equals和hashCode网上也有很多的资料。这里只是记录下我目前的理解与认识。
大家会经常听到这样的话,当你重写equals方法时,尽量要重写hashCode方法,有些人却并不知道为什么要这样,待会就会给出源码说明这个原因。
首先来介绍下Object的equals和hashCode方法。如下:
|
1 2 3 4 |
|
这里挺简单的,equals(obj)默认比较的是内存地址,hashCode()方法默认是native方法,看下它的文档说明:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
|
这里有三个关注点。
关注点1:主要是说这个hashCode方法对哪些类是有用的,并不是任何情况下都要使用这个方法(此时是根本没有必要来复写此方法),而是当你涉及到像HashMap、HashSet(他们的内部实现中使用到了hashCode方法)等与hash有关的一些类时,才会使用到hashCode方法。
关注点2:推荐按照这样的原则来设计,即当equals(object)相同时,hashCode()的返回值也要尽量相同,当equals(object)不相同时,hashCode()的返回没有特别的要求,但是也是尽量不相同以获取好的性能。
关注点3:默认的hashCode实现一般是内存地址对应的数字,所以不同的对象,hashCode()的返回值是不一样的。
java世界里的相同:
如Person类,含有name和age属性:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
|
我们认为当name和age值都相同时就是一个相同的person,所以我们可以重写equals方法如上所述,这样我们就可以调用perosn1.equals(person2)来判断他们是否相同。然而这样就完了吗?如果你不涉及其他有关hash方面的内容,这样的确可以满足你的需求了,也就是说这样做仅仅是针对部分情况是可以的,并没有针对全部情况,如若使用HashMap、HashSet等还想实现person1和person2相同,仅仅重写equals方法肯定是不够的,必须要重写hashCode方法。
为什么会有Hash类型的Map?
简单理解:Map本身是存放key和value信息的地方,若想获取某个key1对应的value,即map.get(key1),常规思维就是拿key1和所有的key一个一个去比较,若相同,则返回对应的value。假如有10000个key,要比较10000次吗?这样的效率难道不是很低下的吗?所以要改进,假如我们对key1进行某种运算直接能得到对应value的存储位置,来直接获取到value,这样不是最爽的吗?不再和其他key进行比较了,而是得到位置,直接获取对应的value。这就是HashMap等的基本原理,同时hashCode方法在得到位置信息上发挥着巨大的作用。
接下来HashMap的源码分析这一具体过程:
|
1 2 |
|
HashMap内部是由Entry<K,V>类型的数组table来存储数据的。来看下Entry<K,V>的代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
Entry<K,V>有四个重要的属性,是一对key和value的结合,同时包含下一个Entry<K,V>,就像链表一样,最后一个就是哈希值h(这个哈希值就是key的hashCode方法的返回值经过hash运算得到的值)。
所以我们可以画出HashMap的存储结构:
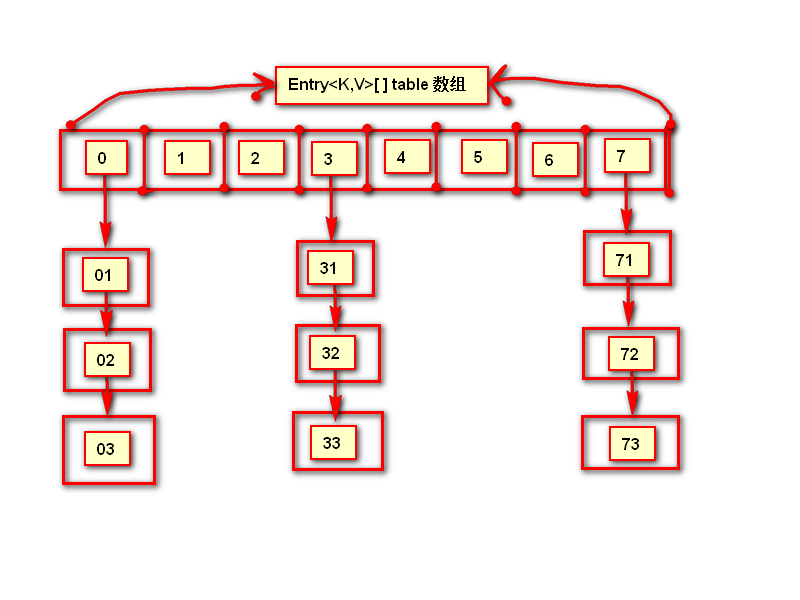
图中的每一个方格就表示一个Entry<K,V>对象,其中的横向则构成一个Entry<K,V>[] table数组,而竖向则是由Entry<K,V>的next属性形成的链表。
假入我们想找编号为2的value,如果我们能直接找到它所在数组中的索引便可以快速找到它,假如我们想找编号为73的value,如果我们能直接找到编号7然后再继续沿着链表寻找,便可以快速找到它。
首先看下它HashMap是如何来添加的,即 put(K key, V value)方法:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
现在先不管HashMap扩容的事情,我们重点关注它的存的过程,首先就是计算key的hash值,这个hash计算的过程便用到了key对象的hashCode方法,如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
先不用看懂这个方法是怎么计算的,它的内容就是对key的hashCode方法返回值进行一系列的运算得到一个最终的值,这个值就是hash值,就是上文所说的Entry<K,V>中的h属性的值。
得到这个hash值后,紧接着执行了int i = indexFor(hash, table.length);就是找到这个hash值在table数组中的索引值,具体方法indexFor(hash, table.length)为:
|
1 2 3 |
|
就是拿刚才生成的hash值和(table数组的长度减一)进行了相&操作,可以看到我们得到的hash值是一个很大很大的数字,和length-1相&之后的值,必然是在0到length-1之内,即在table数组的范围之内。得到的这个索引之后,接下来针对这个索引值对应的链表便进行放入或者替换操作。遍历这个链表,拿要放进来的key和这个链表上的每一对象的key进行下对比,看是否一致,若一致则进行替换操作,若都不一致则进行新的插入操作。
判断是否一致的条件是:e.hash == hash && ((k = e.key) == key || key.equals(k)),一定要牢牢记住这个条件。
必须满足的条件1:hash值一样,hash值的来历就是根据key的hashCode再进行一个复杂的运算,当两个key的hashCode一致的时候,计算出来的hash也是必然一样的。
必须满足的条件2:两个key的引用一样或者equals相同。
综上所述,HashMap对于key的重复性判断是基于两个内容的判断,一个就是hash值是否一样(会演变成key的hashCode是否一样),另一个就是equals方法是否一样(引用一样则肯定一样)。它依据的是两个条件,所以对于上文的Person类,若想在HashMap中以person对象作为key,要满足person1对象和person2对象一样,则我们必须要重写equals方法和hashCode方法。若没有重写hashCode方法,则使用系统默认的本地hashCode方法,不同的对象的hashCode是不一样的,所以HashMap在判断时就会认为person1和person2是不一样,造成了我们事与愿违的结果。
HashMap为什么要多引入key的hash是否一致的判断条件呢?为什么不仅仅判断equals方法是否一样?
我认为原因如下
好处1:当这个table数组特别大的时候,如长度为10000,根据hash&length-1这个计算的索引值,便很快的定位某一个链表下,过滤了很大一批数据,不需要一个一个遍历。仅仅依靠equals是无法实现这样的快速过滤的。
好处2:不同的hash值得出的索引位置很可能是一样的,所以在这个链表下仍要进一步判断,此时就需要一个一个进行遍历。Entry<K,V>对象中hash值是已经保存的数据,新的key的hash也已经计算出来,所以在遍历对比的过程中判断hash值是否一致是相当快的,如果不一致,则认为不相同继续下一个判断,就不会调用费时的equals方法。假如这个链表的数据也特别多,判断过程也是相当快的。也就是说,判断hash是否一致加快了在链表上的遍历的速度,减少了相对费时的equals调用次数。
综上所述,为了实现HashMap的上述高效的存储操作,引入了hash这个重要的东西。同时带给我们的附加操作就是要满足key一致除了equals返回true外,还必须让hashCode一样。所以我们重写equals方法的时候尽量的重写hashCode方法,当用到HashMap或者HashSet等时必须要重写hashCode方法。
hashCode的重写的原则:当equals方法返回true,则两个对象的hashCode必须一样。
如String、Integer等类都重写了equals方法和hashCode方法,都是遵循上述原则。所以我们在重写hashCode时也要遵循上述原则。
接下来看下get(Object key)源代码的具体寻找过程:
|
1 2 3 4 5 6 7 |
|
就是找到对应key的Entry<K,V>对象,有了这个对象我们便可以获取到value。继续看下是如何来找到key对应的Entry<K,V>对象的:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
看到这里就会明白了这个过程,和上面put的过程类似的。
hash&length-1结果相同我们称为冲突
同时要思考什么样的情况下,get(key)过程是最快的?当然是hash&length-1的结果所在的数组索引下只有一个对象,还没有其他对象插入进来。也就是当所有的数据均匀分布在table上,而不是集中在table某个索引对应的连表上的时候此时get操作的效率是相当高的,为了达到这一个操作,就是要满足hash&length-1要尽可能的不同,减少冲突。
首先看length-1:它的原因是因为要限制在table数组内,同时还有一个重要的作用就是减少冲突。首先要知道length的长度是2的幂级数,这个是HashMap来保证的,下一篇文章再说HashMap的大小及扩容。假如length为7,3&(7-1) 即二进制的11&110等于10,2&(7-1),即二进制的10&110即10,这就是说2和3这两个值不一样,却造成了一样的索引值,即产生了冲突,当length=8时,11&111为11,10&111为10所以避免了冲突。所以当length-1的二进制为全1时,会起到避免冲突的作用。
接着看hash值,hash值是由key的hashCode经过hash运算得到的,为了让hash&length-1的结果尽量不产生冲突,hash的值也要尽量均匀,这就对hash算法提出了很高的要求,一个好的hash算法,会让不同的hashCode计算出来的hash值更加均匀分布。hash算法不在本文的范围之内,感兴趣的可以去研究。
接下来顺便看看HashSet的原理:
Set与List相比是无序的,不允许元素重复。元素重复的依据和HashMap对key的要求是一样的。即所存元素的hash值一样并且equals相同才是一样的元素。看下代码:
|
1 2 3 |
|
看到了没有,HashSet内部是有一个HashMap的,这个key就是HashSet的元素,而value始终是一个固定的值PRESENT。
看下HashSet的add方法:
|
1 2 3 |
|
看到没有,HashSet就是依托HashMap中的key不能重复来实现HashSet中自身的元素不能重复的。
下一篇文章就要讲讲HashMap的扩容。