用户模型(Persona)是Alan Cooper在《About Face:交互设计精髓》一书中提到的研究用户的系统化方法。它是产品经理、交互设计师了解用户目标和需求、与开发团队及相关人交流、避免设计陷阱的重要工具。
但在现实中,一般只有很少的成熟公司,产品经理、交互设计师或用户研究人员才会花时间构建用户模型,个人认为之所以这样,至少包含两方面原因:
一个主要原因在于,按照传统方法构建用户模型的成本高、时间长,不是一般公司和团队所能承受的;
另一个原因在于,传统方法对用户模型构建者的要求很高,尤其是对用户的访谈和观察,其中有很多的方法和技巧,不少产品经理不敢尝试,有些人尝试后并没有得到有用的信息,后面往往就不再做了。
本文将尝试提出一种基于用户行为数据的快速构建用户模型的方法。
用户模型构建的传统方法
Alan Cooper提出了两种构建用户模型的方法:
用户模型:基于对用户的访谈和观察等研究结果建立,严谨可靠但费时;
临时用户模型(ad hoc persona):基于行业专家或市场调查数据对用户的理解建立,快速但容易有偏颇。
方法1:基于访谈和观察的构建用户模型(正统方法)
在Alan Cooper的方法中,对用户的访谈和观察是构建用户模型的重要基础。完整步骤如下图:
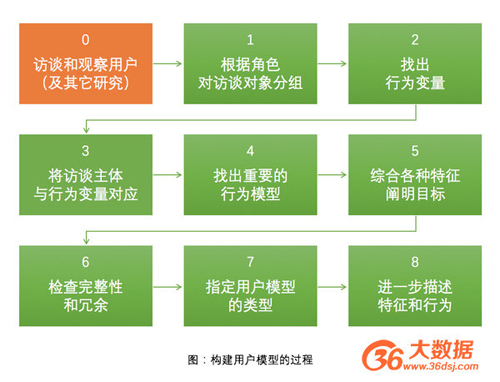
第0步:对用户的访谈和观察(及其他研究)。将用户当成师傅,自己作为徒弟去观察师傅的行为,并提出问题。在整个过程中收集并研究用户行为、环境、谈话内容等信息,以发现用户的行为、情境和目标。(比如,某儿童社区的用户角色大致分为孩子、妈妈、爸爸和祖辈等四类,需要分别研究)
第1步:根据角色对访谈对象进行分组。根据研究结果和理解对用户进行大致的角色划分,并根据角色对要访谈的用户进行分组。
第2步:找出行为变量。把每种角色的显著行为列成几组行为变量。一般包括用户的活动(行为及频率)、(对产品及相关技术的)态度、能力、动机、技能几个方面。
第3步:将访谈主体和行为变量对应起来。实际上就是为每个访谈用户标注各项行为的情况。
第4步:找出重要的行为模型。发现访谈用户中的中的显著的行为模式组合。(比如儿童社区产品的「某些家长」会「密切关注」孩子在社区中的一举一动,而「另一些家长」则只是「偶尔了解」一下孩子的情况)
第5步:综合各种特征,阐明目标。从用户模型的行为细节中综合/挖掘出用户的目标和其他特性。
第6步:检查完整性和冗余。为每种用户模型弥补行为特征中重要的缺漏,将行为模式相同而仅仅是人口统计数据有差异的用户模型合并为一个。
第7步:指定用户模型的类型。对用户模型进行优先级排序,确定主要、次要、补充和负面用户模型。主要用户模型是界面设计的主要对象,一个产品的一个界面,只能有一个主要用户模型。
第8步:进一步描述特征和行为。通过第三人称叙述的方式描述用户模型,并为不同用户模型选择恰当的照片。至此,用户模型构建完成。
方法2:构建临时用户模型(ad hoc persona)
在缺乏时间、资源不能做对用户的访谈和观察时,可以基于行业专家对用户的理解、或市场研究中获得的人口统计数据,建立「临时用户模型」。
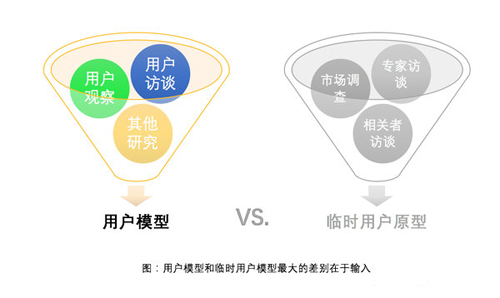
「临时用户模型」的构建过程与「用户模型」的构建过程很像,只是其数据基础一个是来自对真实用户的访谈和观察,另一个是来自对用户的理解。二者的准确度和精度都有差别。
基于用户行为数据快速、迭代构建用户模型的方法
到现在,距离Alan Cooper首次提出用户模型(Persona)概念已经过去快20年了。在这期间,软件产品开发的过程方法以及公司的运作方式都发生了很大改变:以快速迭代为特点的敏捷开发方法取代了传统的瀑布模型,以「开发→测量→认知」反馈循环为核心的精益创业方法在逐步影响和改变公司的运作方式……
而传统的用户模型构建方法,从诞生之日起并未发生特别大的变化。对于已经习惯了敏捷、快速的产品经理和交互设计师来说:一方面,花很长时间去研究用户构建用户模型需要下相当大的决心、更需要下很大力气才能争取到所需的时间和资源;另一方面,互联网产品冷启动耗费的时间越来越短,为了降低成本和风险,产品团队在启动期往往会选择尽快将产品推向用户,尽快获得反馈以「快速试错」,现实和压力迫使大多数新产品的PM不敢投入大量时间精力深入的进行用户研究。这就很容易理解,为什么大家都觉得用户模型很好,却鲜有人在工作中真正运用它。
接下来,我们将提出一种基于用户行为数据的快速、迭代构建用户模型的轻量方法。
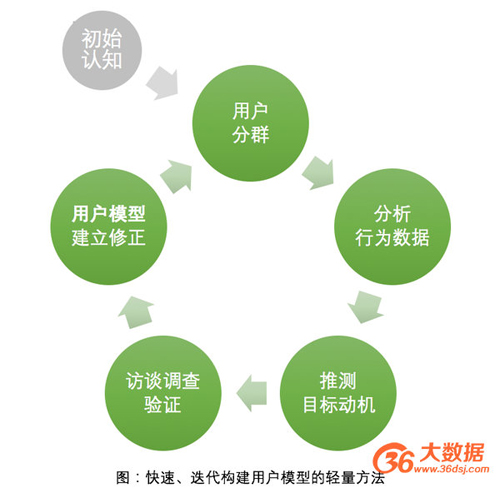
首先,在开始时,整理和收集已经获得的任何对用户的认知、经验和数据。
它们可能是您和所在团队对用户的理解,也可能是您产品的业务数据库中记录的用户相关信息(比如用户的性别、年龄、等级等属性),还可能是用户(在产品内外)填写的任何表单或留下来的信息(比如用户填写的调查问卷、留下的微信账号等等)。

您可以将这些信息映射成为用户的描述信息(属性)或用户的行为信息,并存储起来形成用户档案(最终形成的结果如下图示意)。
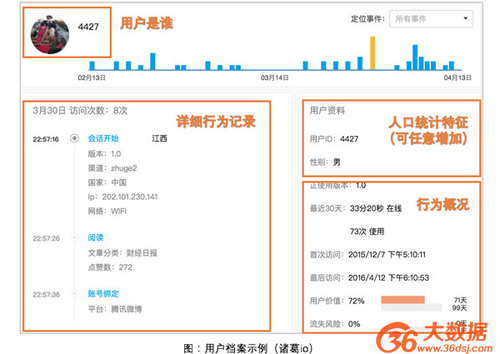
注意:从这一步开始,你就需要一个存储了用户信息和用户行为信息的数据库系统,它能够支持你快速的进行接下来的各种分析和探索,直至形成用户模型。如果您团队的技术人员没有时间为您搭建这样的系统,您可以考虑引入类似于诸葛io这样的分析工具,它可以帮您存储用户及行为数据,以方便查询使用,您还可以在您的App或网站中集成诸葛io的SDK,方便的记录用户的行为数据。
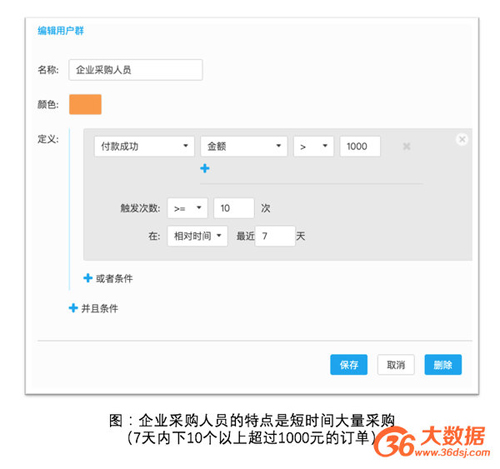
然后,根据已获得的认知和经验对用户分群,这些用户群是进一步研究的基础。比如,你觉得用户也许可以分为孩子、妈妈、爸爸和祖辈等四类,或者你认为购物的用户可以分为男女两类,那就根据数据划分好了。如果在诸葛io中,您可以通过定义用户群实现(如下图)。

接下来,您就要对上一步的用户群逐个进行分析,并尝试从中发现显著的行为模式。
对于每个用户群,分析步骤如下:
从用户群中随机选取一些用户(一般根据您的时间情况,可以选取几十到上百个用户,建议最少不低于30个);
逐个用户解读其属性特征和行为记录,努力通过这些数据还原出用户的真实使用场景和过程,并尝试推测其目标。在解读的同时,随时记录你发现的有趣的行为模式、以及不解之处。(注意,这一步的工作至关重要,对用户及其行为的感性认识是后续工作的基础。要记住:读用户如读书,读其百遍、其义自现!)

根据上面步骤中发现的典型行为模式和场景、目标的推测,对用户群进行更细致的划分。比如,你发现一些用户会定期采购大量的办公用品(有趣的行为模式),并推测这些人可能是企业行政部门的采购人员,他们要根据其他员工的需求定期完成采购任务(场景和目标),那么你就可以将这群人划分出来,作为一个单独的用户群(候选的用户模型),进行后续的研究。(如下图示例)
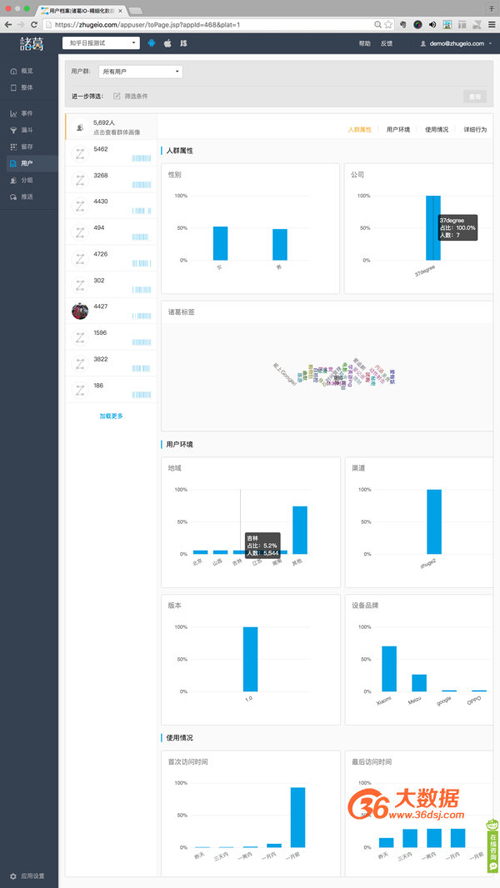
对上一步形成的候选用户模型(用户群),对其属性和行为数据进行统计分析,初步验证您的猜想。(如果使用诸葛io,您可以通过用户群的「群体画像」、「行为(事件)概览」等功能快速完成所需分析,如下图所示)
接下来,对上面形成的每个候选用户模型,进一步完成其目标和动机的推测。同样,在过程中有任何不解之处,请记录下来。
从每个用户模型中选取少量具有代表性的用户,进行访谈或调查,以消除您在前面研究中遇到的不解之处。在这一步,如果您有足够的时间和资源,那么可以多选一些用户,并尽可能的做现场的访谈和观察;如果您时间和资源有限,那么可以少选一些用户,或者采用电话、问卷等方式完成访谈,对于配合度较高的用户,可以考虑采用录屏或QQ远程协助之类的工具观察用户的真实行为。因为您在前面的步骤中已经对用户的真实行为有了一定的了解,所以在这一步,您可以不必严格的执行Alan Cooper的用户研究方法,从而节省大量的时间和资源。但是,如非特殊情况,请尽量不要跳过这一步。记住:哪怕是与用户进行很少量的沟通,也有助于发现未知的问题,这是非常值得的。
在完成了上面的工作之后,接下来,您就可以对候选用户模型进行逐个的审视和修正。 合并相似的,补充不完整的,采用叙述的方式描述每个用户模型,并为其选择适当的照片,这样就得到了本次迭代的用户模型(如下图示例,图片来自网络)。您可以用这个模型指导界面设计、与团队沟通……

最后,根据您的认知变化和产品需要,可以在合适的时机对之前得到的模型进行新一轮的修正。 修正的过程和前面相同,可能您会在几次产品迭代中穿插进行一轮用户模型的迭代,时间越久,用户模型就越接近真实的用户情况。
小结
本文提供了一种借助行为数据和工具快速、迭代的构建用户模型(Persona)的方法,这套方法与传统的用户模型构建方法相比损失了一定的质量但效率更高,更适合今天的互联网团队的工作方式和节奏。
本文作者:于晓松
来源:51CTO