MaxCompute(原ODPS)是阿里云自主研发的具有业界领先水平的分布式大数据处理平台, 尤其在集团内部得到广泛应用,支撑了多个BU的核心业务。 MaxCompute除了持续优化性能外,也致力于提升SQL语言的用户体验和表达能力,提高广大ODPS开发者的生产力。
MaxCompute基于ODPS2.0新一代的SQL引擎,显著提升了SQL语言编译过程的易用性与语言的表达能力。我们在此推出MaxCompute(ODPS2.0)重装上阵系列文章
第一弹 - 善用MaxCompute编译器的错误和警告
第二弹 - 新的基本数据类型与内建函数
第三弹 - 复杂类型
第四弹 - CTE,VALUES,SEMIJOIN
上次向您介绍了 新的基本数据类型与内建函数,这次向您介绍复杂数据类型
原ODPS也支持两种复杂类型,ARRAY, MAP,但是有些场景下还是不够用
- 场景1
我的项目里,生成的一个中间表,为了优化性能,里面有一列最好是个数组,因为如果把数组打散,每行上存一个元素,会因为其他列的重复导致数据量爆炸。首先想从上游表中生成这个数组,搜索半天文档,发现唯一的方式是把源数据列先转STRING,再用wm_concat聚合,再用split函数打散成ARRAY<STRING>,这样原来类型信息丢了,不过STRING似乎也能用,好,继续。后面的运算有个地方需要取数组最后一个元素,试图用数组下标配合size函数,my_array[size(my_array)], 发现报告错误,下标必须是常量,可是我的数组不是定长的,看看有没有函数能反转数组呢?没有!最后不得不放弃使用数组。。。 - 场景2
我的任务是为每个广告生成一个曲线,代表随着广告商的出价由低到高,预计的impression, click次数的曲线。最自然的表达是有个数据结构,里面存着出价,impression次数,click次数。可是ODPS不支持这样的用法,只好encode成一个字符串,每次操作先编码,再解码。好麻烦,效率也很差,可是没有办法。。。
MaxCompute采用基于ODPS2.0的SQL引擎,大幅度改进了复杂类型并提供了配套的内建函数,基本解决了上述问题。
复杂类型的扩充
此文中采用MaxCompute Studio作展示 ( MaxCompute从2.8.0.2版本开始支持复杂类型,如果您的版本不够新,请升级到最新版本 )。
首先,安装MaxCompute Studio,导入测试MaxCompute项目,创建工程,建立一个新的MaxCompute脚本文件, 如下
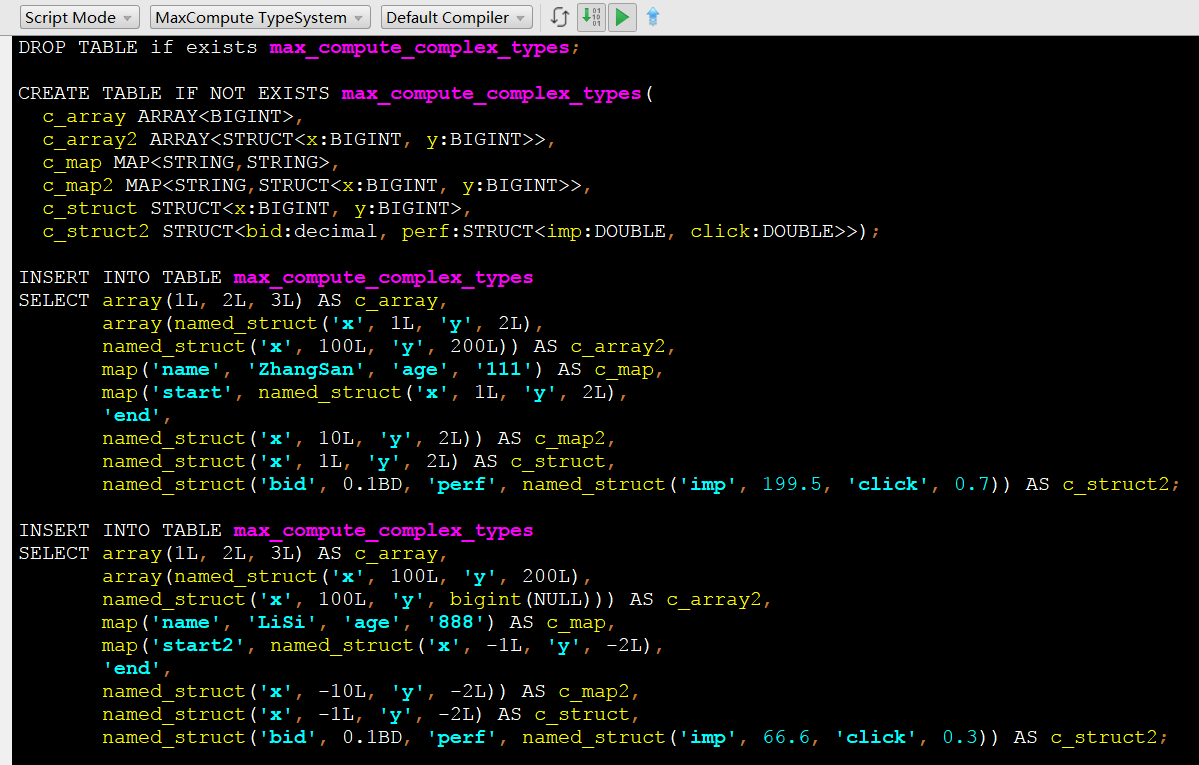
运行后,可以在MaxCompute Studio的Project Explorer中找到新创建的表,察看表的详细信息,并预览数据,如下图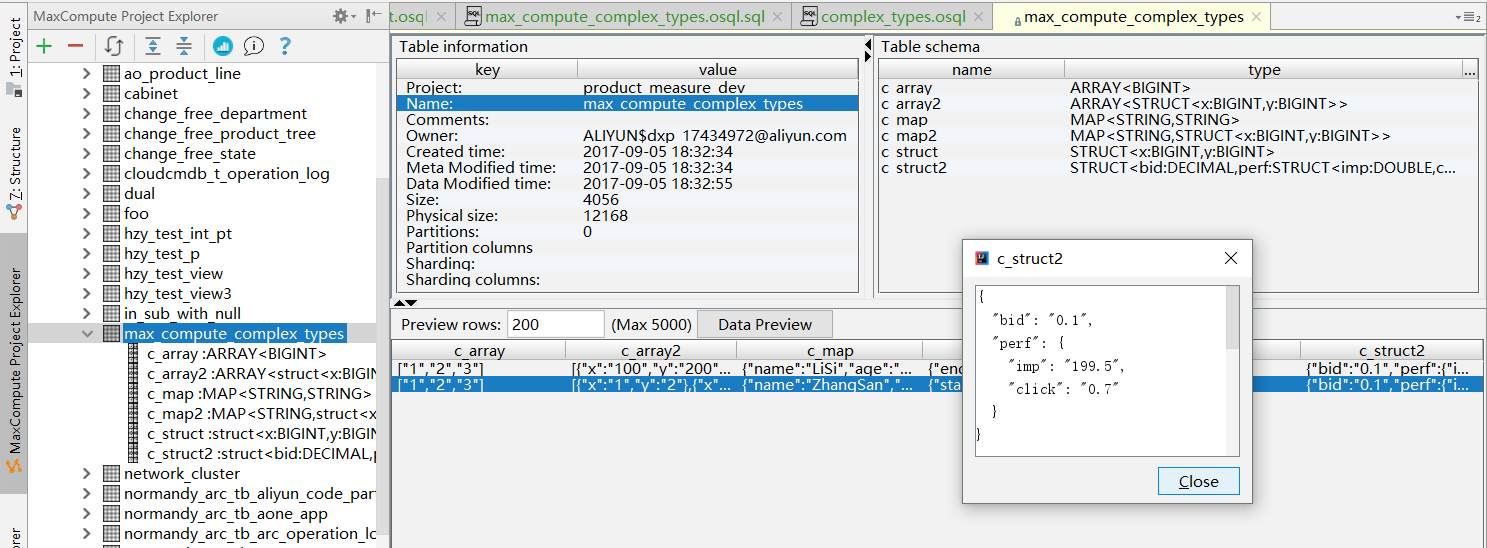
可以看到MaxCompute支持ARRAY, MAP, STRUCT类型,并且可以任意嵌套使用。
MaxCompute Studio支持含新类型表数据的导入导出,可参考此ATA文章
- MaxCompute支持的复杂类型见下表
| 类型 | 定义示例 | 构造示例 | 访问示例 |
|---|---|---|---|
| ARRAY |
array<int>, array<struct<a:int, b:string>>
|
array(1, 2, 3), array(array(1, 2), array(3, 4))
|
a[1], a[x][y]
|
| MAP |
map<string, string>,map<tinyint, array<string>>
|
map("k1", "v1", "k2", "v2"),map(1Y, array('a', 'b'), 2Y, array('x', 'y'))
|
m['k1'],m[2Y][id]
|
| STRUCT |
struct<x:int, y:int>,struct<a:array<int>, b:map<int, int>>
|
named_struct('x', 1, 'y', 2), named_struct('a', array(1, 2), 'b', map(1, 7, 2, 8)
|
s.x, s.b[1]
|
复杂类型构造与操作函数
| 返回类型 | 签名 | 注释 |
|---|---|---|
| MAP<K, V> | map(K key1, V value1, K key2, V value2, ...) | 使用给定key/value对建立map, 所有key类型一致,必须是基本类型,所有value类型一致,可为任意类型 |
| ARRAY<K> | map_keys(Map<K, V> m) | 将参数中的map的所有key作为数组返回,输入NULL,返回NULL |
| ARRAY<V> | map_values(MAP<K, V> m) | 将参数中的map的所有value作为数组返回,输入NULL,返回NULL |
| int | size(MAP<K, V>) | 取得给定MAP元素数目 |
| TABLE<K, V> | explode(MAP<K, V>) | 表生成函数,将给定MAP展开,每个key/value一行,每行两列分别对应key和value |
| ARRAY<T> | array(T value1, T value2, ...) | 使用给定value构造ARRAY,所有value类型一致 |
| int | size(ARRAY<T>) | 取得给定ARRAY元素数目 |
| boolean | array_contains(ARRAY<T> a, value v) | 检测给定ARRAY a中是否包含v |
| ARRAY<T> | sort_array(ARRAY<T>) | 对给定数组排序 |
| ARRAY<T> | collect_list(T col) | 聚合函数,在给定group内,将col指定的表达式聚合为一个数组 |
| ARRAY<T> | collect_set(T col) | 聚合函数,在给定group内,将col指定的表达式聚合为一个无重复元素的集合数组 |
| TABLE<T> | explode(ARRAY<T>) | 表生成函数,将给定ARRAY展开,每个value一行,每行一列对应相应数组元素 |
| TABLE (int, T) | posexplode(ARRAY<T>) | 表生成函数,将给定ARRAY展开,每个value一行,每行两列分别对应数组从0开始的下标和数组元素 |
| STRUCT<col1:T1, col2:T2, ...> | struct(T1 value1, T2 value2, ...) | 使用给定value列表建立struct, 各value可为任意类型,生成struct的field的名称依次为col1, col2, ... |
| STRUCT<name1:T1, name2:T2, ...> | named_struct(name1, value1, name2, value2, ...) | 使用给定name/value列表建立struct, 各value可为任意类型,生成struct的field的名称依次为name1, name2, ... |
| TABLE (f1 T1, f2 T2, ...) | inline(ARRAY<STRUCT<f1:T1, f2:T2, ...>>) | 表生成函数,将给定struct数组展开,每个元素对应一行,每行每个struct元素对应一列 |
在UDF中使用复杂类型
原ODPS不支持在UDF中访问任何复杂类型。MaxCompute Java UDF支持所有复杂类型,Python UDF也会在不久的将来支持。
JAVA UDF中复杂类型的表示方法
ODPS的UDF分为三大类:UDF,UDAF,UDTF,其中:
1. UDAF和UDTF通过@Resolve annotation来指定sinature,在MaxCompute 2.0上线后,用户将可以在Resolve annotation中。如 @Resolve("array<string>,struct<a1:bigint,b1:string>,string->map<string,bigint>,struct<b1:bigint, b2:binary>")
2. UDF通过evaluate方法的signature来映射UDF的输入输出类型,此时参考MaxCompute类型与java类型的映射关系。其中array对应java.util.List, map对应java.util.Map,struct对应com.aliyun.odps.data.Struct 。需要注意的是,com.aliyun.odps.data.Struct从反射是看不出field name和field type的,所以需要用 @Resolve annotation来辅助,即如果需要再UDF中使用struct,要求在UDF class上也标注上@Resolve注解,这个注解只会影响参数或返回值中包含com.aliyun.odps.data.Struct的重载。目前class上只能提供一个@Resolve annotation,因此一个UDF中带有struct 参数或返回值的重载只能有一个。这个是目前的一个限制,我们正在改进,后续将会取消这一限制。
实际用例
如以下代码,定义了一个有三个overloads的UDF,其中第一个用了array作为参数,第二个用了map作为参数,第三个用了struct。由于第三个overloads用了struct作为参数或者返回值,因此要求必须要对UDF class打上@Resolve annotation,来指定struct的具体类型。
@Resolve("struct<a:bigint>,string->string")
public class UdfArray extends UDF {
public String evaluate(List<String> vals, Long len) {
return vals.get(len.intValue());
}
public String evaluate(Map<String,String> map, String key) {
return map.get(key);
}
public String evaluate(Struct struct, String key) {
return struct.getFieldValue("a") + key;
}
}
用户可以直接将复杂类型传入UDF中:
create function my_index as 'UdfArray' using 'myjar.jar';
select id, my_index(array('red', 'yellow', 'green'), colorOrdinal) as color_name from colors;
小节
MaxCompute丰富了复杂类型的支持,可以更好的适应各种应用场景。MaxCompute仍将在兼容性,表达能力等多方面持续改进类型系统。从本系列的下一篇起,开始介绍MaxCompute在SQL语言其他方面的改进!