爬取了上海摩拜单车的数据,把所有单车叠到图上,变出一幅满城星光的地图,统计上看,深夜时分,大部分的单车分布在路的周边,勾勒出一幅泾渭分明的街道景象,比如虹桥镇附近的小区,小区路边停了好多车,前簇后拥,形成了一条条道路的光带,而小区内部则基本不停车。

然而如果我们移步陆家嘴以北的小区,则发现大量分布散漫的自行车,他们都停在小区里。摩拜单车微信平台说明, 大院内部、单位内部、小区内部、建筑内部都算违章,要扣你信用分的。照理,作为浦西土著,我对浦东的印象就是五色盛景,满街都是惜时如金年薪百万的金领,为何这里违章停车那么多?

隐隐中,我想起了这些违停率很高的小区,记得某次爬到了大军刀的100楼往下看,浦东的壮观景象两边,也安插着许多低矮、屋顶花花绿绿的房子,看看地图,名字都是崂山五村,乳山二村云云的。
这些房子有个共同点,年代比较老,个头比较矮,面积比较小,屋顶比较花,他们生于“宁买浦西一张床,不买浦东一间房”的 pre 90年代,淹没在浦东崛起的建筑高度里。如果我们把居住区的建成年代做个可视化,立刻看到他们形成的2块大蓝斑了。


下班,从陆家嘴下车,骑车往几个x村去,细雨微朦的黑夜,云深不知处的高楼,然而过了世纪大道就画风一转,进入一个平行世界, 这里充满施工工地,路灯昏黄,道路不宽,周边都是非常平价的小店,虽然这些小区8w一平,其实里面道路拥堵,出口稀少。
当然,现实中这里没那么多违章停车,偶尔看到2、3成群的,我想道理也简单,再乱停车的小区,其比例也不高,1%的糖水和0.1%糖水你可能都觉得是淡水,但是他们差了10倍,人的感觉阈值决定了他两没区别,我们需要大数据才能看清这种分布。


为啥这一带的小区有那么多违规停车?万能的朋友圈说:
1、上班距离远(大多人在有距离的陆家嘴软件园工作,并非最近的金融单位,金领们多住世纪公园),自家楼下曝光率低,第二天不担心被骑走。
2、周边路窄,不便停车。
3、学区房小孩比例高,实拍如下

实地调研实在不是在下的强项,但如果我们把scale扩大,回到大数据的视角,将所有违章停车的数量,统计到小区里,一个违章停车的版图跃然纸上,其实,浦东的诸多小区并不是违章数很高的,最nb的小区,位于一个叫中远两湾城的巨型小区, 其数据(小区内违章停车绝对值)神一般的在众多小区里鹤立鸡群:
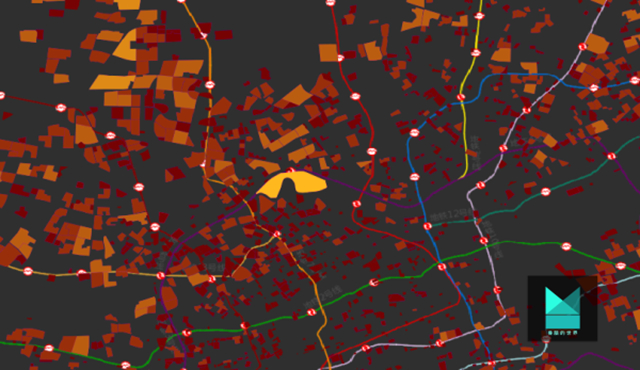
带着疑问,我驱车去了中远两湾城,作为巨无霸,这儿至少有几万人居住,这个粘附在苏州河大拐弯的小区,道路曲折而狭窄,两边停满了车,汽车在里面开着需要一条路走到黑,否则很难停下来,一楼某个窗户上,写着禁止群租房的字样: 这一直因为租房者众多而闻名。
总之,中远两湾城至少有2个问题:
1、小区太大,走出来非常费劲
2、楼高房间多,群租多人更多,年轻人比例高,人多停车自然多

作为总结,为什么小区违章停车多?
首先一个小区人多停车自然多,算违章停车数,大一点的小区很吃亏,好比富士康每年跳楼被媒体报道,很可能只是因为总人数多,不是本质的制度问题。
如果我们把违规停车数 / 小区户数(户数和人口正比)算违规停车率,即单位住户违停率,是否可以刻画一个合理的指标? 在这个指标下,中远两湾城这样的超级小区终于退出了老大的位置,但仍然存在2个问题:
1、人口结构不同,老年人压根是不骑车,年轻人多的小区违停率自然高
2、投放分布不同,张江、2号线、五角场、漕河泾投了很多自行车,这些地方共享单车用户数 / 周边人数 显然高。
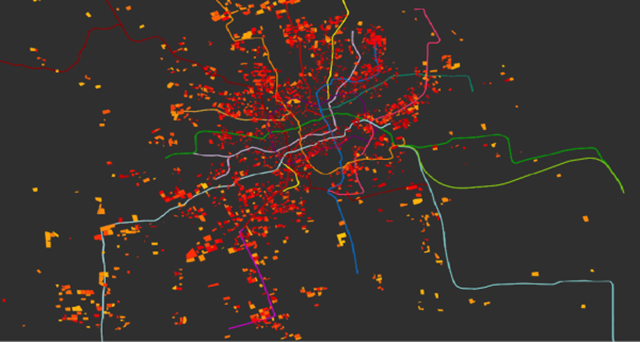
我想更接近附近住户的心理意愿的指标是骑车的小区住户平均违章停车了多少次,这个问题也简单,计算小区骑车的人数,假设骑车回家的人总归把车停在自己小区门口附近,只需要在一个晴天的晚上(一天天晴才保证正常的骑行) 看 小区内部停车数 / 小区附近50米包围圈内停车数:
一副远郊多而市区少的情景跃然纸上,越黄越违章,比如一号线的末端共富新村、彭浦新村,九号线的末端,松江城区,五号线的末端闵行南部,在这些pattern里,我们看到距离地铁较远的通常比较黄,比如松江新城周边,这些区域也通常在地铁的末端发生,按照常识,我想到了3个因素:
1、郊区小区很大,出门路太长容易违章停车
2、年轻人一直在向外迁移,目标用户比例高
3、郊区出行距离很长,车又很少,怕没车骑
据说单车公司目前就是通过停车是否在小区内停车和人的信用分绑定,所以本文基本也是从这个点出发的,但反过头来,为啥小区停车算违章?
我想,本质上是你的占有让公共资源发生了浪费。
如果你住在中原两湾城,小区本来就是一个小型社会,如果我们每个人遵守规则地把共享单车放在小区外,每天也许会增加 10分钟 * 2次 * 10000人的行走时间,加起来是138天,即便以20块钱/小时的时薪,也是一天6万块钱的cost。假设一种常见的场景,我晚上9点骑车回家,第二天早上8点出门,其实这几个小时停在小区里面也是合理的,毕竟放在外面基本也没人骑啊…,那我们对违规的判断是否应该继续细化呢,比如在小区里停车超过2天的同学算是违规。
手机、车辆也许只是所谓的物联网时代微小的开始,我们讨论简略的规则非常原始,然而yy一下,未来更多的物体长上了sensor传递着信号,未来我们的行为沉淀在云端的数据库进入计算,未来的计算机集群仍然沿着略低于摩尔定律的速度发生进化,未来城市治理也许对等于服务器上的规则引擎,这需要多么精密或巧妙的算法去取代今天城市治理者的劳动。

数据 爬取自摩拜单车、高德地图。
本文作者:周宁奕
来源:51CTO