
1.概述
最近有同学和网友私信我,问我MongoDB方面的问题;这里我整理一篇博客来赘述下MongoDB供大家学习参考,博客的目录内容如下:
- 基本操作
- CRUD
- MapReduce
本篇文章是基于MongoDB集群(Sharding+Replica Sets)上演示的,故操作的内容都是集群层面的,所以有些命令和单独的使用MongoDB库有异样。
2.基本操作
常用的 Shell 命令如下所示:
- db.help() # 数据库帮助
- db.collections.help() # 集合帮助
- rs.help() # help on replica set
- show dbs # 展示数据库名
- show collections # 展示collections在当前库
- use db_name # 选择数据库
查看集合基本信息,内容如下所示:
- #查看帮助
- db.yourColl.help();
- #查询当前集合的数据条数
- db.yourColl.count();
- #查看数据空间大小
- db.userInfo.dataSize();
- #得到当前聚集集合所在的
- db db.userInfo.getDB();
- #得到当前聚集的状态
- db.userInfo.stats();
- #得到聚集集合总大小
- db.userInfo.totalSize();
- #聚集集合储存空间大小
- db.userInfo.storageSize();
- #Shard版本信息
- db.userInfo.getShardVersion()
- #聚集集合重命名,将userInfo重命名为users
- db.userInfo.renameCollection("users");
- #删除当前聚集集合
- db.userInfo.drop();
3.CRUD
3.1创建
在集群中,我们增加一个 friends 库,命令如下所示:
- db.runCommand({enablesharding:"friends"});
在库新建后,我们在该库下创建一个user分片,命令如下:
- db.runCommand( { shardcollection : "friends. user"});
3.2新增
在MongoDB中,save和insert都能达到新增的效果。但是这两者是有区别的,在save函数中,如果原来的对象不存在,那他们都可以向collection里插入数据;如果已经存在,save会调用update更新里面的记录,而insert则会忽略操作。
另外,在insert中可以一次性插叙一个列表,而不用遍历,效率高,save则需要遍历列表,一个个插入,下面我们可以看下两个函数的原型,通过函数原型我们可以看出,对于远程调用来说,是一次性将整个列表post过来让MongoDB去处理,效率会高些。
Save函数原型如下所示:

Insert函数原型(部分代码)如下所示:
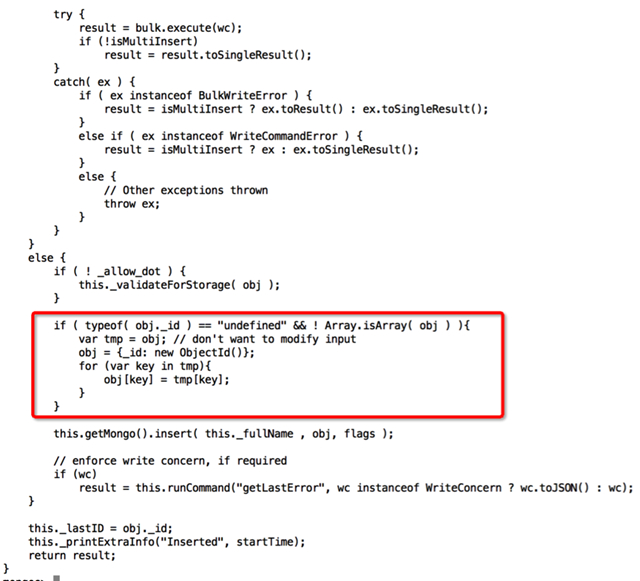
3.3查询
3.3.1查询所有记录
- db. user.find();
默认每页显示20条记录,当显示不下的情况下,可以用it迭代命令查询下一页数据。注意:键入it命令不能带“;” 但是你可以设置每页显示数据的大小,用DBQuery.shellBatchSize= 50;这样每页就显示50条记录了。
3.3.2查询去掉后的当前聚集集合中的某列的重复数据
- db. user.distinct("name");
- #会过滤掉name中的相同数据 相当于:
- select distict name from user;
3.3.3查询等于条件数据
- db.user.find({"age": 24});
- #相当于:
- select * from user where age = 24;
3.3.4查询大于条件数据
- db.user.find({age: {$gt: 24}});
- # 相当于:
- select * from user where age >24;
3.3.5查询小于条件数据
- db.user.find({age: {$lt: 24}});
- #相当于:
- select * from user where age < 24;
3.3.6查询大于等于条件数据
- db.user.find({age: {$gte: 24}});
- #相当于:
- select * from user where age >= 24;
3.3.7查询小于等于条件数据
- db.user.find({age: {$lte: 24}});
- #相当于:
- select * from user where age <= 24;
3.3.8查询AND和OR条件数据
- AND
- db.user.find({age: {$gte: 23, $lte: 26}});
- #相当于
- select * from user where age >=23 and age <= 26;
- OR
- db.user.find({$or: [{age: 22}, {age: 25}]});
- #相当于:
- select * from user where age = 22 or age = 25;
3.3.9模糊查询
- db.user.find({name: /mongo/});
- #相当于%%
- select * from user where name like '%mongo%';
3.3.10开头匹配
- db.user.find({name: /^mongo/});
- # 与SQL中得like语法类似
- select * from user where name like 'mongo%';
3.3.11指定列查询
- db.user.find({}, {name: 1, age: 1});
- #相当于:
- select name, age from user;
当然name也可以用true或false,当用ture的情况下和name:1效果一样,如果用false就是排除name,显示name以外的列信息。
3.3.12指定列查询+条件查询
- db.user.find({age: {$gt: 25}}, {name: 1, age: 1});
- #相当于:
- select name, age from user where age > 25;
- db.user.find({name: 'zhangsan', age: 22});
- #相当于:
- select * from user where name = 'zhangsan' and age = 22;
3.3.13排序
- #升序:
- db.user.find().sort({age: 1});
- #降序:
- db.user.find().sort({age: -1});
3.3.14查询5条数据
- db.user.find().limit(5);
- #相当于:
- select * from user limit 5;
3.3.15N条以后数据
- db.user.find().skip(10);
- #相当于:
- select * from user where id not in ( select * from user limit 5 );
3.3.16在一定区域内查询记录
- #查询在5~10之间的数据
- db.user.find().limit(10).skip(5);
可用于分页,limit是pageSize,skip是第几页*pageSize。
3.3.17COUNT
- db.user.find({age: {$gte: 25}}).count();
- #相当于:
- select count(*) from user where age >= 20;
3.3.18安装结果集排序
- db.userInfo.find({sex: {$exists: true}}).sort();
3.3.19不等于NULL
- db.user.find({sex: {$ne: null}})
- #相当于:
- select * from user where sex not null;
3.4索引
创建索引,并指定主键字段,命令内容如下所示:
- db.epd_favorites_folder.ensureIndex({"id":1},{"unique":true,"dropDups":true})
- db.epd_focus.ensureIndex({"id":1},{"unique":true,"dropDups":true})
3.5更新
update命令格式,如下所示:
- db.collection.update(criteria,objNew,upsert,multi)
参数说明: criteria:
查询条件 objNew:update对象和一些更新操作符
upsert:如果不存在update的记录,是否插入objNew这个新的文档,true为插入,默认为false,不插入。
multi:默认是false,只更新找到的第一条记录。如果为true,把按条件查询出来的记录全部更新。
下面给出一个示例,更新id为 1 中 price 的值,内容如下所示:
- db. user.update({id: 1},{$set:{price:2}});
- #相当于:
- update user set price=2 where id=1;
3.6删除
3.6.1删除指定记录
- db. user. remove( { id:1 } );
- #相当于:
- delete from user where id=1;
3.6.2删除所有记录
- db. user. remove( { } );
- #相当于:
- delete from user;
3.6.3DROP
- db. user. drop();
- #相当于:
- drop table user;
4.MapReduce
MongoDB中的 MapReduce 是编写JavaScript脚本,然后由MongoDB去解析执行对应的脚本,下面给出 Java API 操作MR。代码如下所示:
MongdbManager类,用来初始化MongoDB:
- package cn.mongo.util;
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
- import com.mongodb.DB;
- import com.mongodb.Mongo;
- import com.mongodb.MongoOptions;
- /**
- * @Date Mar 3, 2015
- *
- * @author dengjie
- *
- * @Note mongodb manager
- */
- public class MongdbManager {
- private static final Logger logger = LoggerFactory.getLogger(MongdbManager.class);
- private static Mongo mongo = null;
- private static String tag = SystemConfig.getProperty("dev.tag");
- private MongdbManager() {
- }
- static {
- initClient();
- }
- // get DB object
- public static DB getDB(String dbName) {
- return mongo.getDB(dbName);
- }
- // get DB object without param
- public static DB getDB() {
- String dbName = SystemConfig.getProperty(String.format("%s.mongodb.dbname", tag));
- return mongo.getDB(dbName);
- }
- // init mongodb pool
- private static void initClient() {
- try {
- String[] hosts = SystemConfig.getProperty(String.format("%s.mongodb.host", tag)).split(",");
- for (int i = 0; i < hosts.length; i++) {
- try {
- String host = hosts[i].split(":")[0];
- int port = Integer.parseInt(hosts[i].split(":")[1]);
- mongo = new Mongo(host, port);
- if (mongo.getDatabaseNames().size() > 0) {
- logger.info(String.format("connection success,host=[%s],port=[%d]", host, port));
- break;
- }
- } catch (Exception ex) {
- ex.printStackTrace();
- logger.error(String.format("create connection has error,msg is %s", ex.getMessage()));
- }
- }
- // 设置连接池的信息
- MongoOptions opt = mongo.getMongoOptions();
- opt.connectionsPerHost = SystemConfig.getIntProperty(String.format("%s.mongodb.poolsize", tag));// poolsize
- opt.threadsAllowedToBlockForConnectionMultiplier = SystemConfig.getIntProperty(String.format(
- "%s.mongodb.blocksize", tag));// blocksize
- opt.socketKeepAlive = true;
- opt.autoConnectRetry = true;
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- }
MongoDBFactory类,用来封装操作业务代码,具体内容如下所示:
- package cn.mongo.util;
- import java.util.ArrayList;
- import java.util.List;
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
- import cn.diexun.domain.MGDCustomerSchema;
- import com.mongodb.BasicDBList;
- import com.mongodb.DB;
- import com.mongodb.DBCollection;
- import com.mongodb.DBObject;
- import com.mongodb.util.JSON;
- /**
- * @Date Mar 3, 2015
- *
- * @Author dengjie
- */
- public class MongoDBFactory {
- private static Logger logger = LoggerFactory.getLogger(MongoDBFactory.class);
- // save data to mongodb
- public static void save(MGDCustomerSchema mgs, String collName) {
- DB db = null;
- try {
- db = MongdbManager.getDB();
- DBCollection coll = db.getCollection(collName);
- DBObject dbo = (DBObject) JSON.parse(mgs.toString());
- coll.insert(dbo);
- } catch (Exception ex) {
- ex.printStackTrace();
- logger.error(String.format("save object to mongodb has error,msg is %s", ex.getMessage()));
- } finally {
- if (db != null) {
- db.requestDone();
- db = null;
- }
- }
- }
- // batch insert
- public static void save(List<?> mgsList, String collName) {
- DB db = null;
- try {
- db = MongdbManager.getDB();
- DBCollection coll = db.getCollection(collName);
- BasicDBList data = (BasicDBList) JSON.parse(mgsList.toString());
- List<DBObject> list = new ArrayList<DBObject>();
- int commitSize = SystemConfig.getIntProperty("mongo.commit.size");
- int rowCount = 0;
- long start = System.currentTimeMillis();
- for (Object dbo : data) {
- rowCount++;
- list.add((DBObject) dbo);
- if (rowCount % commitSize == 0) {
- try {
- coll.insert(list);
- list.clear();
- logger.info(String.format("current commit rowCount = [%d],commit spent time = [%s]s", rowCount,
- (System.currentTimeMillis() - start) / 1000.0));
- } catch (Exception ex) {
- ex.printStackTrace();
- logger.error(String.format("batch commit data to mongodb has error,msg is %s", ex.getMessage()));
- }
- }
- }
- if (rowCount % commitSize != 0) {
- try {
- coll.insert(list);
- logger.info(String.format("insert data to mongo has spent total time = [%s]s",
- (System.currentTimeMillis() - start) / 1000.0));
- } catch (Exception ex) {
- ex.printStackTrace();
- logger.error(String.format("commit end has error,msg is %s", ex.getMessage()));
- }
- }
- } catch (Exception ex) {
- ex.printStackTrace();
- logger.error(String.format("save object list to mongodb has error,msg is %s", ex.getMessage()));
- } finally {
- if (db != null) {
- db.requestDone();
- db = null;
- }
- }
- }
- }
LoginerAmountMR类,这是一个统计登录用户数的MapReduce计算类,代码如下:
- package cn.mongo.mapreduce;
- import java.sql.Timestamp;
- import java.util.ArrayList;
- import java.util.Date;
- import java.util.List;
- import org.bson.BSONObject;
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
- import cn.diexun.conf.ConfigureAPI.MR;
- import cn.diexun.conf.ConfigureAPI.PRECISION;
- import cn.diexun.domain.Kpi;
- import cn.diexun.util.CalendarUtil;
- import cn.diexun.util.MongdbManager;
- import cn.diexun.util.MysqlFactory;
- import com.mongodb.DB;
- import com.mongodb.DBCollection;
- import com.mongodb.DBCursor;
- import com.mongodb.DBObject;
- import com.mongodb.MapReduceOutput;
- import com.mongodb.ReadPreference;
- /**
- * @Date Mar 13, 2015
- *
- * @Author dengjie
- *
- * @Note use mr jobs stats user login amount
- */
- public class LoginerAmountMR {
- private static Logger logger = LoggerFactory.getLogger(LoginerAmountMR.class);
- // map 函数JS字符串拼接
- private static String map() {
- String map = "function(){";
- map += "if(this.userName != \"\"){";
- map += "emit({" + "kpi_code:'login_times',username:this.userName,"
- + "district_id:this.districtId,product_style:this.product_style,"
- + "customer_property:this.customer_property},{count:1});";
- map += "}";
- map += "}";
- return map;
- }
- private static String reduce() {
- String reduce = "function(key,values){";
- reduce += "var total = 0;";
- reduce += "for(var i=0;i<values.length;i++){";
- reduce += "total += values[i].count;}";
- reduce += "return {count:total};";
- reduce += "}";
- return reduce;
- }
- // reduce 函数字符串拼接
- public static void main(String[] args) {
- loginNumbers("t_login_20150312");
- }
- /**
- * login user amount
- *
- * @param collName
- */
- public static void loginNumbers(String collName) {
- DB db = null;
- try {
- db = MongdbManager.getDB();
- db.setReadPreference(ReadPreference.secondaryPreferred());
- DBCollection coll = db.getCollection(collName);
- String result = MR.COLLNAME_TMP;
- long start = System.currentTimeMillis();
- MapReduceOutput mapRed = coll.mapReduce(map(), reduce(), result, null);
- logger.info(String.format("mr run spent time=%ss", (System.currentTimeMillis() - start) / 1000.0));
- start = System.currentTimeMillis();
- DBCursor cursor = mapRed.getOutputCollection().find();
- List<Kpi> list = new ArrayList<Kpi>();
- while (cursor.hasNext()) {
- DBObject obj = cursor.next();
- BSONObject key = (BSONObject) obj.get("_id");
- BSONObject value = (BSONObject) obj.get("value");
- Object kpiValue = value.get("count");
- Object userName = key.get("username");
- Object districtId = key.get("district_id");
- Object customerProperty = key.get("customer_property");
- Object productStyle = key.get("product_style");
- Kpi kpi = new Kpi();
- try {
- kpi.setUserName(userName == null ? "" : userName.toString());
- kpi.setKpiCode(key.get("kpi_code").toString());
- kpi.setKpiValue(Math.round(Double.parseDouble(kpiValue.toString())));
- kpi.setCustomerProperty(customerProperty == null ? "" : customerProperty.toString());
- kpi.setDistrictId(districtId == "" ? 0 : Integer.parseInt(districtId.toString()));
- kpi.setProductStyle(productStyle == null ? "" : productStyle.toString());
- kpi.setCreateDate(collName.split("_")[2]);
- kpi.setUpdateDate(Timestamp.valueOf(CalendarUtil.formatMap.get(PRECISION.HOUR).format(new Date())));
- list.add(kpi);
- } catch (Exception exx) {
- exx.printStackTrace();
- logger.error(String.format("parse type or get value has error,msg is %s", exx.getMessage()));
- }
- }
- MysqlFactory.insert(list);
- logger.info(String.format("store mysql spent time is %ss", (System.currentTimeMillis() - start) / 1000.0));
- } catch (Exception ex) {
- ex.printStackTrace();
- logger.error(String.format("run map-reduce jobs has error,msg is %s", ex.getMessage()));
- } finally {
- if (db != null) {
- db.requestDone();
- db = null;
- }
- }
- }
- }
5.总结
在计算 MongoDB 的MapReduce计算的时候,拼接JavaScript字符串时需要谨慎小心,很容易出错,上面给出的代码只是一部分代码,供参考学习使用;另外,若是要做MapReduce任务计算,推荐使用Hadoop的MapReduce计算框架,MongoDB的MapReduce框架这里仅做介绍学习了解。
本文作者:佚名
来源:51CTO