2.9 用memory_profiler诊断内存的用量
和Rober Kern实现的line_profiler包测量CPU占用率类似,Fabian Pedregosa和Philippe Gervais实现的memory_profiler模块能够逐行测量内存占用率。了解代码的内存使用情况允许你问自己两个问题:
- 我们能不能重写这个函数让它使用更少的RAM来工作得更有效率?
- 我们能不能使用更多RAM缓存来节省CPU周期?
memory_profiler的操作和line_profiler十分类似,但是运行速度要慢的多。如果你安装了psutil包(强烈推荐),memory_profiler会跑得快一点。内存分析可以轻易让你的代码慢上10到100倍。所以实际操作时你可能只是偶尔使用memory_profiler而更多地使用line_profiler来进行CPU分析。
用命令pip install memory_profiler来安装memory_profiler(可选装pip install psutil)。
之前说过,memory_profiler的实现可能并不如line_profiler那么有效率。所以你最好将测试局限在一个较小的问题上,这样才能在一个可容忍的时间内结束。最终验证可以用一整夜来跑,但你需要一个迅速而合理的迭代周期用来分析问题并验证假设。例2-10的代码使用了完整的1000×1000网格,在Ian的笔记本电脑上花了1.5个小时来收集数据。
备忘
需要修改源代码这点比较讨厌。和line_profiler一样,修饰器(@profile)被用来标记选中的函数。这会影响你的单元测试,除非你创建一个伪修饰器——见第57页No-op的@profile修饰器。
在处理内存分配时,你必须意识到情况不像CPU占用率那么直截了当。通常让一个进程将内存超额分配给本地内存池并在空闲时使用会更有效率,因为内存分配操作非常昂贵。另外,垃圾收集不会立即进行,所以对象可能在被销毁后依然存在于垃圾收集池中一段时间。
使用这些技术的后果就是很难真正了解一个Python程序内部的内存使用和释放的情况,因为当从进程外部观察时,某一行代码可能不会分配固定数量的内存。观察多行代码的内存占用趋势可能比只观察一行代码更具有洞察力。
让我们看看memory_profiler在例2-10中的输出。在第12行的calculate_z_serial_purepython中,我们看到分配1000000个项目导致大约7MB的RAM[1]被加入这个进程。这不意味着output列表的大小就是7MB,只是进程在列表内部分配时增长了大约7MB。第13行,我们看到进程在循环内又增长了32MB。这可能是由于调用了range。(例11-1进一步讨论了内存追溯,7MB和32MB的区别源于两个列表的内容。)在第46行的父进程中,我们看到zs和cs列表的分配占用了大约79MB。再强调一遍,这个数字不一定是数组的真实大小,只是进程在创建这些列表的过程中增长的大小。
例2-10 memory_profiler对我们两个主要函数的分析结果,在calculate_z_serial_purepython上显示出预料外的内存使用
$ python -m memory_profiler julia1_memoryprofiler.py
...
Line# Mem usage Increment Line Contents
================================================
9 89.934 MiB 0.000 MiB @profile
10 def calculate_z_serial_purepython(maxiter,
zs, cs):
11 """Calculate output list using...
12 97.566 MiB 7.633 MiB output = [0] * len(zs)
13 130.215 MiB 32.648 MiB for i in range(len(zs)):
14 130.215 MiB 0.000 MiB n = 0
15 130.215 MiB 0.000 MiB z = zs[i]
16 130.215 MiB 0.000 MiB c = cs[i]
17 130.215 MiB 0.000 MiB while n < maxiter and abs(z) < 2:
18 130.215 MiB 0.000 MiB z = z * z + c
19 130.215 MiB 0.000 MiB n += 1
20 130.215 MiB 0.000 MiB output[i] = n
21 122.582 MiB -7.633 MiB return output
Line # Mem usage Increment Line Contents
================================================
24 10.574 MiB -112.008 MiB @profile
25 def calc_pure_python(draw_output,
desired_width,
max_iterations):
26 """Create a list of complex ...
27 10.574 MiB 0.000 MiB x_step = (float(x2 - x1) / ...
28 10.574 MiB 0.000 MiB y_step = (float(y1 - y2) / ...
29 10.574 MiB 0.000 MiB x = []
30 10.574 MiB 0.000 MiB y = []
31 10.574 MiB 0.000 MiB ycoord = y2
32 10.574 MiB 0.000 MiB while ycoord > y1:
33 10.574 MiB 0.000 MiB y.append(ycoord)
34 10.574 MiB 0.000 MiB ycoord += y_step
35 10.574 MiB 0.000 MiB xcoord = x1
36 10.582 MiB 0.008 MiB while xcoord < x2:
37 10.582 MiB 0.000 MiB x.append(xcoord)
38 10.582 MiB 0.000 MiB xcoord += x_step
...
44 10.582 MiB 0.000 MiB zs = []
45 10.582 MiB 0.000 MiB cs = []
46 89.926 MiB 79.344 MiB for ycoord in y:
47 89.926 MiB 0.000 MiB for xcoord in x:
48 89.926 MiB 0.000 MiB zs.append(complex(xcoord, ycoord))
49 89.926 MiB 0.000 MiB cs.append(complex(c_real, c_imag))
50
51 89.934 MiB 0.008 MiB print "Length of x:", len(x)
52 89.934 MiB 0.000 MiB print "Total elements:", len(zs)
53 89.934 MiB 0.000 MiB start_time = time.time()
54 output = calculate_z_serial...
55 122.582 MiB 32.648 MiB end_time = time.time()
...
另一种展示内存使用变化的方式是随时间采样并画图。memory_profiler有一个功能叫mprof,用于对内存使用情况进行采样和画图。它的采样基于时间而不是代码行,因而不会影响代码的运行时间。
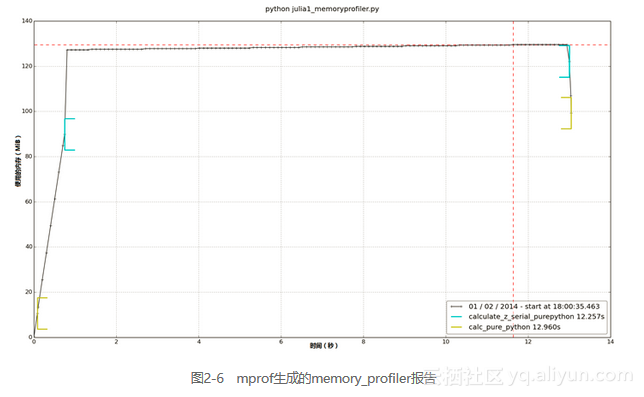
图2-6是mprof运行julia1_memoryprofiler.py生成的。它会首先生成一个统计文件,然后再用mprof画图。图中展示了我们的两个主要函数的执行开始时间以及运行时RAM的增长情况。在calculate_z_serial_purepython内,我们可以看到RAM在函数的整个执行时间内都平稳增长,这是为了生成那些小对象(int和float类型)。
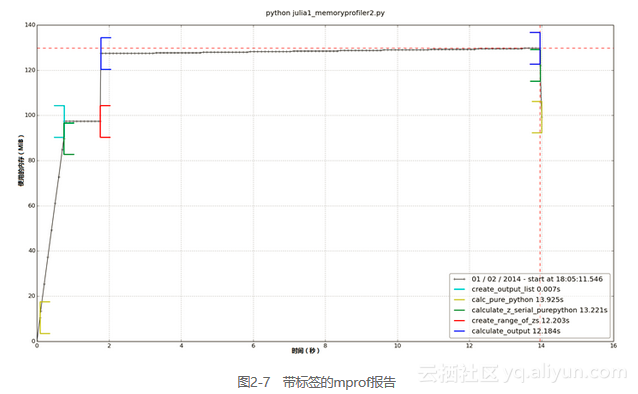
除了在函数层面上观察行为以外,我们还可以使用环境管理器添加标签。例2-11的代码用于生成图2-7。我们可以看到create_output_list标签:它在calculate_z_serial_purepython之后出现,并导致进程分配更多RAM。然后,为了让图更便于理解,我们用time.sleep(1)暂停1秒。
在create_range_of_zs标签之后,我们看到RAM的使用出现了一个猛增;在例2-11的代码中,你可以看到这个标签出现在创建iterations列表时。我们创建列表用的是range而不是xrange——图显示的很清楚,为了创建一个索引,一个具有1 000 000个项目的大列表被实例化。这个方法很没有效率,一旦遇到更大的列表,扩展性也不好(我们的RAM会耗尽!)。用于创建这个列表的内存分配操作本身也占用了一点时间,却没有为这个函数带来什么有用的贡献。
备忘
在Python 3中range的行为改变了,它跟Python 2的xrange一样。xrange在Python 3中已被淘汰,2to3转换工具会自动帮你进行这一转换。
例2-11 用环境管理器给mprof图像添加标签
@profile
def calculate_z_serial_purepython(maxiter, zs, cs):
"""Calculate output list using Julia update rule"""
with profile.timestamp("create_output_list"):
output = [0] * len(zs)
time.sleep(1)
with profile.timestamp("create_range_of_zs"):
iterations = range(len(zs))
with profile.timestamp("calculate_output"):
for i in iterations:
n = 0
z = zs[i]
c = cs[i]
while n < maxiter and abs(z) < 2:
z = z * z + c
n += 1
output[i] = n
return output
对于占据了图像大部分时间的calculate_output,我们可以看到RAM有一个非常缓慢的线性增长,这是用于分配给内部循环中所有用到的临时数字。使用标签确实可以帮助我们细粒度地了解内存的使用情况。
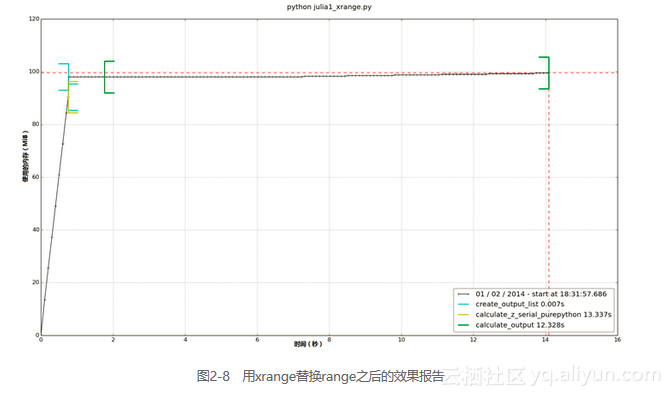
最后,我们可将range调用替换成xrange。在图2-8中,我们可以看到内部循环的RAM使用情况相应降低了。
如果我们想要测量某些语句的RAM使用情况,我们可以用IPython的%memit魔法函数,其工作方式类似于%timeit。第11章会详细讨论%memit的用法以及各种增进RAM使用效率的方法。