2.2MapReduce编程模型简介
Hadoop系统支持MapReduce编程模型,这个编程模型由谷歌公司发明,该模型可以利用由大量商用服务器构成的大规模集群来解决处理千兆级数据量的问题。MapReduce模型有两个彼此独立的步骤,这两个步骤都是可以配置并需要用户在程序中自定义:
- Map:数据初始读取和转换步骤,在这个步骤中,每个独立的输入数据记录都进行并行处理。
- Reduce:一个数据整合或者加和的步骤。在这个步骤中,相关联的所有数据记录要放在一个计算节点来处理。
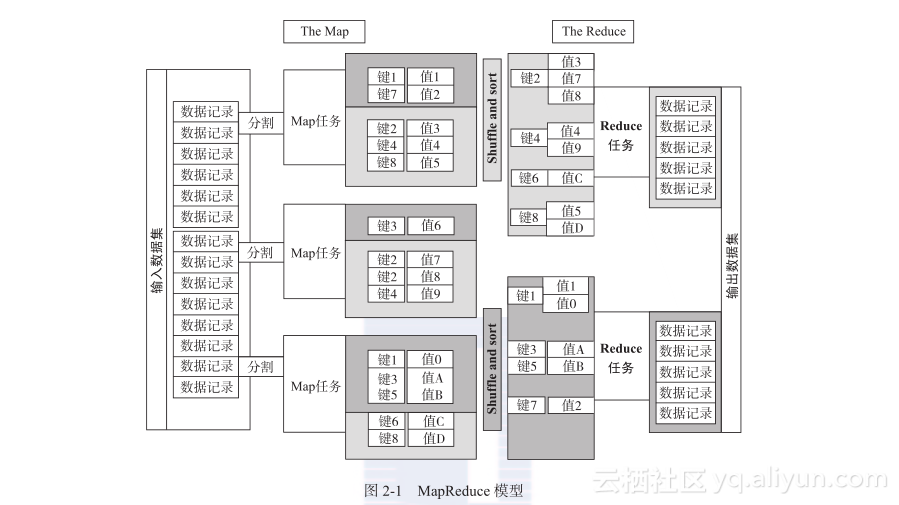
Hadoop系统中的MapReduce核心思路是,将输入的数据在逻辑上分割成多个数据块,每个逻辑数据块被Map任务单独地处理。数据块处理后所得结果会被划分到不同的数据集,且将数据集排序完成。每个经过排序的数据集传输到Reduce任务进行处理。图2-1展示了MapReduce模型是如何工作的。
一个Map任务可以在集群的任何计算节点上运行,多个Map任务可以并行地运行在集群上。Map任务的主要作用就是把输入的数据记录(input records)转换为一个个的键值对。所有Map任务的输出数据都会进行分区,并且将每个分区的数据排序。每个分区对应一个Reduce任务。每个分区内已排好序的键和与该键对应的值会由一个Reduce任务处理。有多个Reduce任务在集群上并行地运行。
一般情况下,应用程序开发者根据Hadoop系统的框架要求,仅需要关注以下四个类:一个类是用来读取输入的数据记录,并将每条数据记录转换成一个键值对;一个Mapper类;一个Reducer类;一个类是将Reduce方法输出的键值对转换成输出记录进行输出。
让我们来使用MapReduce编程模型的“Hello-World”程序:计数程序(the word-count application),来示例讲解MapReduce的编程思想。
假设你有海量文本文档。大家现在分析非结构化数据的兴趣越来越浓,这样的情况是比较常见的,这些文本文档可以从维基百科下载页面下载获得,详见页面http://dumps.wikimedia.org,
也可以是用于法律分析的一个大型组织的邮件数据存档(例如,安然公司电子邮件数据集:http://www.cs.cmu.edu/~enron/ )。利用这些文本数据,可以做很多有意思的分析(比如,信息提取,基于文本内容的文档聚类,基于语义的文档分类)。大多数的文本分析最开始要做的就是统计文档语料库中每个单词的数量(文档的集合通常被称为一个语料库,corpus)。另一个用途是计算一个词/文档对应的“词频/逆向文件频率”(TF/IDF)。
关于TF/IDF的讲解和相关程序示例,详见链接:http://en.wikipedia.org/wiki/Tf-idf。
从直觉上来说,计算文档中每个词出现的个数并不是一件难事。我们简单地假定文档中的每个词是使用空格分隔的。一个清晰明了的解决方案是:
1)维护一个哈希表(hashmap),该哈希表的键为文本中的每个词,该键对应的值是该词的个数。
2)把每篇文档加载到内存。
3)把文档分隔成一个个的词。
4)对于文档中的每个词,更新其在哈希表中的计数。
5)当所有的文档都处理完成,我们就得到了所有单词的计数。
对于大多数的语料库来说,每个不同的单词的计数不过几百万,所以上面介绍的解决方案在逻辑上是可行的。可是这个解决方案的最大隐患是处理的数据量有限(毕竟,我们这本书是关于大数据的)。当语料库的数据量增加至T量级,按照这个方案,一个计算节点需要花费数小时,甚至数天才能完成整个数据的处理过程。
现在,当数据量非常大的时候,我们可以尝试使用MapReduce来解决这个计数问题。要记住,这个计数问题将是你们经常碰到的使用场景,解决这个问题是很简单的但却不能使用单台计算机来做,应该使用MapReduce。
按照上面的解决方案,我们使用MapReduce来实现,步骤如下:
1)有一个多台服务器组成的集群供我们使用。我们假设该集群的计算节点数量为50,这是生产环境中的典型场景。
2)每台服务器上都会运行大量的Map处理。一个合理的假设是有多少个文件正在被处理,就有多少个Map处理。后面的章节会发现,这个假设并不严格(当我们在讲解压缩模式下的文件或者其他格式的序列文件时,该假设并不成立)。但是,现在我们先认为这个假设是成立的。假设现在有一千万个文件,这样会有一千万个Map处理这些文件。在给定的时间内,我们假设有多少个CPU核,就有多少个Map处理可以同时运行。集群的服务器是8核的CPU,所以8个Mapper可以同时运行,这样一来,每台服务器负责运行20万个Map处理。整个数据处理过程中,每个计算节点会同时运行8个Mapper,共25 000次迭代(每次迭代过程可以运行8个Mapper,一个CPU运行一个Mapper)。
3)每个Mapper处理一个文件,抽取文件中的单词,并输出如下形式的键值对:<{WORD}, 1>。Mapper的输出如下:
4)假设我们只有一个Reducer。这个假设并不是必须的,这只是默认的设定。默认的设置值在实际的应用场景中是常常需要改变的,在本例中,这个默认的设置值是合适的。
5)Reducer会接受如下格式的键值对:<{WORD}, [1,....1]>。换句话说,Reducer任务接受的键值对的构成是,其键为任意一个Mapper输出的单词(),其值为任意一个Mapper输出的与键对应的一组值([1,....1])。Reducer的输入键值对示例如下所示:

6)Reducer每处理一个相同的单词,就简单地将该单词的计数加1,最终得到了<单词>的总数;然后将结果按照以下键值对格式输出:<{WORD}, {单词总数}>。Reducer任务的输出键值对示例如下所示:

从一个键对应一个值变换成了在Reduce阶段接受的一个键对应一组值,这个过程在MapReduce中称为排序/混洗(sort/shuffle)阶段。由Mapper任务输出的所有键值对在Reducer任务中都按键排序了。如果配置了多个Reducer,那么每个Reducer将会处理键值对集合中的某个子集。键值对在由某个Reducer处理之前,就已经按键排序完毕,这确保了相同的键对应的值会由同一个Reducer接受并处理。
在Reducer阶段,在Reduce任务执行之前,并不是真正地为每个要处理的键创建一个与该键对应的值的列表。否则,对于英语中典型的连接词,会造成大量的内存占用。假设在我们的例子中,1000万个文本文档,每个文本文档中存在the单词20次。这样一来,对于the这个键,其对应的值列表将会是含有2亿个1的列表。这会轻易地占满运行Reducer的Java虚拟机(JVM)的内存。在sort/shuffle阶段,键the对应的所有的值1会被一起传送到相应的运行Reducer的计算节点的本地文件系统中。当Reducer开始处理键the的时候,该键对应的值1会通过Java迭代接口流式地读入。
图2-2展示了上述数据处理方案的逻辑过程。

讲到这里,你可能想知道每个Mapper是如何访问文件的。这些文件存储在哪里?每个Mapper是从网络文件系统(NFS)来获取这些文件的吗?显然不是。回想一下第1章中我们讲到的,从网络中读取数据的速度要比从本地文件系统中读取慢一个数量级。所以,Hadoop系统从系统结构设计上就确保了大多数的Mapper都从本地磁盘读取文件。这意味着,我们例子中的整个语料库的所有文档都分布存储在50个计算节点中。尽管HDFS的总体设计使得文件对网络传输交换是敏感的,以此来确保计算被调度到文件所在的位置来本地执行,但是从MapReduce系统来看这是一个统一一致的文件系统。这个文件系统就是著名的Hadoop分布式文件系统(HDFS)。后面的章节我们会更细致地讲解HDFS系统。