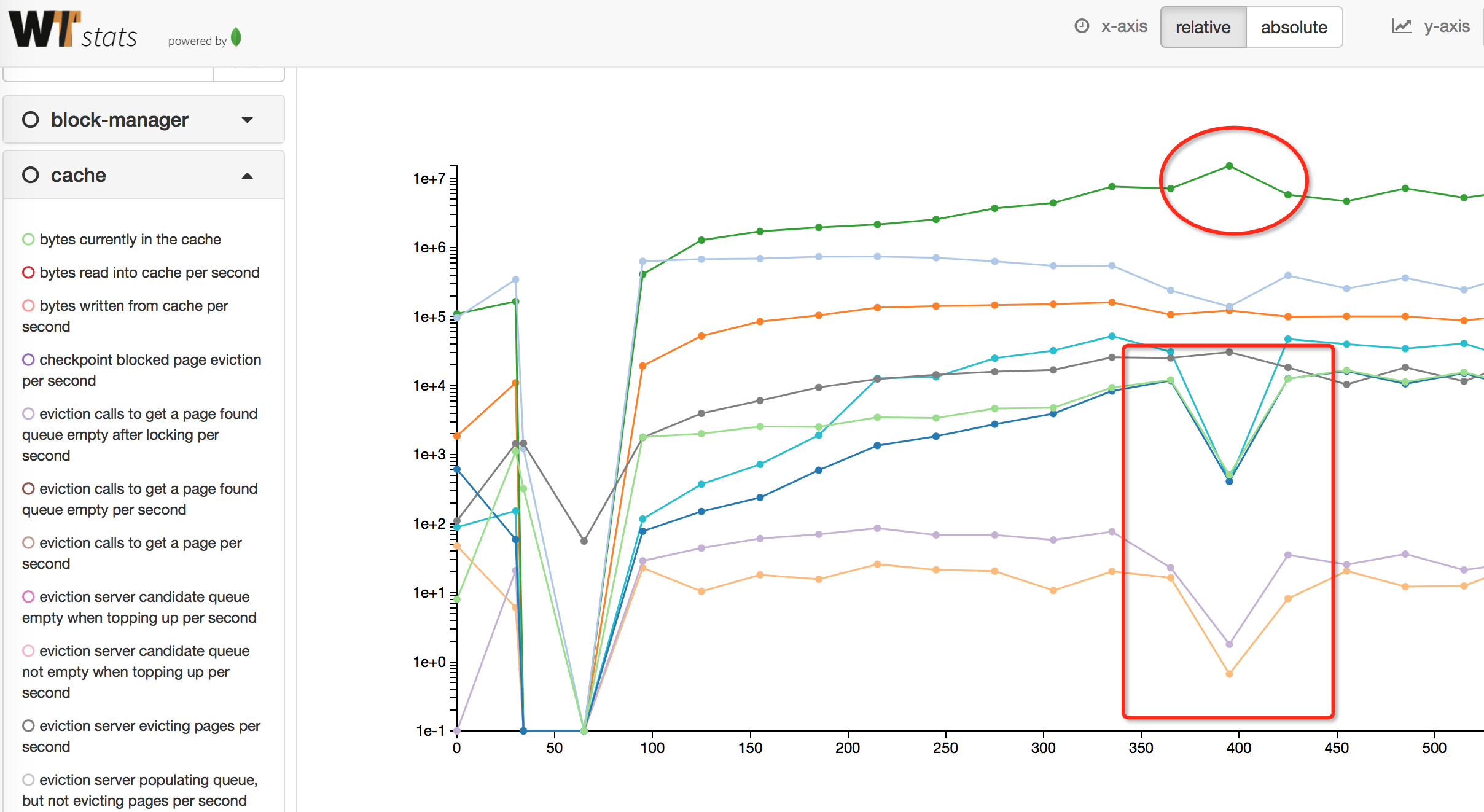
此图可以清晰的看到cache evict的内部采集指标,发现在大量出现下降的400这个地方,很多统计都是陡降(pages_queued要淘汰的page入队数量、pages_evict淘汰数量、pages_reconcile叶子写盘数量),增长的三个指标分别是:
pages walked for eviction,evict时遍历的page数量pages seen by eviction,evict时检查的page数量pages currently held in cache,cache中page的数量
那么,问题就显而易见了,pages在不断的被evict_server看到,遍历的速度还是很快的,但是有如下问题:
- 访问的page不能被evict,所以不能如队列,所以cpu会飙升,但找不到合适的page,
这间接导致了上面说的在不能evict时候会sleep的问题。 - 不能被evict_worker写入磁盘,导致evict失败。
3. 深挖 Root Cause
问题和现象已经很明朗了,下面就是根据代码找到问题所在,这里需要gdb和perf进行调试和采样,需要带上WiredTiger的debug symbol。为了防止编译MongoDB代码(编译时间太痛苦,20分钟以上)。
这里使用--use-system-wiredtiger来指定可以使用自己编译的WiredTiger,这个技巧也可用来测试wt的兼容性和开发的debug用。
scons --use-system-wiredtiger CPPPATH=/home/xixuan.lx/taobao/wiredtiger/include LIBPATH=/home/xixuan.lx/taobao/wiredtiger/lib/
LD_LIBRARY_PATH=/home/xixuan.lx/taobao/wiredtiger/lib/:$LD_LIBRARY_PATH gdb -tui ./mongod
3.1 发现可疑点
经过debug发现3处存在问题的地方:
1) 和checkpoint竞争
evict_server通过__evict_walk_file遍历btree文件的page时,会给cache->evict_walk_lock加锁。同样在checkpoint_server中,对evict_walk_lock也会加锁导致evict和checkpoint操作是互斥的

这带来的效果就是checkpoint如果慢,则evict也会滞后,导致cache增长。这样的问题在测试时候出现过,表现为写入hang滞后,cache used一直涨,但过一段时间后,写入可以恢复的场景。
2) pages_seen增长很快,但是不能进行evict
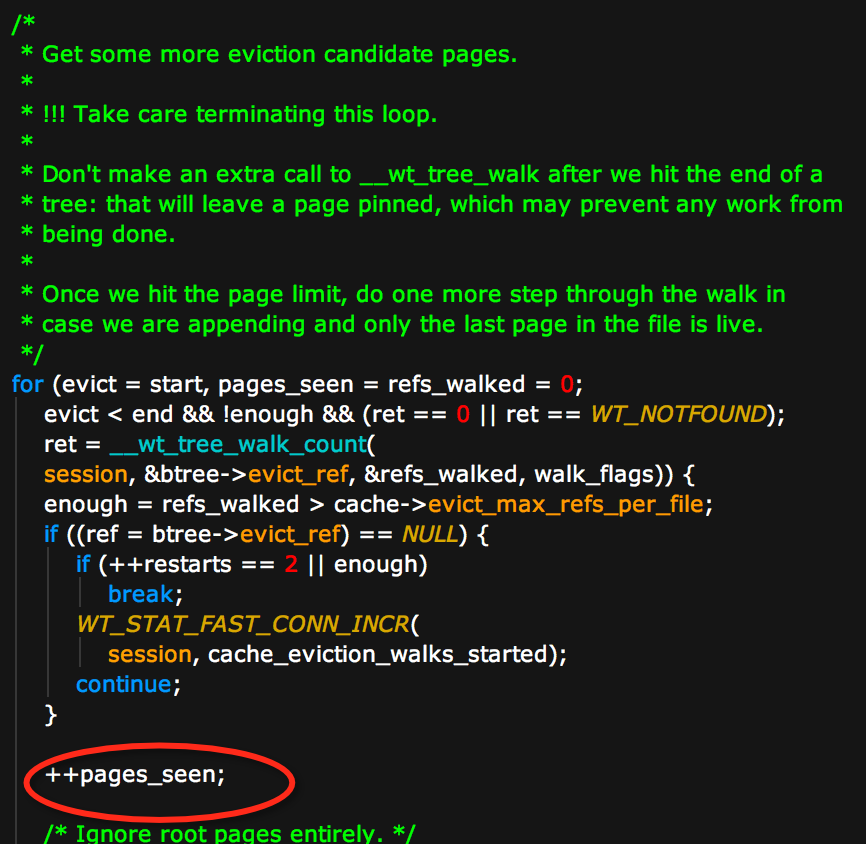
- page_seen是遍历btree的page数量,从第二节中给出的曲线图可以看出这个值一直在快速增长
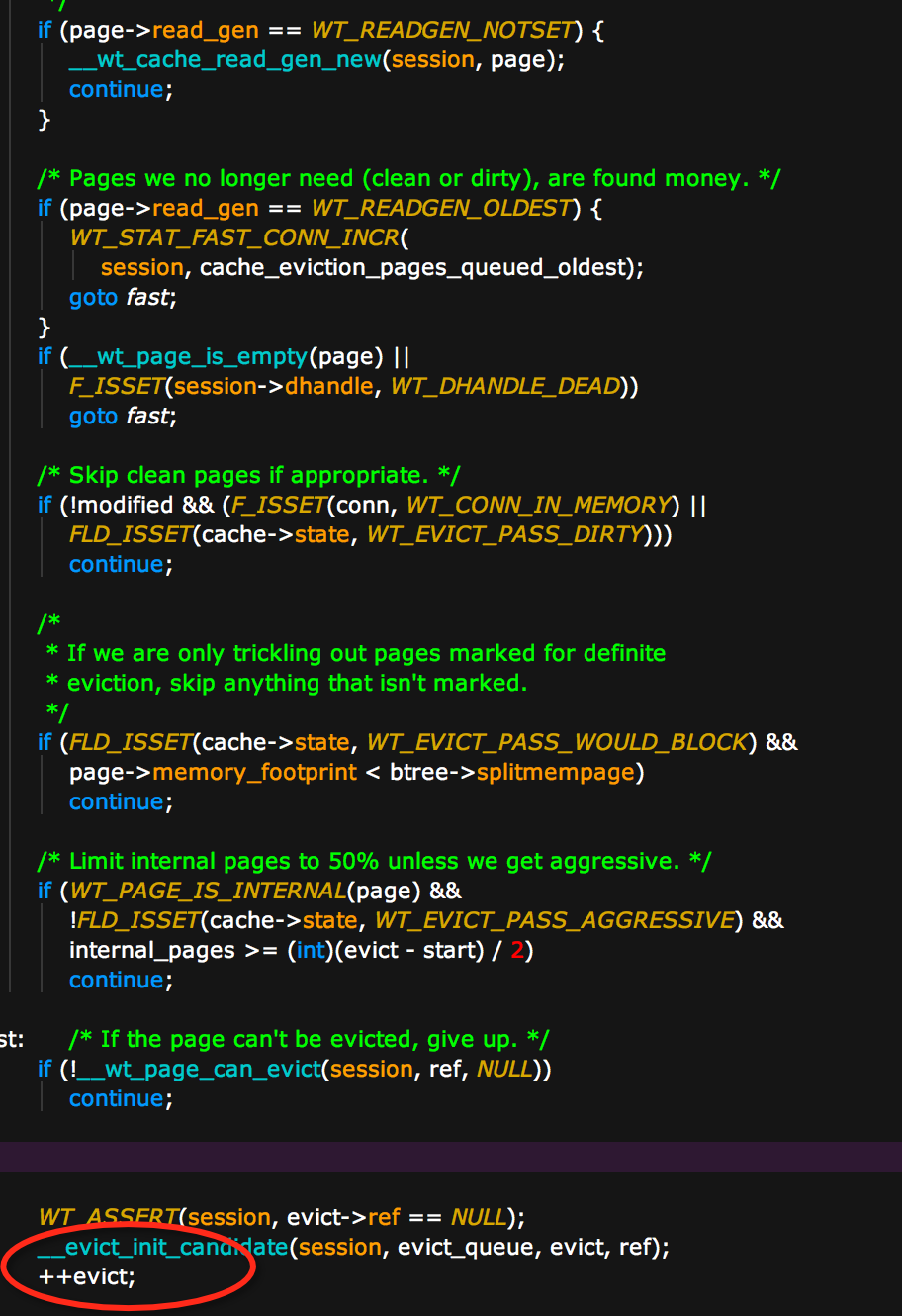
- 可以evict的page陡降说明上述代码中
__wt_page_can_evict()返回false,或者之前的continue,说明page不能淘汰。这里分析了下原因可能有3个: - 看到的page很多都是internal_page也就是索引页
- 或者cache状态是WT_EVICT_PASS_WOULD_BLOCK几近满了并且memory_footprint很大
- 发现btree在做checkpoint,并且陷入了之前说的sleep问题(此时并不是evict太慢,而是没有page可以evict,但是evict_server还是会sleep)
3) __wt_evict_page()调用失败
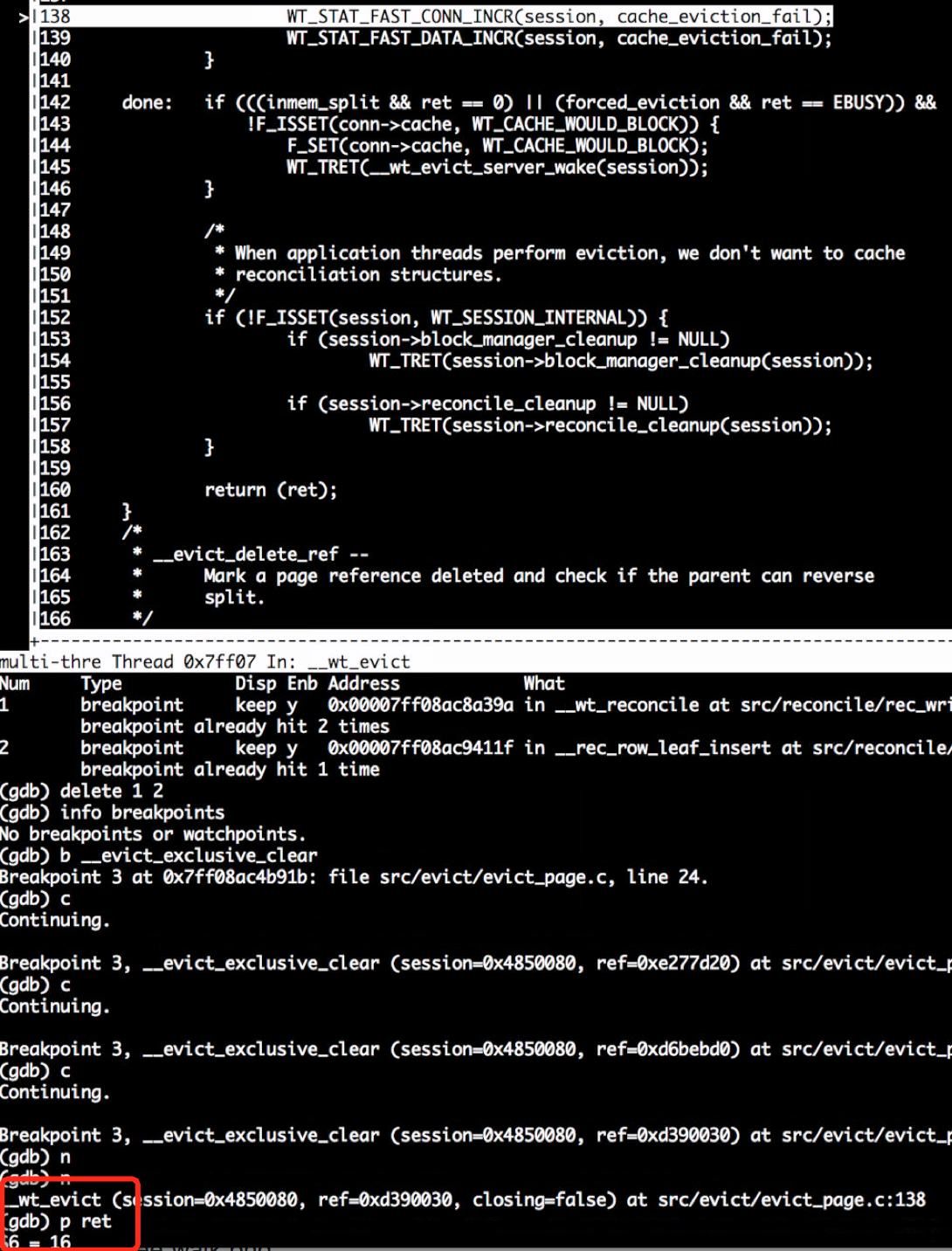
可以看到__wt_evict(这个函数是evict_worker淘汰一个page时调用),返回的ret值是16也就是EBUSY,在深入往下追只有两个地方会返回EBUSY:
if (!F_ISSET(r, WT_EVICT_LOOKASIDE | WT_EVICT_UPDATE_RESTORE))
return (EBUSY);
if (skipped && !F_ISSET(r, WT_EVICT_UPDATE_RESTORE))
return (EBUSY);
在看设置WT_EVICT_UPDATE_RESTORE的地方
flags = WT_EVICTING;
if (closing)
LF_SET(WT_VISIBILITY_ERR);
else if (!WT_PAGE_IS_INTERNAL(page)) {
if (F_ISSET(S2C(session), WT_CONN_IN_MEMORY))
LF_SET(WT_EVICT_IN_MEMORY | WT_EVICT_UPDATE_RESTORE);
else if (page->read_gen == WT_READGEN_OLDEST)
LF_SET(WT_EVICT_UPDATE_RESTORE);
else if (F_ISSET(S2C(session)->cache, WT_CACHE_STUCK))
LF_SET(WT_EVICT_LOOKASIDE);
}
由于未设置WT_EVICT_UPDATE_RESTORE而导致__wt_evict不能刷page
3.2 初步结论
分析到这里,总结一下原因
- checkpoint影响cache evict,导致evict延时,并且可能导致page不能当做evict_page进行淘汰
- evict_server由于__wt_evict失败(由于WT_READGEN_OLDEST标记为mark),evict_worker不能刷page,这时由于evict_server的退让机制(上面的sleep机制) 导致evict问题被放大,越来越慢。
3.3 JIRA跟进
MongoDB官方针对cache问题也提了几个issue,在v3.2.10和v3.4.0中都进不了不少。涉及的issue如下:
- WT-2924 Ensure we are doing eviction when threads are waiting for it
- WT-2545 Investigate eviction tree walk
- WT-2639 Add tree walk optimization to skip subtrees not in memory
- WT-2702 Under high thread load, WiredTiger exceeds cache size
- WT-2664 Change eviction so any eviction thread can find candidates
3.3 改进思路及WiredTiger参数建议
- 可以增大cacheSize,让evict更少,以此来减少上面冲突的概率,也可以拉平evict的差距。
- 减小evict_triger、evict_target的设置,更早的触发evict行为,这样每次evict执行时间会缩短
- 修改源码,临界淘汰时候之淘汰clean page(这样减少磁盘IO),或者禁用sleep退让模式
- 用更高IOPS的硬件,交给硬件来解决软件的问题(没办法的办法)