
可能很多人理解的数据仓库就是基于多维数据模型构建,用于OLAP的数据平台,通过上一篇文章——数据仓库的基本架构,我们已经看到数据仓库的应用可能远不止这些。但不得不承认多维数据模型是数据仓库的一大特点,也是数据仓库应用和实现的一个重要的方面,通过在数据的组织和存储上的优化,使其更适用于分析型的数据查询和获取。
多维数据模型的定义和作用
多维数据模型是为了满足用户从多角度多层次进行数据查询和分析的需要而建立起来的基于事实和维的数据库模型,其基本的应用是为了实现OLAP(Online Analytical Processing)。
当然,通过多维数据模型的数据展示、查询和获取就是其作用的展现,但其真的作用的实现在于,通过数据仓库可以根据不同的数据需求建立起各类多维模型,并组成数据集市开放给不同的用户群体使用,也就是根据需求定制的各类数据商品摆放在数据集市中供不同的数据消费者进行采购。
多维数据模型实例
在看实例前,这里需要先了解两个概念:事实表和维表。事实表是用来记录具体事件的,包含了每个事件的具体要素,以及具体发生的事情;维表则是对事实表中事件的要素的描述信息。比如一个事件会包含时间、地点、人物、事件,事实表记录了整个事件的信息,但对时间、地点和人物等要素只记录了一些关键标记,比如事件的主角叫“Michael”,那么Michael到底“长什么样”,就需要到相应的维表里面去查询“Michael”的具体描述信息了。基于事实表和维表就可以构建出多种多维模型,包括星形模型、雪花模型和星座模型。这里不再展开了,解释概念真的很麻烦,而且基于我的理解的描述不一定所有人都能明白,还是直接上实例吧:
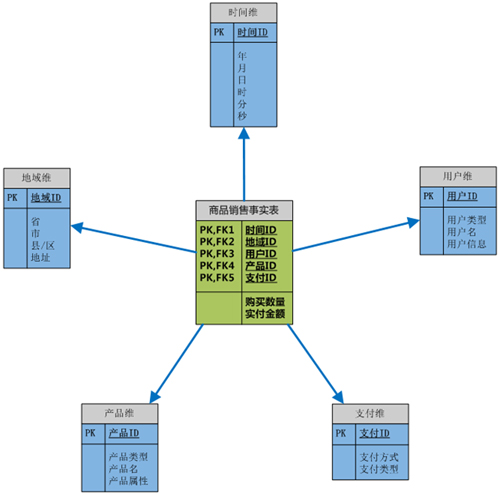
这是一个最简单的星形模型的实例。事实表里面主要包含两方面的信息:维和度量,维的具体描述信息记录在维表,事实表中的维属性只是一个关联到维表的键,并不记录具体信息;度量一般都会记录事件的相应数值,比如这里的产品的销售数量、销售额等。维表中的信息一般是可以分层的,比如时间维的年月日、地域维的省市县等,这类分层的信息就是为了满足事实表中的度量可以在不同的粒度上完成聚合,比如2010年商品的销售额,来自上海市的销售额等。
还有一点需要注意的是,维表的信息更新频率不高或者保持相对的稳定,例如一个已经建立的十年的时间维在短期是不需要更新的,地域维也是;但是事实表中的数据会不断地更新或增加,因为事件一直在不断地发生,用户在不断地购买商品、接受服务。
多维数据模型的优缺点
这里所说的多维模型是指基于关系数据库的多维数据模型,其与传统的关系模型相比有着自身的优缺点。
优点:
多维数据模型最大的优点就是其基于分析优化的数据组织和存储模式。举个简单的例子,电子商务网站的操作数据库中记录的可能是某个时间点,某个用户购买了某个商品,并寄送到某个具体的地址的这种记录的集合,于是我们无法马上获取2010年的7月份到底有多少用户购买了商品,或者2010年的7月份有多少的浙江省用户购买了商品?但是在基于多维模型的基础上,此类查询就变得简单了,只要在时间维上将数据聚合到2010年的7月份,同时在地域维上将数据聚合到浙江省的粒度就可以实现,这个就是OLAP的概念,之后会有相关的文章进行介绍。
缺点:
多维模型的缺点就是与关系模型相比其灵活性不够,一旦模型构建就很难进行更改。比如一个订单的事实,其中用户可能购买了多种商品,包括了时间、用户维和商品数量、总价等度量,对于关系模型而言如果我们进而需要区分订单中包含了哪些商品,我们只需要另外再建一张表记录订单号和商品的对应关系即可,但在多维模型里面一旦事实表构建起来后,我们无法将事实表中的一条订单记录再进行拆分,于是无法建立以一个新的维度——产品维,只能另外再建个以产品为主题的事实表。
所以,在建立多维模型之前,我们一般会根据需求首先详细的设计模型,应该包含哪些维和度量,应该让数据保持在哪个粒度上才能满足用户的分析需求。
本文作者:joeghwu
来源:51CTO